


**论文题目:**Can We Edit Multimodal Large Language Models? **本文作者:**程思源(浙江大学)、田博中(浙江大学)、刘庆斌(腾讯)、陈曦(腾讯)、王永恒(之江实验室)、陈华钧(浙江大学)、张宁豫(浙江大学) **发表会议:**EMNLP 2023 **论文链接:**https://arxiv.org/abs/2310.08475 ****代码链接:https://github.com/zjunlp/EasyEdit 欢迎转载,转载请注明出处
引言
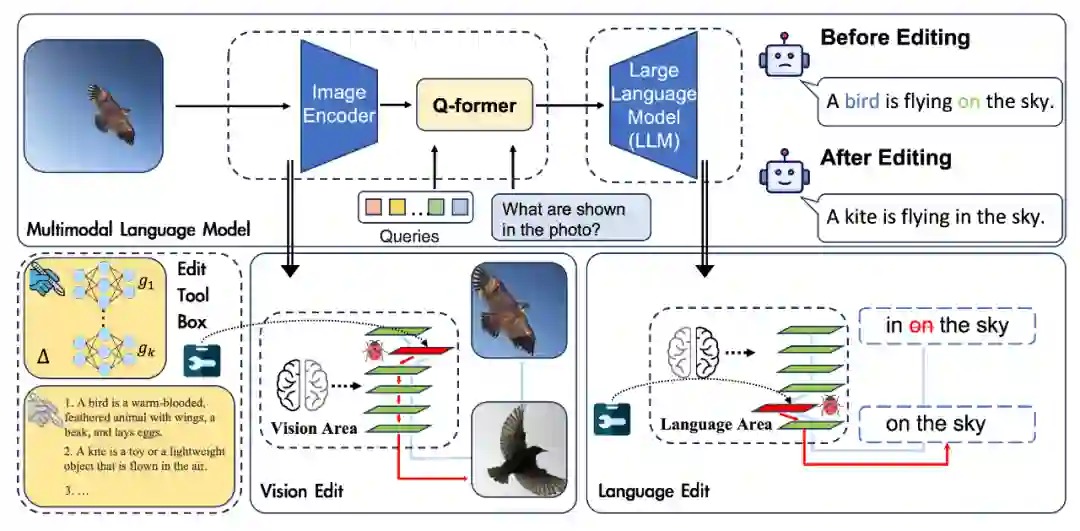
世界不但是文字的世界,我们生活的世界本质上是多模态的。我们需要不断处理和整合来自不同模态的信息,如视觉信息、听觉信息等,利用这些信息我们可以更好地与周围环境互动,提升认知世界的能力。随着OpenAI开放了ChatGPT的多模态功能,多模态大语言模型再一次成为了焦点。现有的主流多模态大语言模型框架是利用训练好的大语言模型和图像编码器,用一个图文特征对齐模块进行连接,从而让语言模型能够理解图像特征并进行更深层的问答推理。代表作有VisualGLM、BLIP 2和MiniGPT-4等。 但是目前复杂的多模态大语言模型都面临一个重大的挑战:对象幻觉(Object Hallucination)。就算是高质量的多模态语言模型,比如InstructBLIP,也存在高幻觉的文本率。多模态模型幻觉的主要原因可能有两点:1、多模态指令微调过程导致LVLMs 更容易在多模态指令数据集中频繁出现/共现的物体上产生幻觉;2、一些幻觉继承于原先的LLMs,由于使用的LLMs本来就存在一些错误/谬误知识,导致多模态语言模型也继承了这些错误知识,从而出现幻觉。 最近随着一种可以精确修改模型中特定知识的范式出现,对解决模型幻觉问题提供了一个新的可行性思路,这种方法被称作模型编辑。模型编辑可以在不重新训练模型的基础上,去修改模型的参数知识,这可以节约大量的资源。但是现有的模型编辑技术大部分都是针对单模态的,那多模态的模型是否是可编辑的呢?本文就是去探究编辑多模态大语言模型的可行性,作者构建了多模态语言模型知识编辑场景的benckmark,即设计了多模态模型编辑的指标和构建了相关数据集。并类比人类视觉问答场景,提出了编辑多模态语言模型的两种方式。其中多模态模型编辑的展示如下图所示:
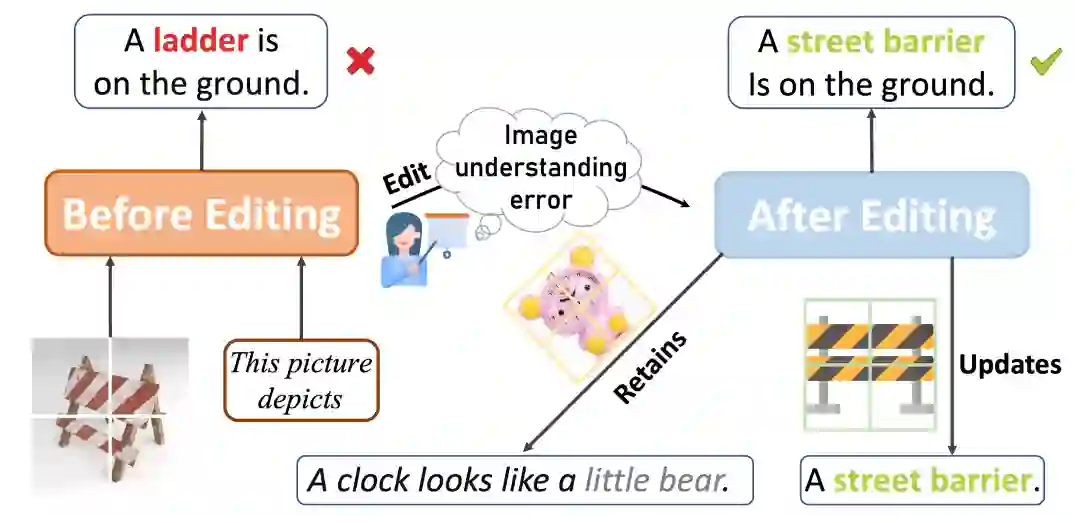
MMEdit
指标
不同于单模态模型编辑,多模态模型编辑需要考虑更多的模态信息。文章出发点依然从单模态模型编辑入手,将单模态模型编辑拓展到多模态模型编辑,主要从以下三个方面:可靠性(Reliability),稳定性(Locality)和泛化性(Generality)。 可靠性:模型编辑需要能够保证正确修改模型的知识,可靠性就是衡量编辑后模型的准确率。多模态模型编辑亦是如此,作者定义如下: 稳定性:稳定性是判别模型编辑影响模型其余知识的程度。模型编辑希望在编辑完相关知识过后,不影响模型中其余的一些知识。多模态模型编辑与单模态不同,由于我们需要编辑多个模型区域,所以我们需要判断多模态模型进行编辑之后到底是对哪部分产生的影响多,哪部分少。所以作者提出了两种稳定性测试:T-Locality和M-Locality,一个测试纯语言模型的稳定性,一个测试多模态整体模型的稳定性,其定义如下: 泛化性:编辑需要对一定编辑范围内的数据都要具有编辑效应,单模态模型编辑泛化性只考虑一种数据形式,即同义语义集合。多模态模型需要考虑更多模态数据,VLMs多增加了一个图片模态数据,所以作者提出两种泛化性指标: 数据集
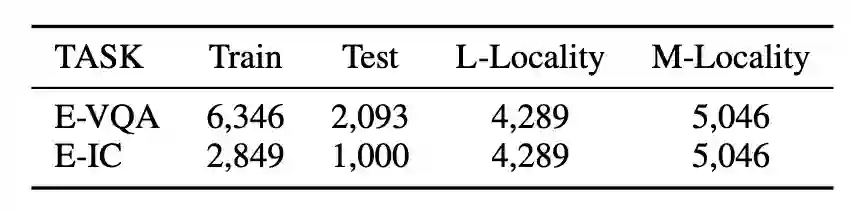
对于上述所有评估指标,本文作者都构造了对应的数据集来进行测试,其中针对可靠性数据集,作者收集了现有多模态大语言模型表现不佳的任务数据来作为编辑对象数据集,本文采用两个不同的多模态任务分别是VQA和Image Caption。并设计两种任务编辑数据集E-VQA和E-IC。 对于泛化性数据,多模态模型由于本身的数据也是多模态的,所以需要考虑更多模态的泛化数据情况。其中多模态泛化性数据例子如下:
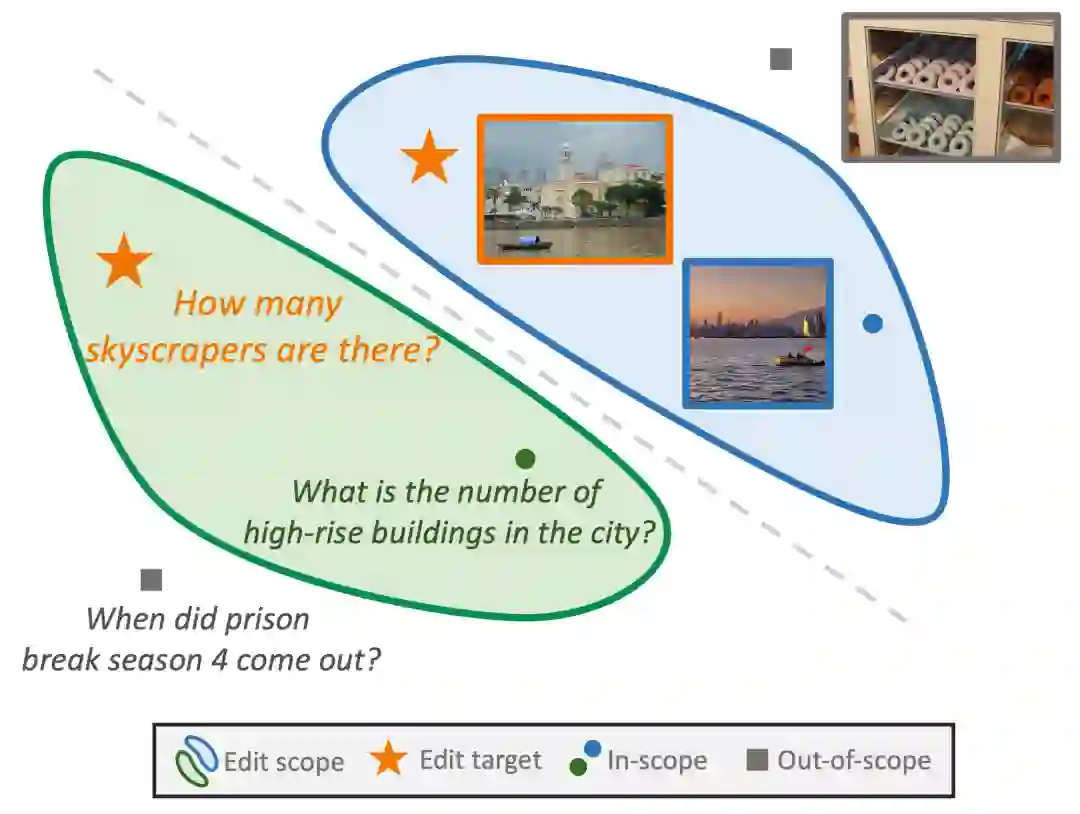
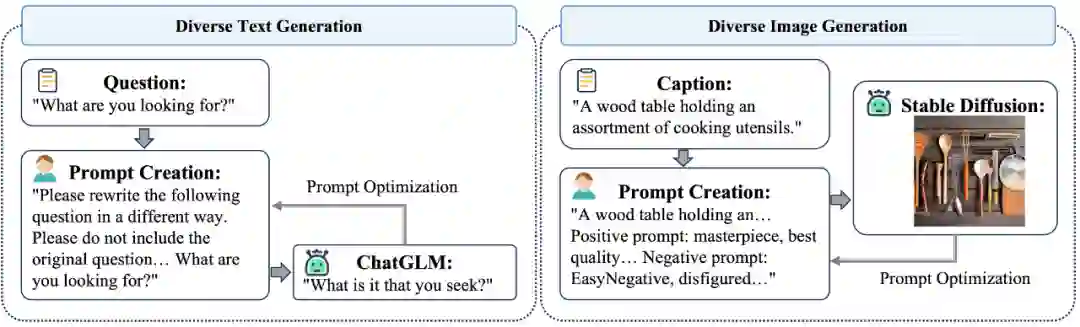
对文本数据,本文作者利用不同的方法构造相关泛化数据集。首先对于VQA数据,文章作者使用ChatGLM去生成文本类的泛化数据集,通过构造相关的prompt,让对话模型吐出相似句子。Image Caption任务由于其本身的数据比较简单,生成效果并不佳,所以作者人工构建了几十条相似文本数据,然后通过随机替换的方式作为Image Caption任务的泛化数据集。 然后对于图片数据,作者利用COCO数据集中提供的图片描述。通过现有效果非常不错的图片生成模型Stable Diffusion 2.1来生成与图片描述相似的图片。具体构造流程如下图所示:
对于稳定性数据集,作者为了考量编辑不同区域对模型的影响,所以将稳定性数据分为了Text Stability测试数据和Vision Stability测试数据。这部分数据不用构造,作者直接使用了之前的已有数据集。对于文本,沿用MEND中的NQ数据集,对于多模态数据,文章使用了多模态中比较简单的问答数据集OK-VQA作为测试数据集。 最后数据集统计如下:
多模态模型编辑
对于如何去编辑多模态语言模型,文章类比人类视觉问答场景出错场景,来设计多模态模型编辑实验。以VQA任务为例子,人类在做VQA题目时有两种出错的可能:
- 视觉出错:人类可能在图片识别这个阶段就出错,可能是看错,也有可能是视觉细胞本身就存在问题。例如人类色盲患者没有办法正确识别图片的颜色特征,就会在颜色识别的任务上出错。针对这个,文章作者提出了Vision Edit,针对VLMs的视觉模块进行编辑。
- 知识出错:人类可能正确识别了图片中的关键特征,但是本身的知识库里却没有相关特征的知识,这就导致人犯“指鹿为马”的失误。针对这个问题,作者提出了Language Edit,由于多模态语言模型的知识库都来自于LLMs,所以这部分编辑也就是针对语言模型。
多模态模型编辑的主要流程图作如下图所示:
实验
文章实验展示了现有主流的编辑方法在多模态大语言模型上的编辑效果,并对比了一些传统的基于微调的处理方法。结果展示如下:
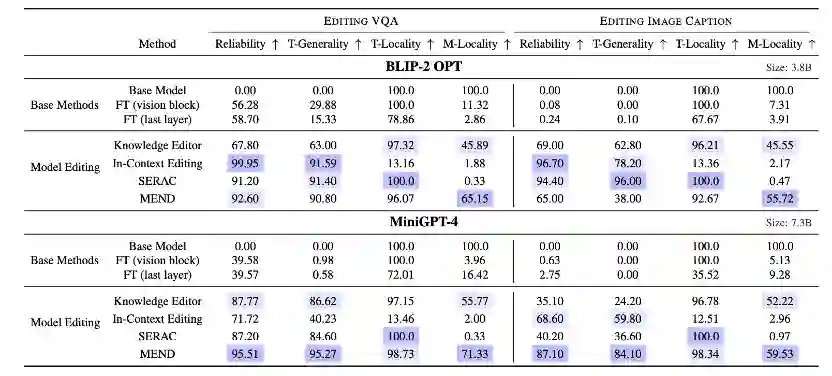
可以看到微调的效果都比较一般,而且会对于模型中的其他知识造成灾难性遗忘。模型编辑在可靠性上表现的都还不错,并且对于模型的稳定性也维持的比较好,不会造成模型的过拟合和灾难性遗忘。 此外作者还展示了编辑不同模块区域的效果展示:
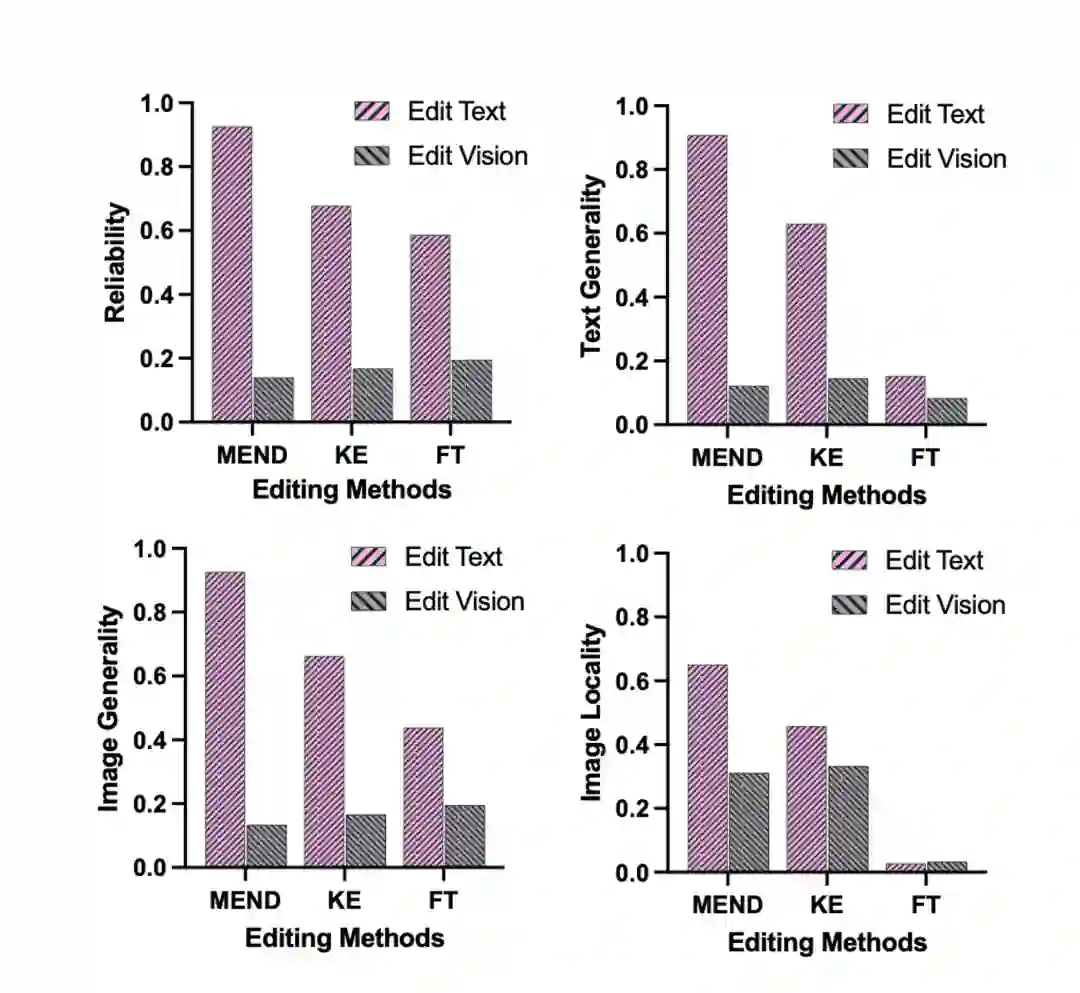
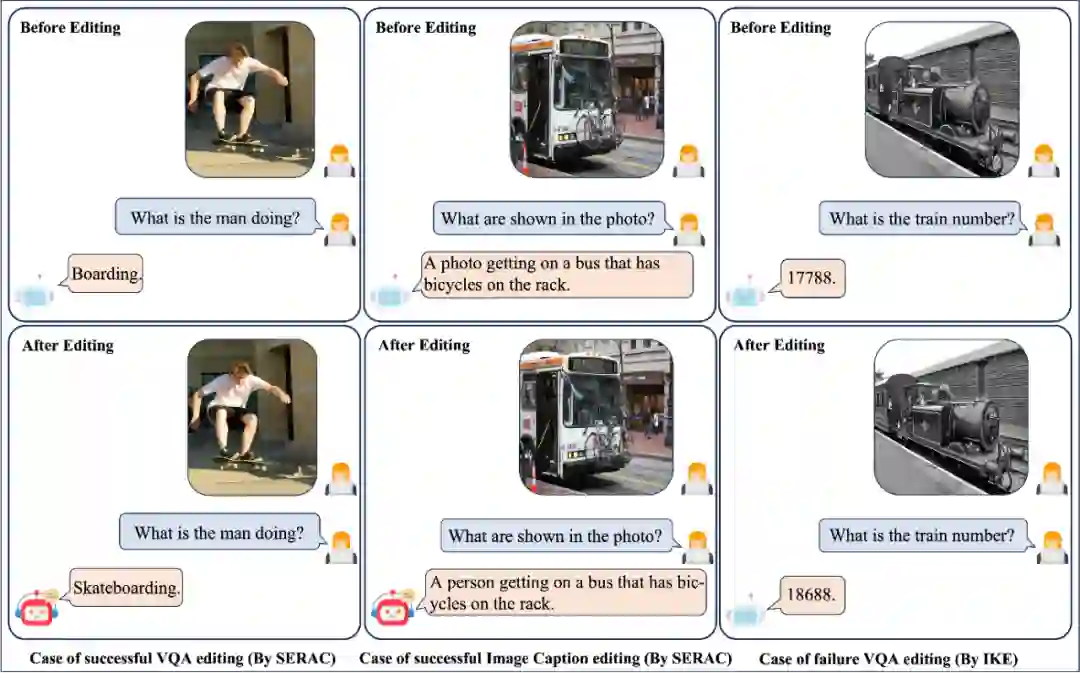
可以看到编辑编辑不同区域效果差异非常大,编辑视觉模块是比较困难的事情。作者觉得这可能和模型的架构有关,编辑语言模型部分可以直接影响模型的输出,而编辑视觉部分只能影响模型输入。而且大部分的知识都是保存在LLMs中的,所以编辑视觉模块的效果不佳。最后展示几组编辑case:
总结
多模态模型是非常重要的领域,如何解决目前面临的幻觉问题是非常关键的问题。模型编辑技术为解决模型幻觉提供了一个不错的思路,但是在多模态模型上依然有许多不足的地方,比如如何能够更有效地进行不同模态之间的协同编辑?如何解决编辑OOD数据?如何做到多模态的连续编辑?这些都是未来值得探讨的方向。