论文浅尝 | 基于知识图谱的子图匹配回答自然语言问题
本文转载自公众号:珞珈大数据。

本次论文讲解的是胡森 邹磊 于旭 王海勋 赵东岩等作者写的论文-Answering Natural Language Questions by Subgraph Matching over Knowledge Graphs,主要是分享一些阅读论文的收获,希望能对正在学习自然语言的初学者带来一些启发。本次ppt的参考资料主要是论文和北京大学邹磊教授的面向知识图谱的自然语言问答。
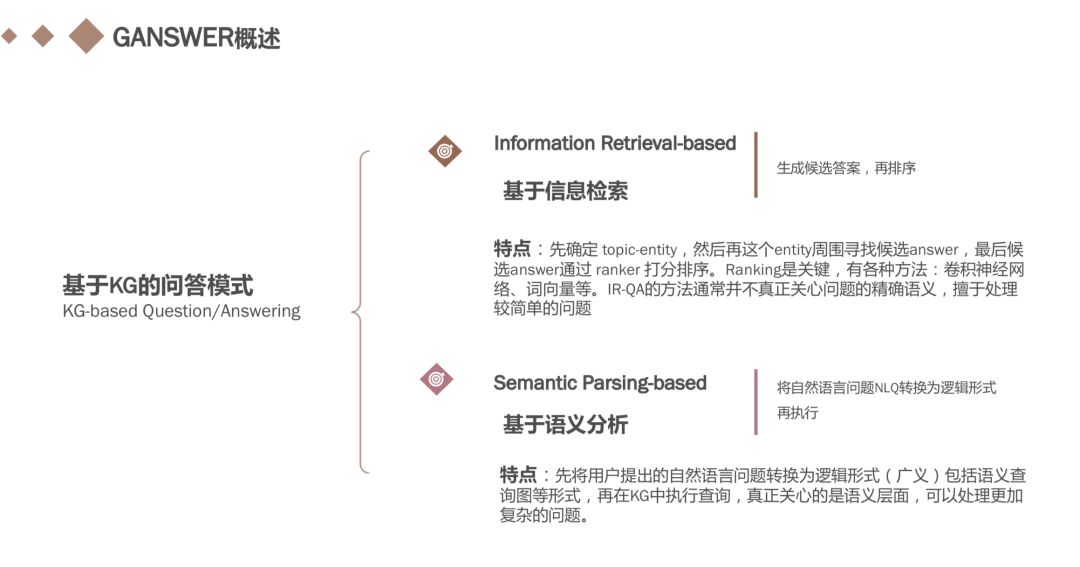
目前基于KG的问答模式有两种,一种是基于信息检索的方式,一种是基于语义分析的方式。前者较之于后者,没有真正关心语义,主要是ranker算法,擅于处理简单问题,后者则是从语义的角度将用户的自然语言问题转化为逻辑形式,再在KG中执行查询。

ganswer 就是基于语义分析的方法,区别于传统的语义解析的方法,它是一种新颖的面向知识图谱的自然语言问答系统,以图数据驱动的视角回答RDF知识库上的自然语言问题,本文解决了查询匹配时自然语言问题的模糊性,如果找不到匹配,则会保存消除歧义的陈本,称之为RDF Q / A的图数据驱动方法。
虽然本文的方法中仍然存在两个阶段“问题理解”和“查询评估”,但本文并不像现有解决方案那样在问题理解步骤中生成SPARQL。 正如本文所知,SPARQL查询也可以表示为查询图,它不包含任何歧义。 相反,构建了一个表示用户查询意图的查询图,但它允许在问题理解阶段存在歧义,例如短语链接和查询图结构的模糊性。
图数据驱动解决方案的核心在于两个方面:一个是如何精确构建语义查询图Q^s,另一个是如何有效地找到匹配。为了解决上述问题,本文提出了两个不同的框架:第一个被称为“关系(边)优先”。这意味着总是从自然语言问句N中提取关系,并将它们表示为边。然后,组装这些边形成一个语义查询图。第二个框架采用了另一个角度,称为“节点优先”。它从查找节点(实体/类短语和通配符)开始,尝试引入边来连接它们以形成语义查询图Q^s。此外,两个框架之间的另一个主要区别是,当问题句子中存在一些隐含或不确定的关系时,节点优先框架定义了Q^s的超级图(称为Q^u)。换句话说,节点优先框架并不是像关系优先框架那样在子图匹配评估之前修复Q^s的结构。

除了KG以外,我们在离线阶段,构建了两个字典,它们是实体提及字典和关系提及字典。 它们将用于在线阶段从用户的问题句子中提取实体和关系。实体提及字典有助于实体链接,关系提及字典将自然语言关系短语映射到RDF数据集中的谓词。实体提及字典的构建不是本文的贡献,本文采用CrossWikis词典。关系提及字典借用TF-IDF计算映射关系rel的置信概率。
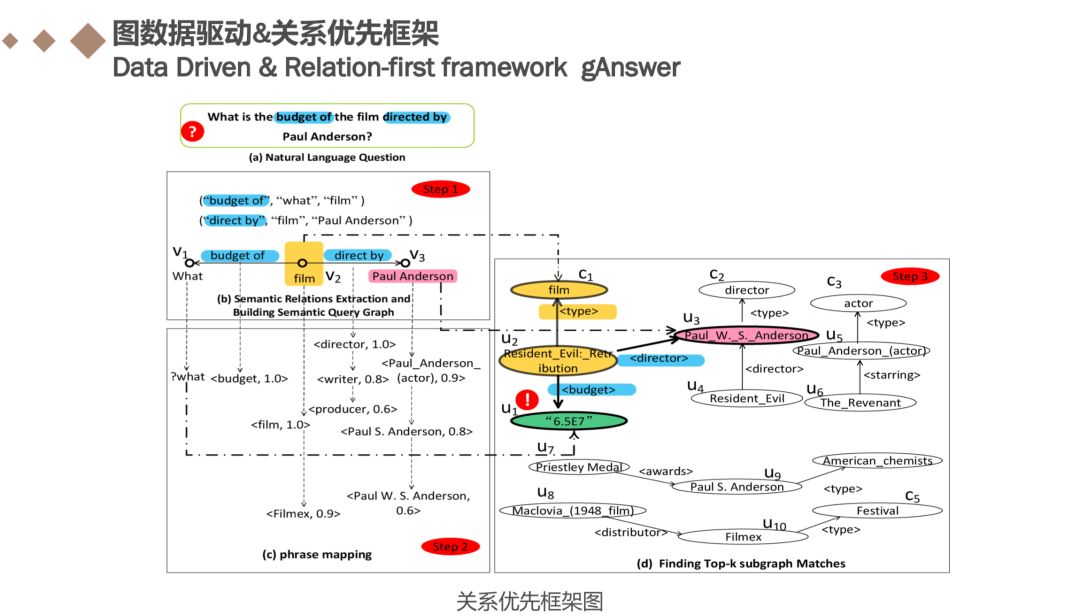
首先先介绍下关系优先框架,看整体的框架图,首先给定一个自然语言问题:What is the budget of the film directed by Paul Anderson?,之后进行关系抽取构建语义查询图,进行短语映射到RDF中G上的实体或者谓词边径,根据top-k子图匹配算法计进行打分。
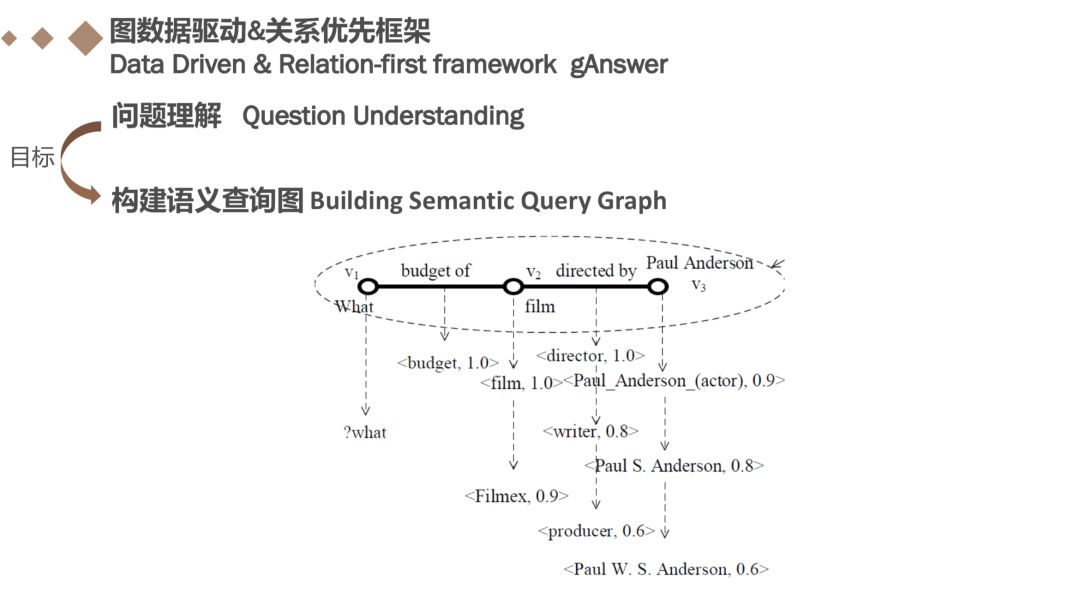
本文两个框架都存在两个阶段:“问题理解”和“查询评估”,在关系优先框架中,问题理解的目标是建立一个语义查询图来表示用户在N中的查询意图,接下来我们详细讲一下如何构建一个语义查询图。

首先是关系识别,如何从一个自然语言问题识别关系提及,本文通过为关系提及字典中的所有关系提及建立倒排索引。对于上述具体问题,我们识别出buget of和direct by两种关系。
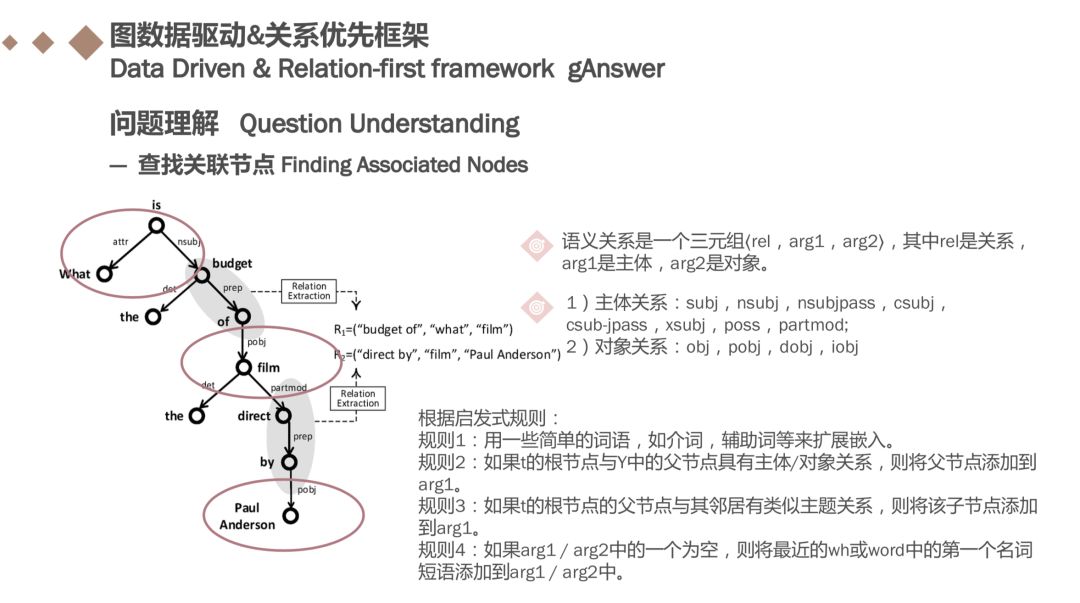
在Y中找到关系后,我们查找两个相关的节点。如果一个短语被认为是实体/类的提及,它就被认为是一个节点。 外,节点也基于嵌入周围的语法主语和类似对象的关系来识别,这些关系如ppt中所示。
假设我们找到一个关系rel的嵌入子树y。我们通过检查节点w中的每个短语w来确认arg1是否是实体/类提及,或者w和它的一个子元素之间是否存在上述主体类关系(通过检查依赖树中的边标签),如果存在主体关系,我们将该子项添加到arg1。同样,arg2被类对象关系所识别。
另一方面,当arg1 / arg2在这一步之后为空时,我们引入几个启发式规则如ppt中所示。如果在应用上述启发式规则后,我们仍然无法找到节点短语arg1 /arg2,我们只需在进一步考虑丢弃关系提及rel。
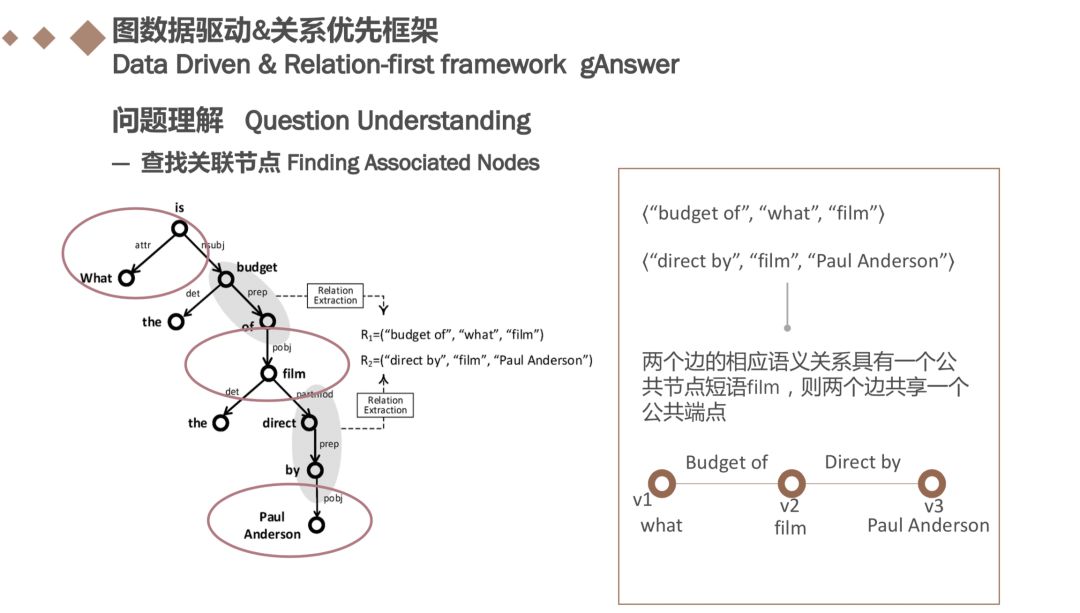
在获得了自然语言N的所有语义关系后,我们需要建立一个语义查询图。如上图中的例子,两个语义关系⟨“budget of”, “what”, “film”⟩和⟨“direct by”, “film”, “Paul Anderson”⟩表示为边,两个边共享一个公共端点film,则这两条边共享一个公共端点,
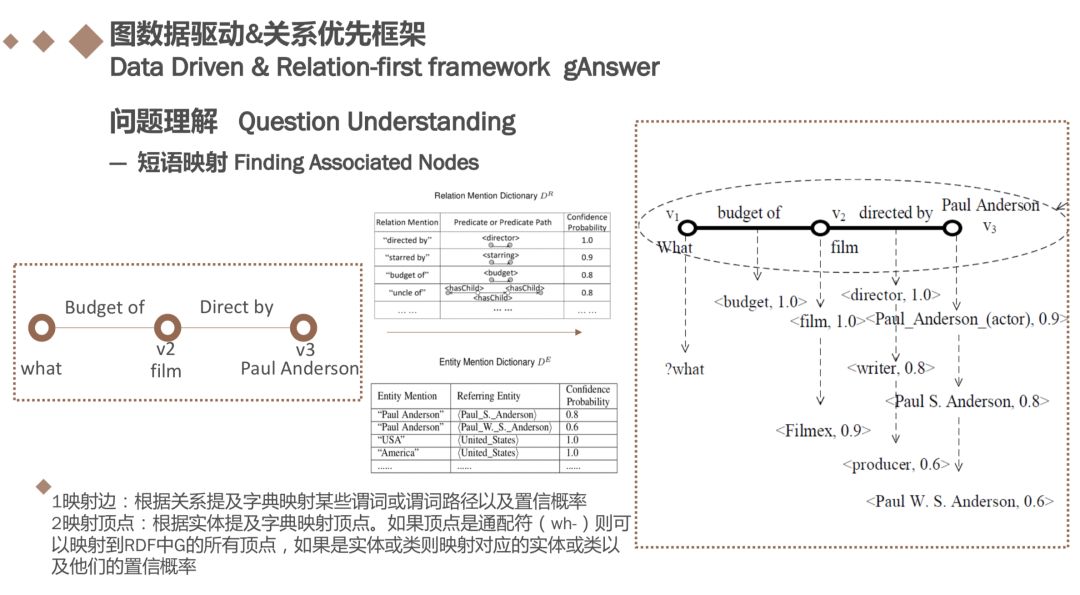
讨论如何将关系提及和节点短语映射到候选谓词/谓词路径和实体/类,给定语义查询图中的节点vi,如果vi是一个实体短语或类短语,我们可以使用基于实体字典的实体链接算法来检索所有可能对应于vi的实体/类(在RDF图G中),标记为C(vi),例如v3(“Paul Anderson”)对应于“Paul Anderson(actor)”,“Paul Anderson”和“Paul ·W·S·Anderson”, ;如果vi是一个通配符(如wh-word),我们假设C(vi)包含RDF图G中的所有顶点。使用δ(arg,u)或δ(arg,c)来表示置信概率。
同样,根据关系提及字典将Q^S中的每个边vivj映射到候选预测列表,表示为 Cvivj。 每个映射与置信概率 δ(rel,L)相关联 和边径“v2v3”映射到⟨director⟩,⟨writer⟩和⟨producer⟩。
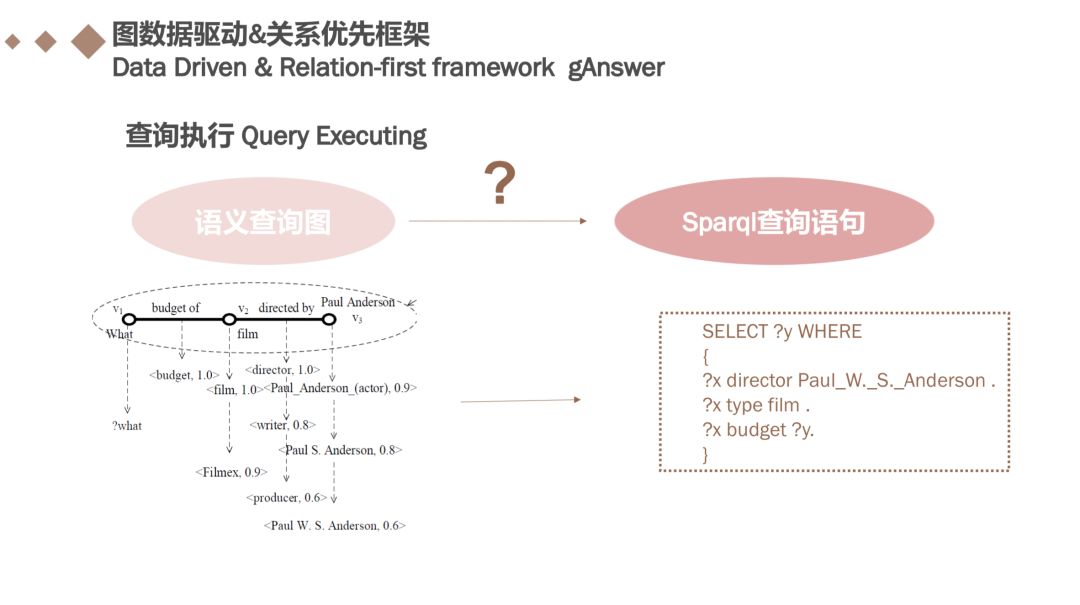
阅读本文的时候是带着问题去读的,就是语义查询图需要转换为sparql查询语言,其实本文中有一句话写到:SPARQL查询也可以表示为查询图,它不包含任何歧义。 下面走进代码。

在ganswer的源码中查找到关于如何去数据库gstore中查找,也只是一种形式上的转换。

本文定义了子图匹配的定义,需要满足三个条件,假设所有候选列表都按置信概率的非递减顺序排列。Q^s的每个子图匹配都有一个分数。 它是从每个边和顶点映射的置信概率计算出来的。 计算公式如上,权重α的默认值是0.5,这意味着实体分数和关系分数具有相同的权重。

一旦我们确定中每个候选人名单的候选人,我们就会获得一个“选择”。该选择由n长度向量表示,其中n是候选列表的总数(算法3中的第3行)。最初矢量值为0,这意味着我们为每个候选列表选择第一个候选(第4-5行)。每次我们从H的堆顶获得最佳选择时。我们可以使用所选候选项(第6-7行)替换中的所有顶点/边界标签来构建查询图。第8行应用VF2等现有的子图同构算法来查找上G的所有子图匹配。然后我们保持最大堆H,以保证从H得到的每个选择在所有未尝试选择中得分最高,如第9行所示。对于每个候选列表Li,我们在当前选择Γ的第i位添加一个以获得新的选择Γ并将其放入H.因此,当我们找到k个匹配时,我们可以提前终止。

目前关系优先框架有两个主要的障碍:一是高度依赖解析器和启发式规则,如果句法依赖树存在某些错误,就会导致错误的语义查询图的结构和错误的答案。另一个是无法识别隐含关系。如果关系没有明确出现在问题句子中,则很难说明这种语义关系,因为我们的关系抽取依赖于关系提及字典中的关系提及。例如中国女孩。
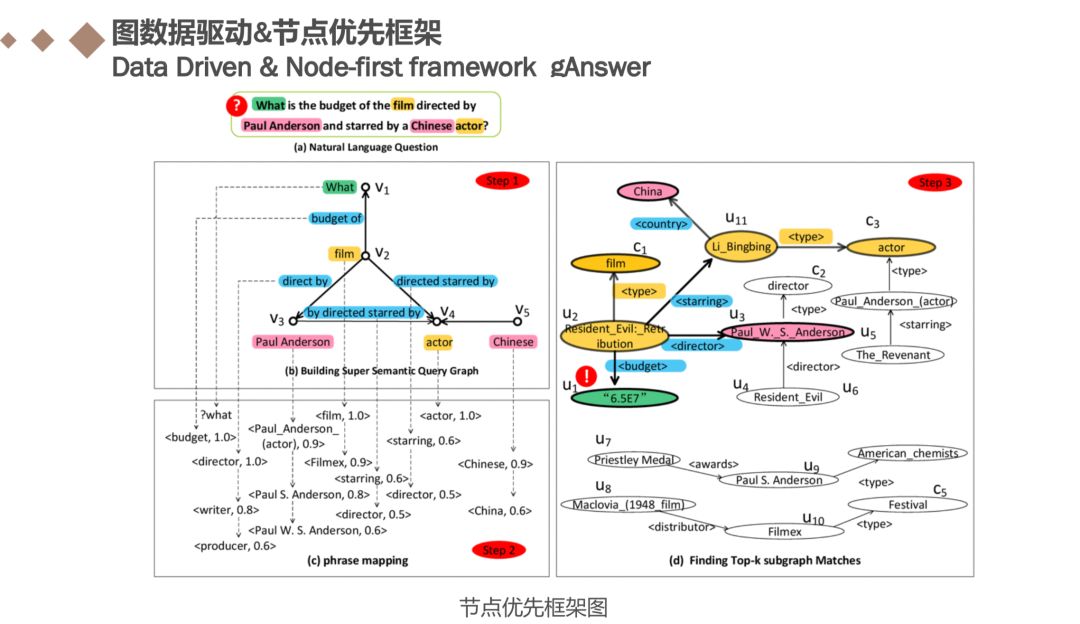
考虑到上述两个障碍,我们设计了一个健全的框架,即使存在隐含关系和依赖关系解析树中的错误。 第二个框架中有两个关键点:
1)第一步是从问句N中提取节点短语(如实体短语,类短语和wh-词),而不是第一个框架中的关系提取。
2)我们不打算在问题理解步骤中构建语义查询图Q^s。 相反,我们构建了一个超语义查询图Q^u,它可能具有一些不确定或隐含的关系(即边)。 换言之,我们允许在问题理解步骤中查询图的结构模糊性,这将在查询评估步骤中解决。
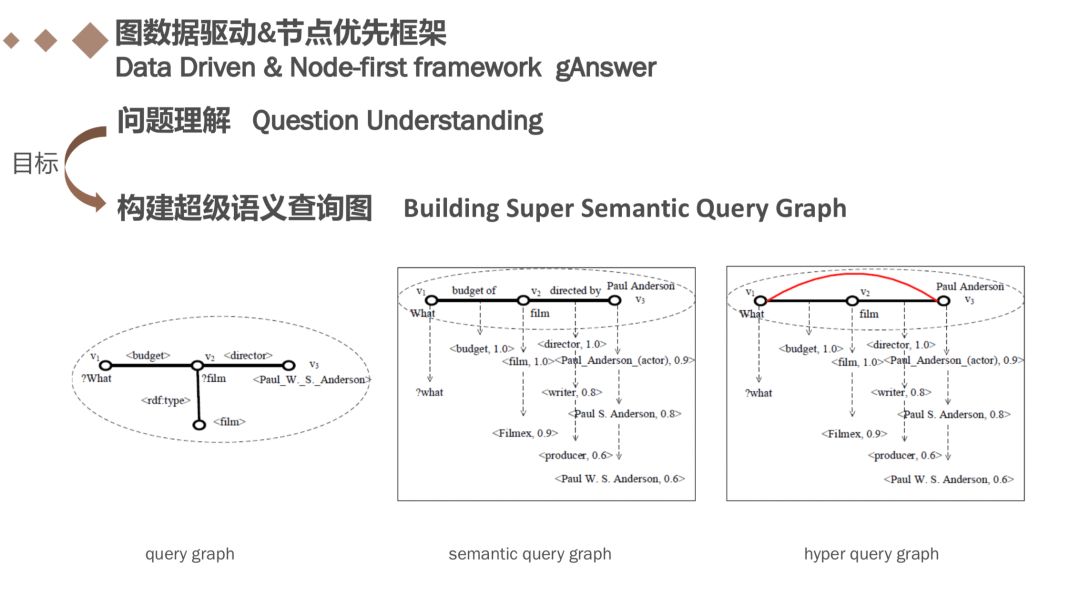
节点优先框架也存在问题理解和查询执行两个阶段。问题理解部分的目标是构建超级语义查询图Q^u,超语义查询图与类似,但允许明确或不确定的关系。

例如问题:What is the budget of the film directed by Paul Anderson and starred by a Chinese actor? 通常,我们提取实体,类和通配符作为节点。 我们采用基于字典的实体链接方法来查找实体和类。 我们收集所有不能映射到任何实体和类作为通配符的wh-词和名词。节点识别结果如图所示即“what”,“film“,”Paul Anderson“,”chinese“,”actor“等。
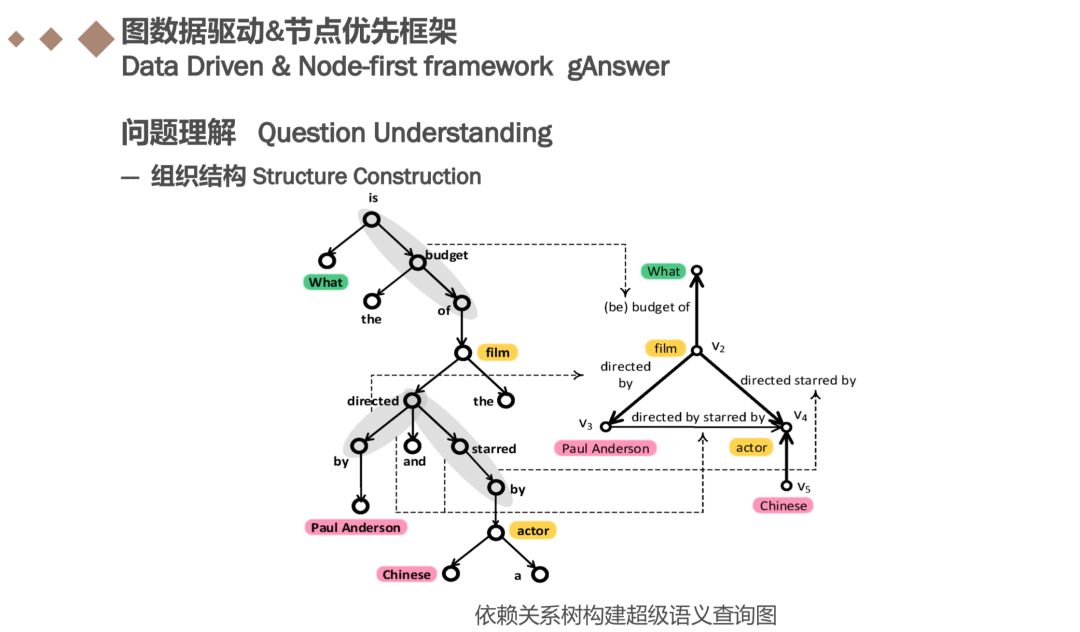
鉴于所有节点都已被识别,下一步是构建一个超语义查询图, 给定一个节点集合V(已经在第一步中被识别)和问题句子的依赖树Y,对于任意两个 节点vi和vj(∈V),当且仅当vi和vj之间的简单路径不包含V中的其他节点时,引入vi和vj之间的边。
依赖关系树中“what”和“film”之间的路径包含三个词:“is”,“budget”和“of”,因此v1和v2之间的边缘标签(在中)是“…budget of “。 如果简单路径不包含任何单词(例如“actor”和“Chinese”之间的路径),则边标签为空。
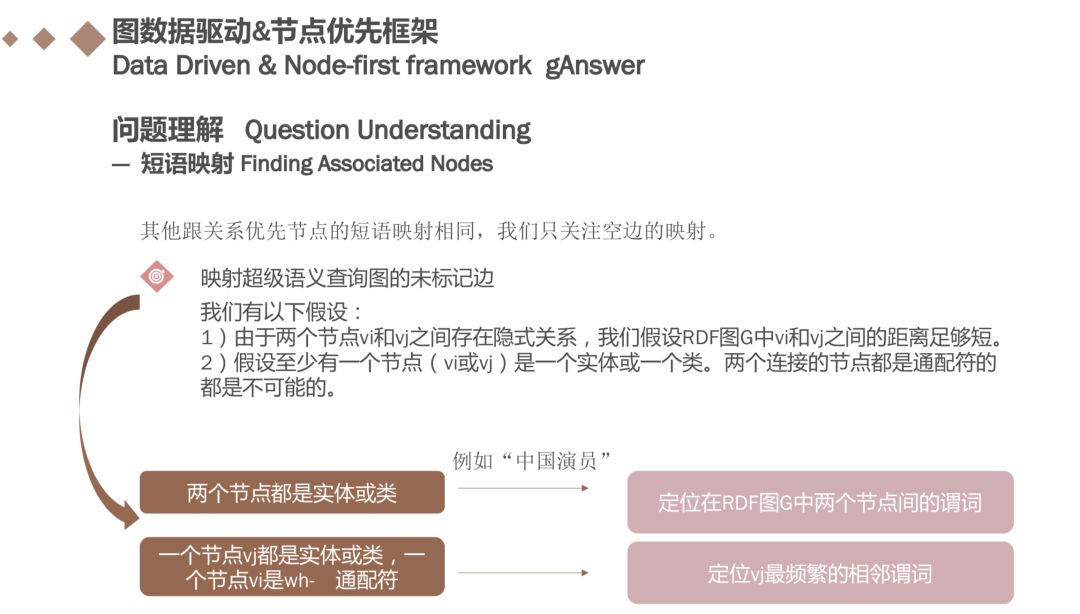
映射节点和标记边的方法与的短语映射相同,关注如何将未标记的边映射到RDF图G中的谓词。首先vi与vj之间满足以上两个假设。
如果两个节点都是常数(即,实体或类),例如“中国演员”,则我们将两个节点定位在RDF图G处并找出它们之间的谓词。如果一个节点vi是一个通配符,另一个vj是一个实体或类,我们在RDF图G中定位vj,并选择最频繁的相邻谓词作为匹配边缘的候选谓词。

节点优先框架的算法采用自下而上的算法,具有四个特点,下面详细介绍下算法。

与基线算法不同,我们在开始时不决定查询图。相反,我们试图通过扩展当前的部分结构来构建“正确”的图形结构。通常,在每一步中,我们通过扩展一个更多的边来扩展当前的部分结构Q,(算法5中的第6行)。最初,Q仅包含中的一个起始顶点。我们选择候选数量最少的顶点作为起始顶点。如果新的扩展的部分结构Q可以通过RDF图G找到匹配(第7-11行),我们继续搜索分支。此外,如果Q已经是的一个跨越子图(第9-11行),我们记录Q的匹配以及答案集RS中的匹配分数。我们只保留RS中的当前top-k匹配和当前阈值δ。如果Q无法通过RDF图G找到匹配(第12-13行),我们回溯搜索分支。
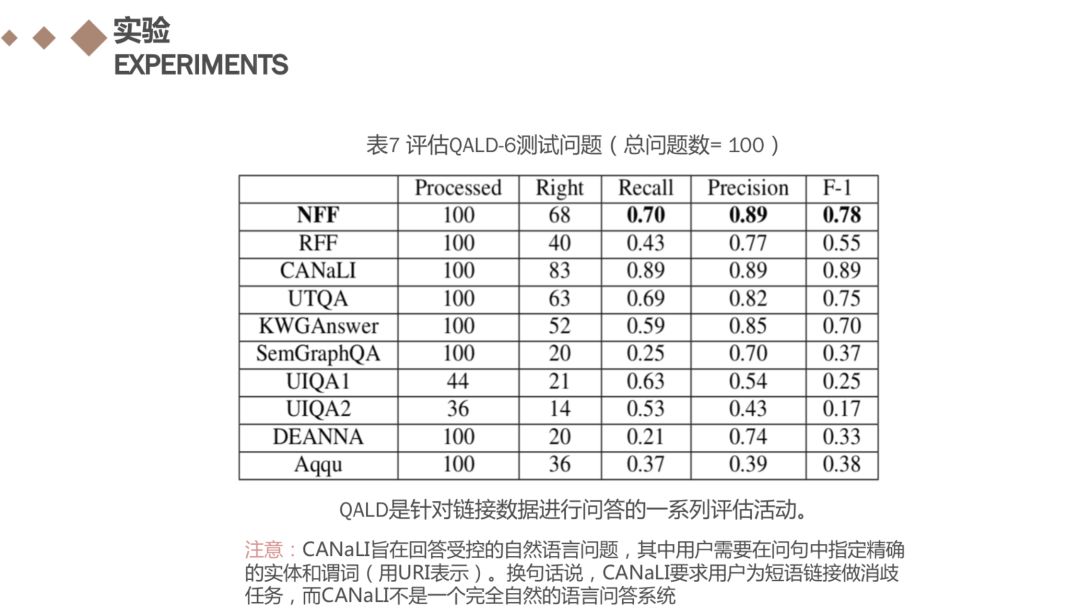
我们分别使用两个基准评估我们的DBpedia和Freebase系统。 对于DBpedia,我们使用QALD-6作为基准。 我们知道,QALD是一系列开放式域名问答系列活动,主要基于DBpedia。
NFF方法加入了QALD-6比赛,并以F-1的方式获得第二名8。 NFF可以正确回答68个问题,而关系优先框架(RFF)可以正确回答40个问题。请注意,CANaLI旨在回答受控的自然语言问题,其中用户需要在问句中指定精确的实体和谓词(用URI表示)。换句话说,CANaLI要求用户为短语链接做消歧任务,而CANaLI不是一个完全自然的语言问答系统。
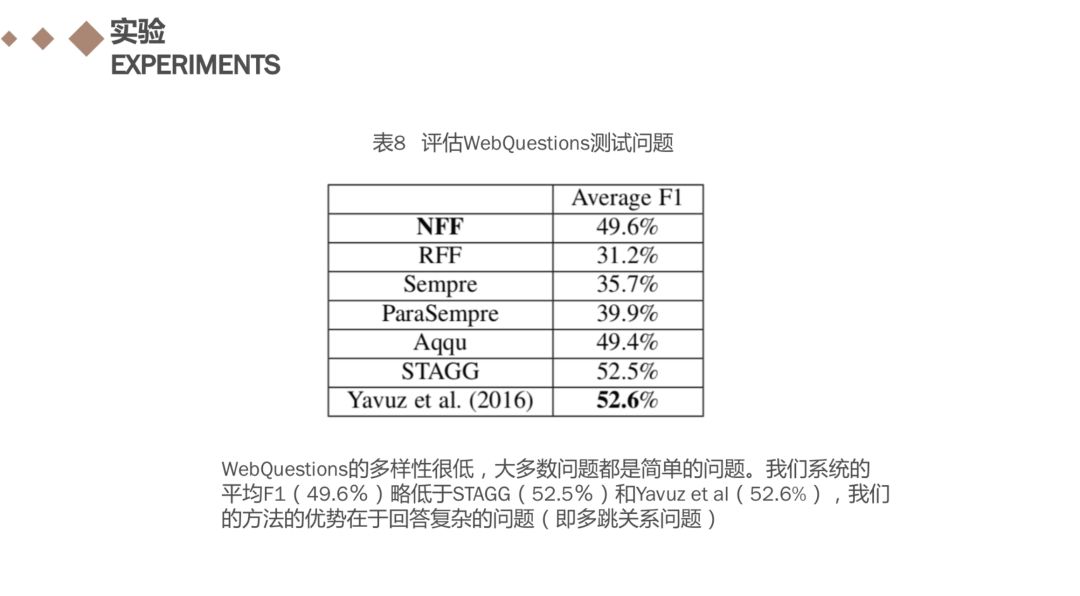
对于Freebase,我们使用WebQuestions [17]作为基准,我们系统的平均F1(49.6%)略低于最先进的工作[21](52.5%)和Yavuz等人。 [22](52.6%)。 这是因为WebQuestions中的问题比QALD更简单,大多数问题可以转化为“一个三重”的查询,即只有一个实体和一个关系。实际上,我们的方法的优势在于回答复杂的问题(即多跳关系问题),例如QALD基准测试中的一些问题。
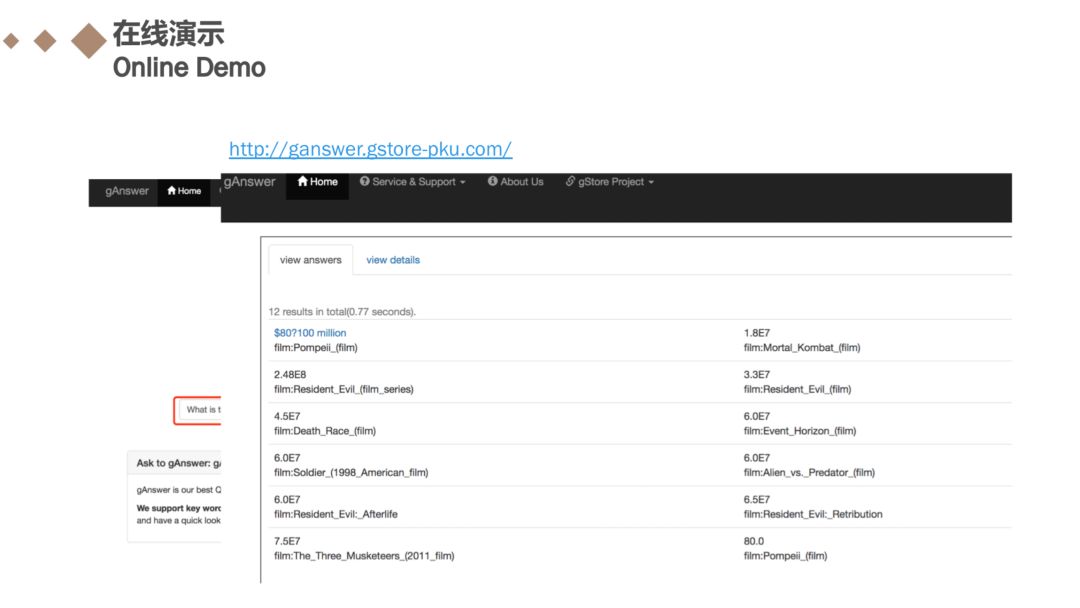
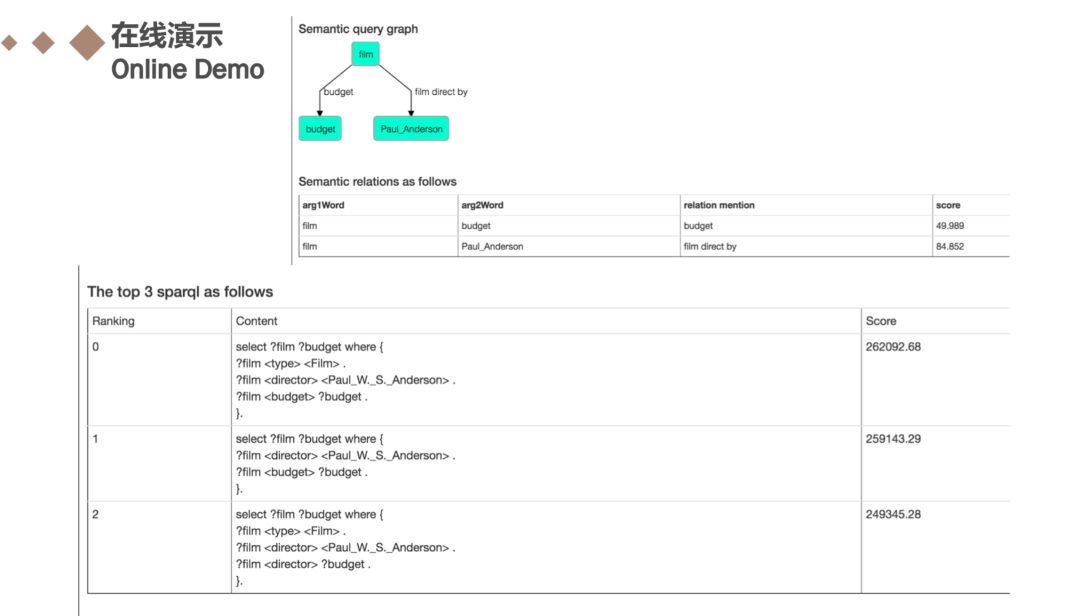
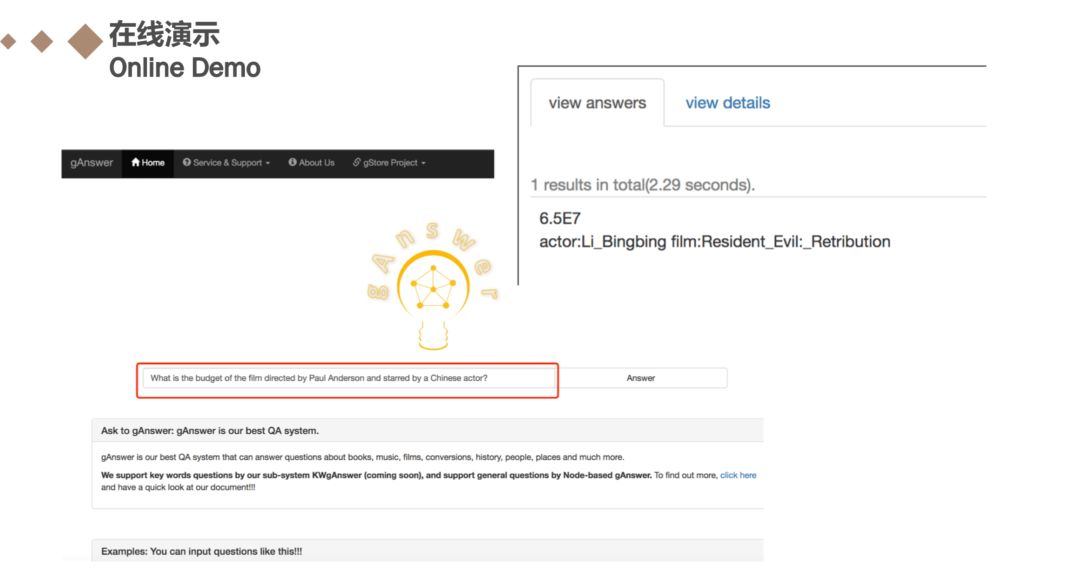
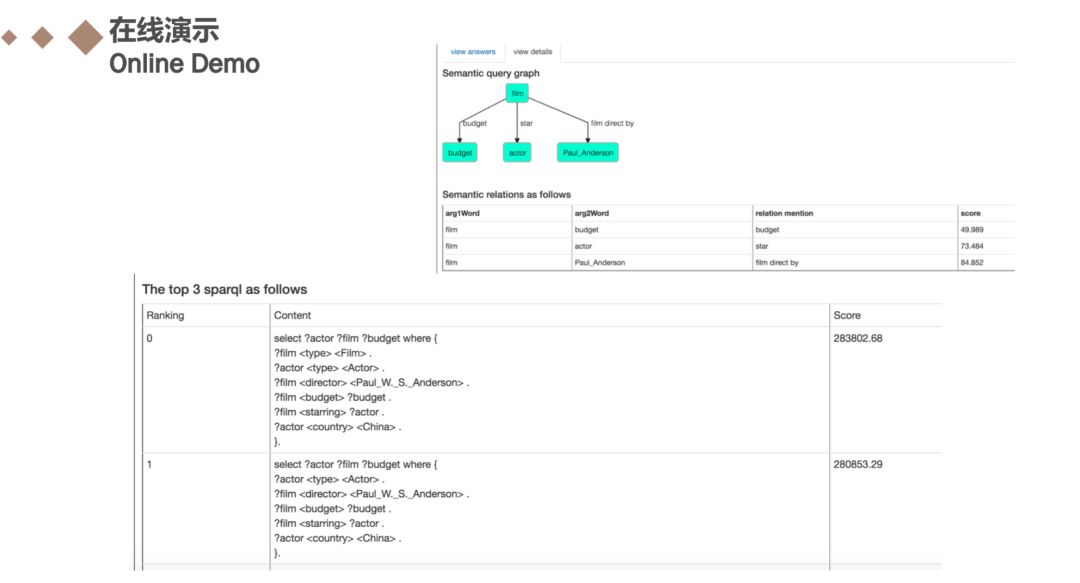
列出了在线演示的网址:http://ganswer.gstore-pku.com/,大家有兴趣的可以在网站上尝试一下。我试了关系优先框架和节点优先框架的两个问题,并点击查询,获得结果如ppt中所示。
分享至此接近尾声,欢迎感兴趣人士留言一起探讨。

OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。


