新手必看:生成对抗网络的初学者入门指导

本文为 AI 研习社编译的技术博客,原标题 A Beginner's Guide to Generative Adversarial Networks (GANs)。
翻译 | 江舟 校对 | 江舟 整理 | 志豪
原文链接:
https://skymind.ai/wiki/generative-adversarial-network-gan
你可能不认为程序员是艺术家,但编程的确是一门非常有创意的职业。它是一种基于逻辑的创造力体现。 - John Romero
生成对抗网络(GANs)是由两个网络组成的深度神经网络体系结构,它将一个网络与另一个网络相互对立(因此称为“对抗性”)。
2014年,Ian Goodfellow和包括Yoshua Bengio在内的蒙特利尔大学的其他研究人员在一篇论文中介绍了GANs。Facebook的人工智能研究主管Yann LeCun称对抗训练是“在过去10年中最有趣的机器学习想法”。
GANs的潜力是巨大的,因为他们可以学习模仿任何数据分布。也就是说,GANs可以被教导在任何领域内创造与我们相似的世界:图像、音乐、演讲、散文。从某种意义上来说,他们是机器人艺术家,他们的作品令人印象深刻—甚至令人心酸。

生成算法与判别算法
为了理解GANs,你应该知道生成算法是如何工作的,为此,就可以将它与判别算法进行对比。 判别算法试图对输入数据进行分类; 也就是说,给定数据实例的特征,它们会预测数据所属的标签或类别。
例如,给定电子邮件中的所有单词,判别算法可以预测消息是否为 spam (垃圾邮件)或者 not_spam (非垃圾邮件)。spam 是标签之一,从电子邮件中收集的单词袋构成了输入数据的特征。当以数学方式表达此问题时,这个标签被称为 y 并且特征被称为 x 。公式是 P(y|x),它用于表示“在给定x情况下的y发生的概率”,在前述问题情况下,这将转换为“判断给定包含的单词下,电子邮件是垃圾邮件的概率”。
因此,判别算法是将特征映射到标签。他们只关心这种相关性。 而生成算法是做相反的事情。 他们尝试预测给定某个标签的特征,而不是预测给定某些特征的标签。
生成算法试图回答的问题是:假设这封电子邮件是垃圾邮件,这些特征的可能性有多大? 虽然判别模型关心的是 y 和 x 的关系,生成模型关心的是“你怎样得到 x 的”,然后得到 P(x|y) ,意思是给定 y 条件下的 x 发生的概率,或叫给定一个类的特征的概率。(也就是说,生成算法也可以用作分类器。恰好它们能做的不仅仅是对输入数据进行分类)
另一种思考方式是将判别与生成区分开来,如下所示:
判别模型学习类之间的界限。
生成模型对单个类的分布进行建模。
GANs是如何工作的
生成器,是一个用来生成新的数据实例的神经网络;鉴别器,则是用来评估其真实性的神经网络。即,鉴别器决定它所审查的每个数据实例是否属于实际训练数据集。
让我们做些比模仿蒙娜丽莎要平庸的事情。我们将生成类似于MNIST数据集的手写数字,该数据集取自真实世界。 当从真实的MNIST数据集中显示实例给鉴别器时,鉴别器的目标是将它们识别为真的。
与此同时,生成器在创建新的图像,并将其传递给鉴别器。这样做是希望它们也能被认为是真实的,即使它们是假的。生成器的目标是生成可通过检测的手写数字,以便在即使说谎下也不被抓住。 鉴别器的目标是将来自生成器的图像识别为假的。
以下是生成对抗网络运行的步骤:
生成器接收一系列随机数并返回一张图像。
将生成的图像与从实际数据集中获取的图像流一起送到鉴别器中。
鉴别器接收真实和假图像并返回概率值,这是一个介于0和1之间的数字,1代表为真,0则代表假。
所以就会有一个双重反馈回路:
鉴别器处在包含图像真相的反馈回路中。
生成器处在鉴别器的反馈回路中。
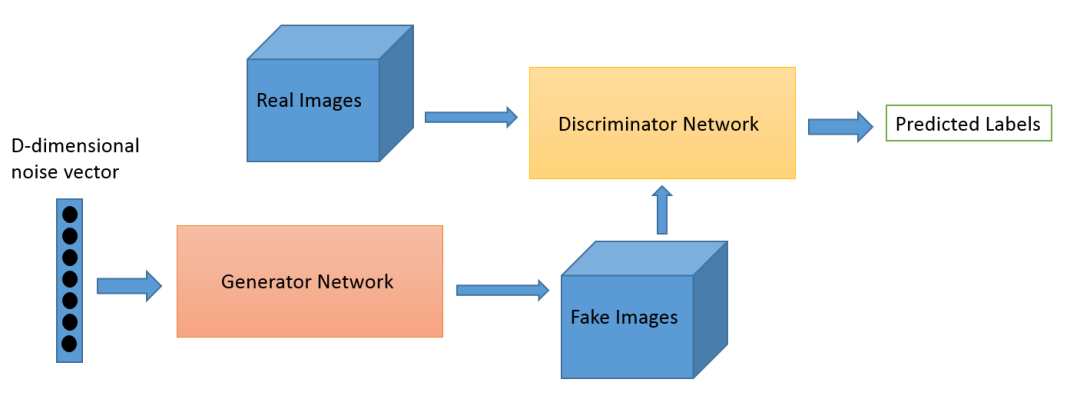
图像来源: O’Reilly
你可以认为GAN是猫鼠游戏中伪造者和警察的组合,伪造者在学习传递假钞,警察在学习检测假钞。两者都是动态的;也就是说,警察也在接受培训(也许中央银行正在标记漏报的账单),双方都在不断升级中学习对方的方法。
鉴别器网络是标准的卷积网络,它可以将馈送给它的图像分类,它用二项式分类器标记图像是真的还是假的。从某种意义上说,生成器是一个反向卷积网络:当标准卷积分类器获取图像并对其进行下采样以产生概率时,发生器获取随机噪声向量并将其上采样得到图像。第一个通过下采样技术(如maxpooling)丢弃数据,第二个生成新数据。
两个网络都试图在零和博奕中优化不同的且对立的目标函数,或者说损失函数。这本质上是一个演员-评论模型。当鉴别器改变其行为时,生成器也随之改变,反之亦然。他们的损耗也相互抗衡。
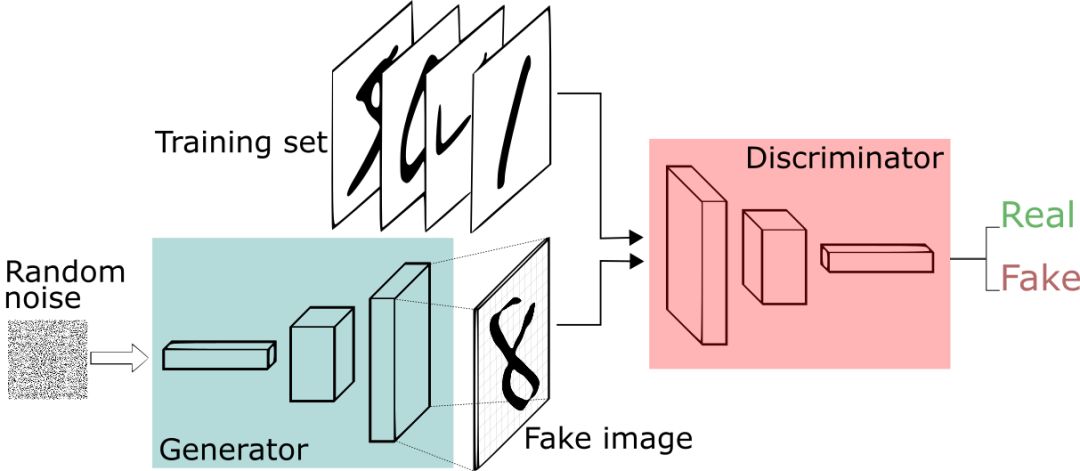
如果你想了解更多关于生成图像的信息,Brandon Amos写了一篇关于将图像解释为概率分布样本的文章。
GANs、自动编码器和变分自编码器(VAE)
将生成对抗性网络与其他神经网络(如自动编码器和变分自动编码器)进行比较会是有帮助的。
自动编码器将输入数据编码为向量。它创建原始数据的隐藏或压缩表示。这在降维方面很有用;也就是说,用作隐藏表示的向量将原始数据压缩成一个较小的主要维度。自动编码器可以与所谓的解码器配对,这允许基于隐藏的表示来重建输入数据,这和受限玻尔兹曼机是相同的。
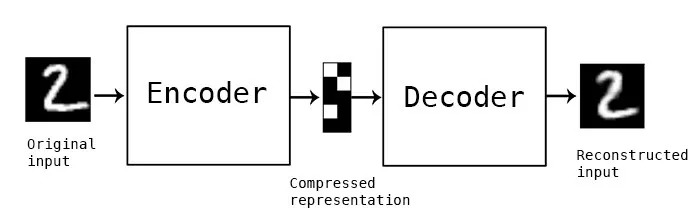
图片来源: Keras博客
变分自动编码器是一种生成算法,它为输入数据的编码增加了一个额外的约束,即把隐藏表示标准化。变分自动编码器既能像自动编码器一样压缩数据,又能像GAN一样合成数据。然而,虽然GANs能以精细、细致的细节生成数据,VAEs生成的图像则往往更加模糊。Deeplearning4j’s包中包括自动编码器和变分自动编码器。
生成算法可分成三种类型:
给定一个标签,他们预测相关的特征(朴素贝叶斯)
给定一个隐藏表示,预测相关的特征( 变分自编码器,生成对抗网络 )
给定一些特征,预测其余特征(修复、插补)
训练生成对抗网络的技巧
训练鉴别器时,保持生成器的值不变;训练生成器时,则保持鉴别器不变。这使生成器能够更好地读取它必须学习的梯度变化。
同样,在开始训练生成器之前,要对用于MNIST数据集的鉴别器进行预训练,这可以建立一个更佳清晰的梯度。
生成对抗网络的每一方都可以压制另一方。如果鉴别器太好,它将返回非常接近0或1的值,以至于生成器将难以读取梯度。如果生成器太好,它会持续利用鉴别器中的弱点导致漏报情况。这可以通过网络各自的学习率来缓解这种压制。
GANs需要很长时间来训练。在单个GPU上,GAN可能需要几个小时,而在单个CPU上可能需要一天以上的时间。尽管GANs很难调整,因此也很难使用,但它激发了许多有趣的研究和写作。
直接展示下代码吧
以下是用Keras编码的GAN示例,可以将模型导入Deeplearning4j。
class GAN():
def __init__(self):
self.img_rows = 28
self.img_cols = 28
self.channels = 1
self.img_shape = (self.img_rows, self.img_cols, self.channels)
optimizer = Adam(0.0002, 0.5)
# Build and compile the discriminator
self.discriminator = self.build_discriminator()
self.discriminator.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
# Build and compile the generator
self.generator = self.build_generator()
self.generator.compile(loss='binary_crossentropy', optimizer=optimizer)
# The generator takes noise as input and generated imgs
z = Input(shape=(100,))
img = self.generator(z)
# For the combined model we will only train the generator
self.discriminator.trainable = False
# The valid takes generated images as input and determines validity
valid = self.discriminator(img)
# The combined model (stacked generator and discriminator) takes
# noise as input => generates images => determines validity
self.combined = Model(z, valid)
self.combined.compile(loss='binary_crossentropy', optimizer=optimizer)
def build_generator(self):
noise_shape = (100,)
model = Sequential()
model.add(Dense(256, input_shape=noise_shape))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(1024))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(np.prod(self.img_shape), activation='tanh'))
model.add(Reshape(self.img_shape))
model.summary()
noise = Input(shape=noise_shape)
img = model(noise)
return Model(noise, img)
def build_discriminator(self):
img_shape = (self.img_rows, self.img_cols, self.channels)
model = Sequential()
model.add(Flatten(input_shape=img_shape))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(256))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(1, activation='sigmoid'))
model.summary()
img = Input(shape=img_shape)
validity = model(img)
return Model(img, validity)
def train(self, epochs, batch_size=128, save_interval=50):
# Load the dataset
(X_train, _), (_, _) = mnist.load_data()
# Rescale -1 to 1
X_train = (X_train.astype(np.float32) - 127.5) / 127.5
X_train = np.expand_dims(X_train, axis=3)
half_batch = int(batch_size / 2)
for epoch in range(epochs):
# ---------------------
# Train Discriminator
# ---------------------
# Select a random half batch of images
idx = np.random.randint(0, X_train.shape[0], half_batch)
imgs = X_train[idx]
noise = np.random.normal(0, 1, (half_batch, 100))
# Generate a half batch of new images
gen_imgs = self.generator.predict(noise)
# Train the discriminator
d_loss_real = self.discriminator.train_on_batch(imgs, np.ones((half_batch, 1)))
d_loss_fake = self.discriminator.train_on_batch(gen_imgs, np.zeros((half_batch, 1)))
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
# ---------------------
# Train Generator
# ---------------------
noise = np.random.normal(0, 1, (batch_size, 100))
# The generator wants the discriminator to label the generated samples
# as valid (ones)
valid_y = np.array([1] * batch_size)
# Train the generator
g_loss = self.combined.train_on_batch(noise, valid_y)
# Plot the progress
print ("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[1], g_loss))
# If at save interval => save generated image samples
if epoch % save_interval == 0:
self.save_imgs(epoch)
def save_imgs(self, epoch):
r, c = 5, 5
noise = np.random.normal(0, 1, (r * c, 100))
gen_imgs = self.generator.predict(noise)
# Rescale images 0 - 1
gen_imgs = 0.5 * gen_imgs + 0.5
fig, axs = plt.subplots(r, c)
cnt = 0
for i in range(r):
for j in range(c):
axs[i,j].imshow(gen_imgs[cnt, :,:,0], cmap='gray')
axs[i,j].axis('off')
cnt += 1
fig.savefig("gan/images/mnist_%d.png" % epoch)
plt.close()
if __name__ == '__main__':
gan = GAN()
gan.train(epochs=30000, batch_size=32, save_interval=200)

图片提供:《纽约客》
生成对抗网络的学习资源
生成性学习算法 —吴恩达斯坦福学习笔记
鉴别器与生成器:逻辑回归与朴素贝叶斯比较。作者:Andrew Ng和Michael I. Jordan
生成对抗网络背后的数学

生成对抗网络应用案例
文本到图像的生成
图像到图像的转换
图像分辨率的提高
预测下一个视频帧
关于生成对抗网络的著名论文
生成对抗网络(Ian Goodfellow的突破性论文)
未分类论文和资源
GAN Hacks:如何训练GAN?让GAN发挥作用的技巧和诀窍
使用拉普拉斯金字塔形的对抗网络的深层生成图像模型
对抗性自动编码器
基于深度网络生成具有感知相似性度量的图像
用循环对抗网络生成图像
自然图像流形上的生成视觉操纵
学习什么和在哪里画
草图检索的对抗训练
使用样式和结构对抗网络的生成图像建模
生成对抗网络作为能量模型的变分训练(ICLR2017)
基于深度生成网络合成神经元的首选输入
SalGAN:利用生成对抗网络的视觉显著性预测
对抗性特征学习
高质量图像的生成
采用深度卷积生成对抗网络的无监督表示学习(使用卷积网络的GAN ) ( ICLR )
生成对抗文本到图像合成
改进的生成对抗网络技术(Goodfellow的论文)
即插即用生成网络:潜在空间图像的条件迭代生成
StackGAN:采用生成对抗网络的文本到照片般真实的图像合成与叠加
对Wasserstein 生成对抗网络的改进训练
边界均衡生成对抗网络在Tensorflow中的实现
生成对抗网络的质量、稳定性和变异性的稳步增长
半监督学习
半监督文本分类的对抗训练方法(IanGoodfellow论文)
训练GAN的改进技术(Goodfellow论文)
分类生成对抗网络的无监督和半监督学( ICLR )
具有生成域自适应网络的半监督QA(ACL 2017)
合奏
AdaGAN:提升生成模型(谷歌大脑)
聚类
采用分类生成对抗网络的无监督和半监督学习(ICLR)
图像混合
GP-GAN:高分辨率图像混合的实现
图像修复
具有感知和上下文损失的语义图像修复(CVPR 2017)
上下文编码器:通过修复进行特征学习
采用上下文条件生成对抗网络的半监督学习
面部生成的实现(CVPR2017)
全球和本地一致的图像完成(SIGGRAPH 2017)
联合概率
对抗学习推论
超分辨率
经过深度学习的超分辨率图像重建(仅适用于面部数据集)
使用生成对抗网络生成照片般真实的超分辨率图像(使用深度残留网络)
EnhanceGAN
去遮挡
采用鲁棒性好的LSTM自动编码器在野外去除遮挡
语义分割
用于乳腺肿块分割的对抗性深层结构网络
使用对抗网络的语义分割(Soumith的论文)
对象检测
用于小物体检测的感知生成对抗网(CVPR 2017)
A-Fast-RCNN:通过对抗进行对象检测的硬件生成(CVPR2017)
RNN - GANs
C-RNN-GAN:具有对抗训练的连续递归神经网络
条件对抗网络
条件生成对抗网络
InfoGAN:利用信息最大化生成对抗网络的可解释表示学习
辅助分类生成对抗网络的条件图像合成(GoogleBrain ICLR 2017)
像素级区域转移
用于图像编辑的可变条件生成对抗网络
即插即用生成网络:潜在空间图像的条件迭代生成
StackGAN:采用生成对抗网络的文本到照片般图像的合成与叠加
MaskGAN:通过填写_______更好地生成文本(Goodfellow论文)
视频预测和生成
基于均方误差的深度multi-scale视频预测(Yann LeCun的论文)
使用场景动态生成视频
MoCoGAN:使用分解动作及内容生成视频
纹理合成和样式转换
预计算实时纹理合成与马尔可夫生成对抗网络(ECCV 2016)
图像翻译
无监督的跨领域图像生成
基于条件对抗网进行图像到图像的转译
学习使用生成对抗网络探索跨域之间的关系
使用循环一致对抗网络对不成对图像间的转译
CoGAN:耦合生成对抗网络(NIPS 2016)
基于生成对抗网络的无监督图像间转译
无监督图像间转译网络
三角生成对抗网络
生成对抗网络理论
基于能量的生成对抗网络(Lecun论文)
改进的训练生成对抗网络技术(Goodfellow的论文)
模式正则化生成对抗网络(Yoshua Bengio,ICLR 2017)
利用去噪特征匹配改进生成对抗网络(Yoshua Bengio,ICLR 2017)
采样生成网络
如何生成对抗网络
训练生成对抗网络的原则性方法(ICLR 2017)
生成对抗网络的展开论述(ICLR 2017)
最小二乘生成对抗网络(ICCV 2017)
Wasserstein 生成对抗网络
Wasserstein 生成对抗网络的改进训练(改进wgan)
训练生成对抗网络的原则方法
生成对抗网的泛化与均衡(ICML 2017)
三维生成对抗网络
通过三维生成对抗建模学习对象形状的概率潜在空间(2016 NIPS)
用于新型3D视图合成的Transformation-Grounded图像生成网络(CVPR 2017)
音乐
MidiNet:一维和二维条件下音符生成的卷积生成对抗网络
面部生成和编辑
使用已学习的相似性度量对像素进行自动编码
耦合生成对抗网络(NIPS)
用于图像编辑的可变条件生成对抗网络
为面部属性操作学习残留图像(CVPR 2017)
采用Introspective对抗网络的神经图像编辑(ICLR 2017)
使用内在图像解缠的神经面编辑(CVPR 2017)
GeneGAN:从不成对数据中学习对象变形和属性子空间(BMVC 2017)
脸部旋转:用于正面视图合成的全局及局部感知生成对抗网络(ICCV 2017)
对于离散分布
最大似然扩张离散生成对抗网络
Boundary-Seeking生成对抗网络
采用Gumbel-softmax分布的离散生成对抗网络
改进分类器和识别器
用于多类开放集分类的生成OpenMax(BMVC 2017)
对抗性特征学习的可控不变性(NIPS 2017)
生成对抗网络生成未标记样例改善行人重识别基线(ICCV2017)
通过对抗训练从模拟和非监督图像中学习(Apple论文,CVPR 2017年最佳论文)
项目
对抗机器学习库cleverhans
重置-CPPN-生成对抗网络-Tensorflow(使用残余生成对抗网络和变分自动编码器技术生成高分辨率图像)
HyperGAN(专注于规模和可用性的开源GAN)
教程
[1] Ian Goodfellow的生成对抗网络幻灯片(NIPS Goodfellow Slides)[中文翻译版]
[2] PDF(NIPS Lecun 幻灯片)
[3]关于GANS的ICCV 2017教程
想要继续查看该篇文章更多代码、链接和参考文献?
戳链接:
http://www.gair.link/page/TextTranslation/1050
AI研习社每日更新精彩内容,点击文末【阅读原文】即可观看更多精彩内容:
卷积神经网络(CNN) 详解及资料整理
从贝叶斯角度思考神经网络
如何将你的神经网络速度提高 10 倍
等你来译:
用卷积 LSTM 来预测海水温度(上)
用卷积 LSTM 来预测海水温度(下)


