
1.导读
在电商、社交网络、金融等真实场景中,欺诈检测始终是一个核心挑战。欺诈行为往往隐藏在复杂的多跳关系和冗长的文本信息中: * 传统**图神经网络(GNN)方法能利用图结构,但对文本语义的挖掘不够深入; * 仅依赖大语言模型(LLM)**的方式虽能处理语义,却容易陷入“邻居过多 → 提示过长 → 关键信息被淹没”的困境。
近期,新加坡国立大学与字节跳动数据库图团队提出了一种全新方法——DGP**(Dual Granularity Prompting,双粒度提示框架)**,在论文中展示了它如何在性能与令牌效率之间找到平衡,并在多个真实数据集上显著优于现有方法。值得注意的是,这类探索具备架构扩展性与泛化潜力,为更通用、更体系化的图基础模型(Graph Foundation Model,GFM)在工业上的应用奠定了方法论基础。 ![A close-up of a white background
Description automatically generated]
(https://cdn.zhuanzhi.ai/vfiles/634babcaa7616bfc08d5b169bd2d8115)
论文链接:https://arxiv.org/abs/2507.21653 2.传统方法的两难困境
在图增强大模型(Graph-Enhanced LLMs)框架下,主流的**graph-to-prompt****(图到提示)**方法大致有两类: 1. 向量化编码。邻居节点先被压缩为向量,再输入LLM。好处是提示长度可控,但代价是语义被“提前压缩”,导致信息损失。 1. 纯文本拼接。直接把邻居节点的文本拼接输入LLM,保留了全部语义,却带来冗余,甚至可能让百万级token的邻域文本掩盖掉目标节点的关键信号。
在工业场景中,一个两跳邻域就可能扩展到上百万token,模型几乎无法有效学习。如何既保留细节又控制规模?这正是DGP要解决的问题。 3.DGP的核心思想:双粒度提示
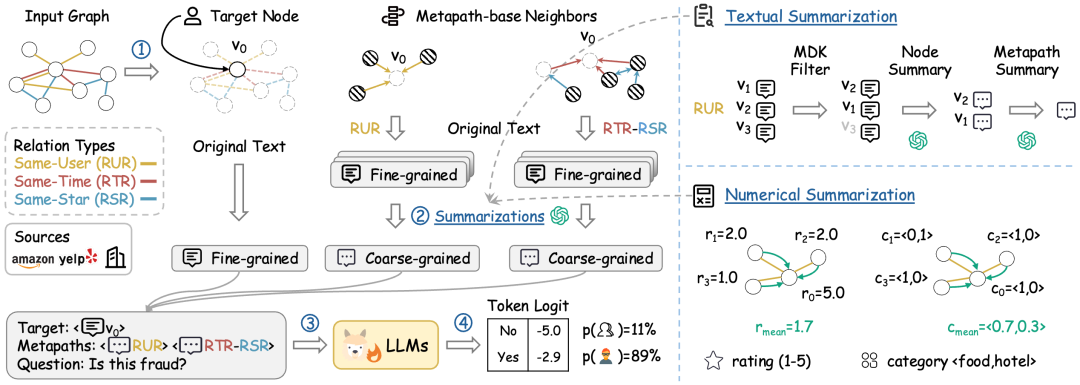
DGP提出了一种差异化的提示策略: * 目标节点:保留细粒度的文本细节,确保核心语义不丢失。 * 邻居节点:转化为粗粒度的信息,用摘要与统计来压缩冗余。
具体来说: * 文本邻居 → 采用双层语义摘要:先对单个节点文本进行压缩,再在元路径(metapath)层面对多个邻居进行二次摘要。 * 数值邻居 → 采用统计聚合:提取均值、分布特征等,传递统计信号而非冗余细节。 * 邻居裁剪 → 借助基于扩散的元路径裁剪(Markov Diffusion Kernel),过滤掉与目标节点无关的邻居,仅保留结构和语义相关的部分。
这一设计保证了提示既不被冗余拖累,也不会牺牲关键信息。 4.实验结果:性能与效率的平衡
研究团队在公开数据集(Yelp、Amazon Video Reviews)和工业数据集(E-Commerce、LifeService)上进行了验证。 
部分实验结果如下表: 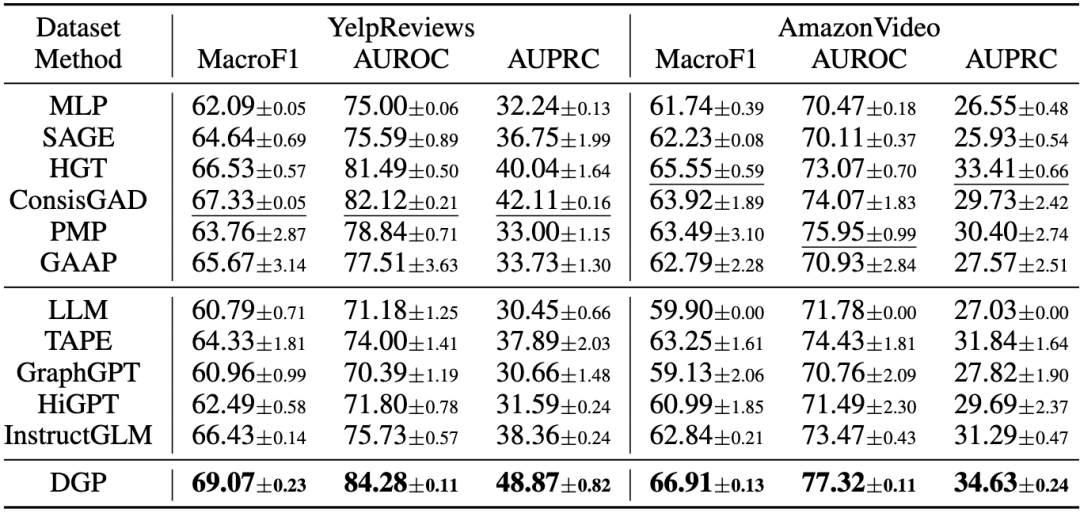
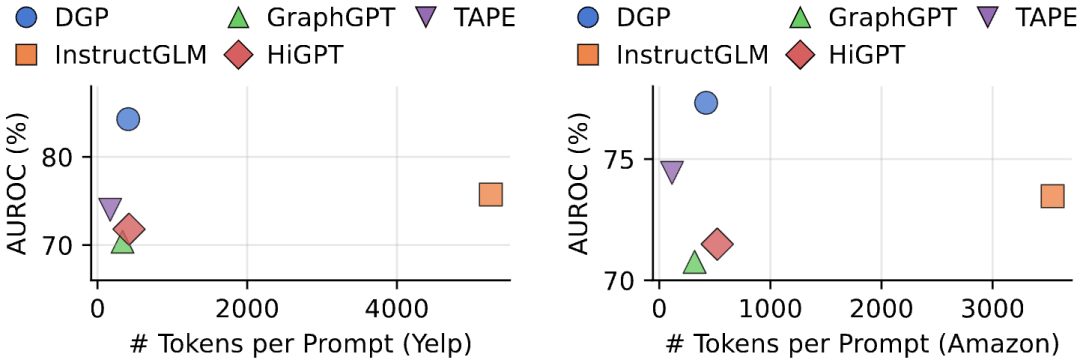
结果显示: * 全面超越现有方法:在Macro-F1、AUROC、AUPRC等多个指标上,DGP均取得最佳成绩,相比SOTA方法提升最高可达6.8%(AUPRC)。 * 有限Token下达到出色性能:与纯文本拼接相比,DGP在有限token预算内仍能保持甚至超越性能,实现了“性能-成本”的优秀平衡。 * 鲁棒性验证:消融实验显示,文本摘要、数值聚合和扩散裁剪均为有效组件;而在提示预算仅10 token时,依然能保持高性能,证明了DGP的高效性。
5.主要贡献
本文的主要贡献概括为以下几点: * 方法创新:提出了双粒度提示框架,解决了图增强大模型在欺诈检测中的“信息过载”问题。 * 差异化摘要策略:针对文本和数值特征分别设计了双层语义压缩与统计聚合,兼顾表达力与效率。 * 实证验证:在多个公开与工业数据集上,DGP全面超越GNN与LLM基线方法,展现出图增强LLM在欺诈检测中的巨大潜力。
6.小结
DGP通过在目标节点与邻居节点之间采用差异化的粒度控制,缓解了图增强大模型在欺诈检测中存在的信息过载问题。在多项公开和工业数据集上的实验结果表明,它在性能和token效率之间取得了较好的平衡。同时,这类方法的设计思路也显示出一定的扩展性与泛化潜力,可以作为构建更系统化**图基础模型(Graph Foundation Model,GFM****)**的一种探索路径。




