**论文题目:******Generalizing to Unseen Elements: A Survey on Knowledge Extrapolation for Knowledge Graphs **本文作者:**陈名杨(浙江大学)、张文(浙江大学)、耿玉霞(浙江大学)、许泽众(浙江大学)、Jeff Z. Pan(爱丁堡大学)、陈华钧(浙江大学) **发表会议:**IJCAI 2023 论文链接:https://www.ijcai.org/proceedings/2023/0737.pdf 欢迎转载,转载请注明出处
一、引言
知识图谱(KG)已成为各种应用中重要的知识资源,同时知识图谱嵌入(KGE)方法近年来备受关注。然而,传统的KGE方法在模型测试中仍然面临着处理未知实体或关系(Unseen Entities or Relations)的挑战。最近的研究也在不同场景中对知识图谱中未知元素的泛化问题进行了研究。例如,一些研究着重于预测知识图谱之外实体(Out-Of-Knowledge-Base,OOKB)的缺失三元组,另一些归纳式关系预测方(Inductive Relation Prediction)法研究了如何泛化到包含未知实体的全新知识图谱。此外,对于在低资源环境中(如少样本和零样本情况下)泛化到未知关系的问题也得到了深入研究。 当前很多方法虽然都在讨论如何处理未知实体或者关系,但往往分散在不同的设定场景或者语境下。本综述将这些不同的方法进行抽象,使用一组通用的术语统一这些方法,并将它们统称为“知识外推”(Knowledge Extrapolation)。在本论文中,我们总结了当前的知识外推方法,按照我们提出的分类法进行分类,并描述了它们之间的相互关系。此外,我们介绍了该领域下一些常用的基准数据集。最后,我们提出了在该领域下未来研究的潜在方向。 二、知识外推的设定
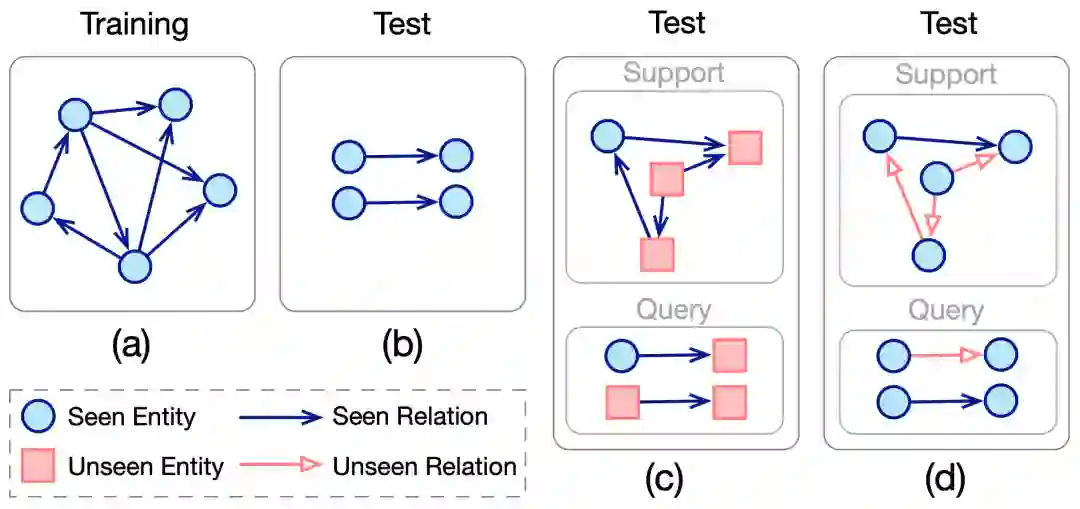
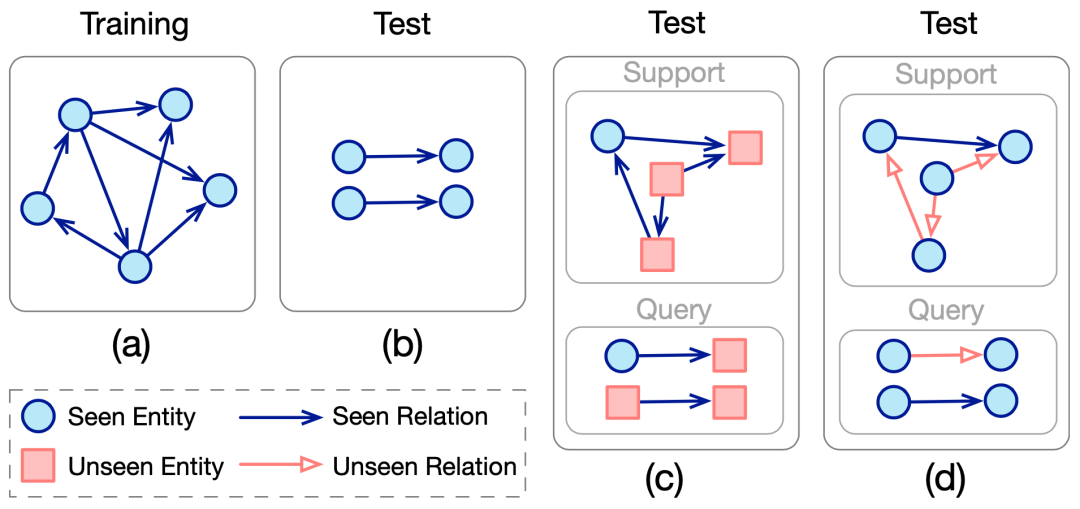
知识外推方法旨在进行对未知元素(包括未知实体或关系)的链接预测。为了统一处理这些未知元素的现有研究,我们引入了一组通用术语。具体而言,在知识外推过程中,有两个用于测试的数据集:一个提供有关未知元素的支持信息(例如它们的结构或文本特征),另一个用于评估模型的链接预测能力,类似于原始测试集。我们将这两个数据集分别称为支持集和查询集,测试集被构建为。尽管不同的研究可能使用不同的术语,但它们在知识外推过程中都都会涉及这两个数据集。为了方便起见,我们统一称之为支持集和查询集。 在本研究中,我们将现有的处理未知元素的知识外推方法分为两类:实体外推(Entity Extrapolation)和关系(Relation Extrapolation)外推。如下图所示,我们使用术语“实体外推”来指代在测试集中出现训练时未见过的实体的情况,而使用“关系外推”来描述在测试集中存在训练时未见过的关系的情况。
三、知识外推的分类
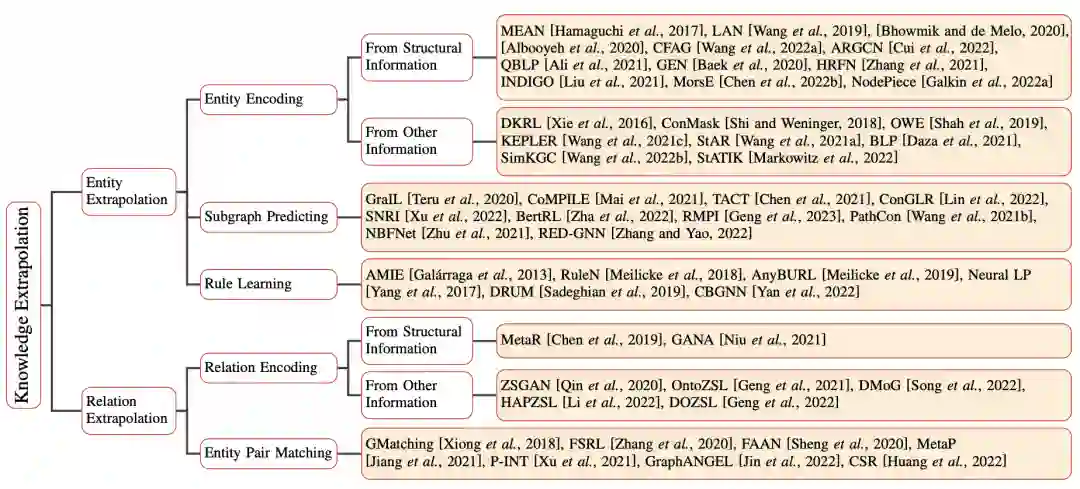
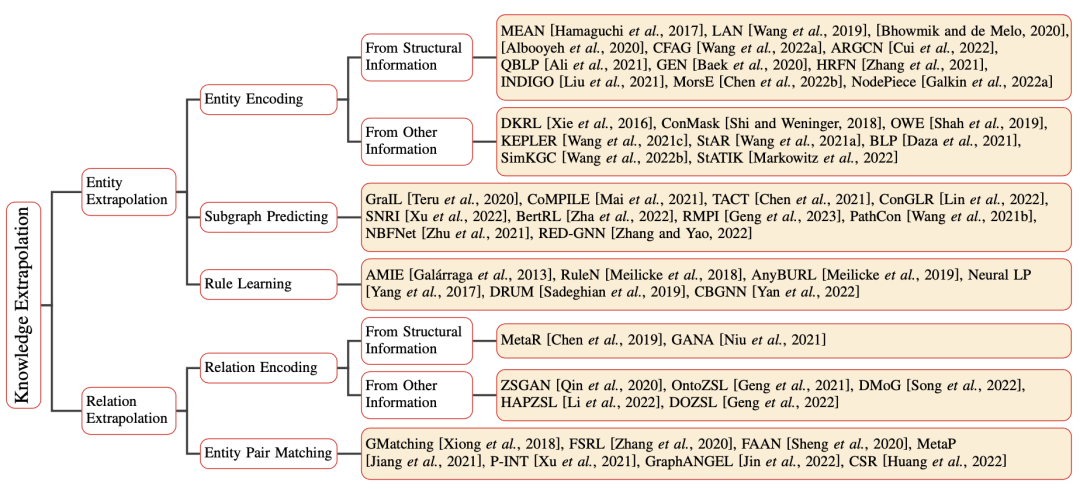
如下图所示,我们根据这些方法的模型设计将它们进行分类。对于每一类方法,我们首先介绍其一般思想,然后深入探讨现有方法的具体细节。
四、实体外推
Entity Encoding-based Entity Extrapolation
传统的知识图谱嵌入方法通常会学习一个实体的嵌入表。然而,这一范式阻碍了模型对未知实体的外推。为了处理未知实体,一个直观的方法是学习如何编码实体,而不是学习固定的实体嵌入表。这些学到的编码器可以在实体的支持集上操作,为测试阶段新出现的实体生成合理的嵌入。我们将这一类方法称为基于实体编码的实体外推(Entity Encoding-based Entity Extrapolation)。 现有研究设计了各种编码模型,对应于支持集中不同类型的信息。如果支持集是有关未知实体的三元组,那么会从结构信息中编码这些实体。如果支持集包含关于未知实体的其他类型信息(例如文本描述),我们将这种情况称为从其他信息中编码未知实体。
这一类方法的典型模型有LAN、MorsE、StAR等。
Subgraph Predicting-based Entity Extrapolation
前述的基于实体编码的方法通常单独处理三元组中的头实体、关系和尾实体。然而,一些研究提供了另一种观点,它们将三元组中的头实体和尾实体一起处理,并编码它们之间的关系子图。这种观点假定了两个实体之间的子图语义可以用来预测它们的关系。编码两个实体的子图的能力可以外推到未知实体,因为子图结构与实体无关。 这一类方法的典型模型有GraIL、CoMPILE、TACT等。
Rule Learning-based Entity Extrapolation
还有一些研究探索了从知识图谱中学习规则从而完成知识外推,因为这些逻辑规则本质上不依赖于特定的实体,从而可以外推到未知实体。基于规则学习的方法可以分为两类。纯符号方法通过统计从现有知识中生成规则,并使用预定义的指标对其进行筛选,还有一类方法结合了神经网络和符号规则。 这一类方法的典型模型有AMIE、Neural LP、CBGNN等。 五、关系外推
Relation Encoding-based Entity Extrapolation
与实体外推类似,传统的知识图谱嵌入方法在关系外推方面的不足之处在于它们不能为未知关系提供合理的嵌入表示。然而,由于未知关系的支持集中可以利用一些观察到的信息,将这些信息编码以嵌入表示关系是一个直观的解决方案。根据用于编码关系的信息类型,我们还将这些方法分类为从结构信息编码和从其他信息编码。 这一类方法的典型模型有MetaR、ZSGAN、OntoZSL等。
Entity Pair Matching-based Relation Extrapolation
另一种解决方案,不是直接对关系进行编码,而是对未知关系的头实体和尾实体对进行编码,然后将这些编码的实体对与查询集中的实体对进行匹配,以预测它们是否由相同的未知关系连接。 这一类方法的典型模型有GMatching、FSRL、FAAN。
六、未来展望
目前,大多数知识外推方法主要通过在测试集上进行链接预测来评估。尽管链接预测可以证明模型的有效性并有助于知识图谱的补全,但在各种下游应用中研究如何泛化到未知的知识图谱元素也具有重要价值。
同时现有的知识外推方法主要以自然语言作为未知元素的支持信息。然而,我们认为图像等多模态信息也可以用于泛化,因为它们可以被特定的预训练编码器所理解。此外,超关系型知识图谱也可以提供不同的模态信息。 现有知识外推研究主要集中在解决实体外推和关系外推,但在实际应用中,未知实体和关系可能同时出现。如何同时考虑未知关系和实体也是未来值得研究的方向之一。 在实际应用中,一些知识图谱包含了时间约束,需要在知识图谱外推中考虑时间信息。此外,现有的知识外推方法通常假定单次外推,但最近的一些研究考虑了多批次和终身学习设定下未知元素出现的情况。
七、总结
近年来,解决如何泛化到测试阶段知识图谱中未知元素的研究逐渐增多。本文对当前这些研究提供了相对全面的综述,并使用一组通用术语对它们进行总结。我们采用我们提出的系统分类法对现有方法进行分类,并列出了常用的基准测试以及采用这些基准测试的方法。我们希望这一探索可以为该领域提供清晰的描述,并促进未来的研究。如果对该综述的细节感兴趣,欢迎各位研究者阅读本综述的论文原文。