赛尔原创 | ACL 2019 检索增强的对抗式回复生成
论文名称:Retrieval-Enhanced Adversarial Training for Neural Responce Generation
论文作者:朱庆福,崔磊,张伟男,韦福如,刘挺
原创作者:哈工大SCIR 博士生 朱庆福
论文链接:https://arxiv.org/abs/1809.04276
1. 简介
对话系统旨在根据用户的输入消息,返回语法流畅、语义相关的回复。现有的对话系统大体可以分为以下两类:检索式对话系统和生成式对话系统。其中,检索式系统根据输入消息,在一个预先构建的回复集合中选择和该消息最匹配的回复返回给用户,回复集合中的回复大多由人工撰写。因此,检索式方法的回复流畅性好,多样性强。但由于所有的回复均事先存在,该方法不能给出回复集合外的新回复。与之相对的生成式方法,可以根据用户输入消息进行定制。但是,现有的基于Sequence to Sequence的方法倾向于生成一般性的万能回复,多样性较差。为结合这两类方法的优点,前人提出了一些检索增强的回复生成模型,使用检索式方法得到的候选回复来提升生成式方法的生成质量。但这些方法仍存在着以下两个问题:一方面,极大似然损失与真实回复质量一致性较差,同时不能准确评价候选回复在生成过程中是否被正确使用。另一方面,候选回复包含着多样的表述形式和丰富的内容,它们不仅仅提供了生成的额外材料,还为判别回复质量提供了参考,但现有方法却没有将其充分利用。
为解决上述问题,我们提出了检索增强的对抗式回复生成模型。如图1所示,该模型主要包含以下几个模块:
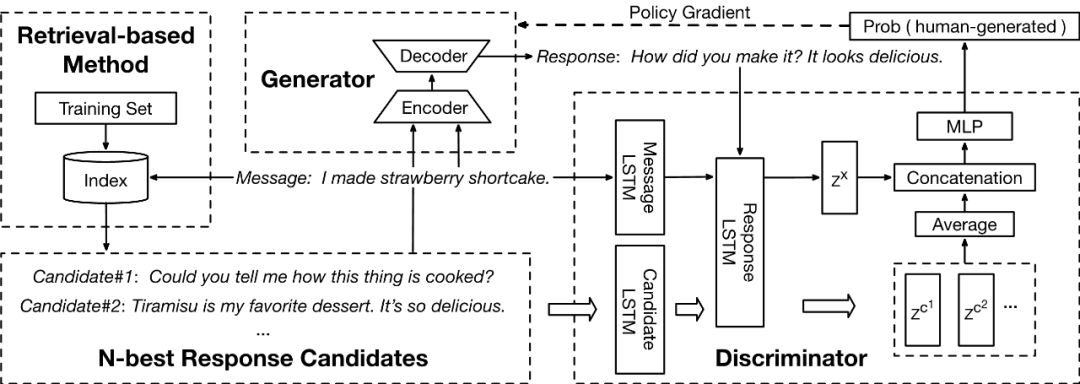
图1 检索增强的对抗式回复生成结构示意图
检索模块:给定用户的输入消息,该模块在训练集中经由检索、重排序,得到N-best候选回复。
生成器:生成器是一个Sequence to Sequence模型,它接收输入消息和上一步产生的N-best候选回复作为输入,然后生成相应的回复。
判别器:判别器本质上是一个二元分类器,用于判断一个回复是人生成的还是机器生成的。具体地,我们在判别过程中引入N-best候选回复作为参考,计算得到一个candidate-aware的回复表示。然后我们将该表示结合消息表示作为输入,经由多层感知机预测出回复是人生成的概率。
在训练过程中,生成器和判别器首先分别进行预训练,然后进行对抗训练。
2. 实验
我们的方法使用检索得到的候选回复提升对抗式回复生成模型的效果。首先我们验证了候选回复对于判别器准确率的提升,如图2所示:
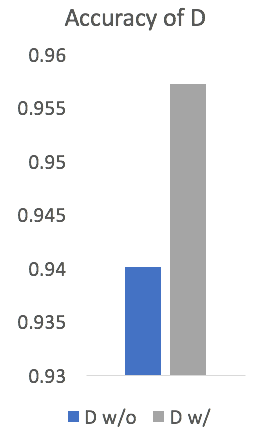
图2 检索增强的判别器判别准确率
其中,D w/o和D w/分别表示判别器中不使用和使用候选回复。从图中我们可以看出,在判别器中引入候选回复有助于提升判别器的准确率。在对抗训练下,判别器的提升又会进一步促进生成器的提升,图3展示了自动评价指标的变化情况:
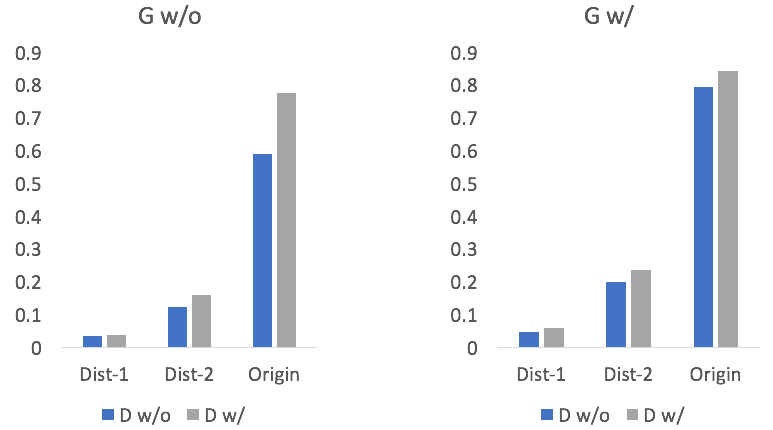
图3 检索增强的判别器下生成器的自动评价结果
其中,G w/o和G w/分别表示生成器中不使用和使用候选回复两种设置。可以看出,两种设置下判别器中引入候选回复均会带来相应的提升。类似地,我们还分析了候选回复对于生成器的增强效果,如图4所示:
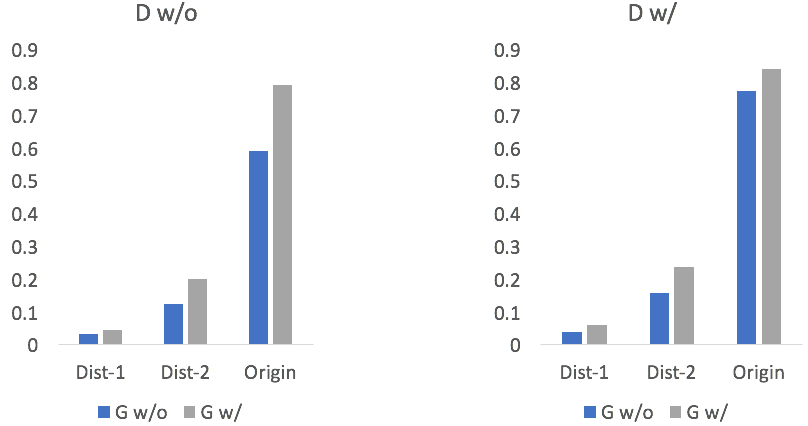
图4 检索增强的生成器自动评价结果
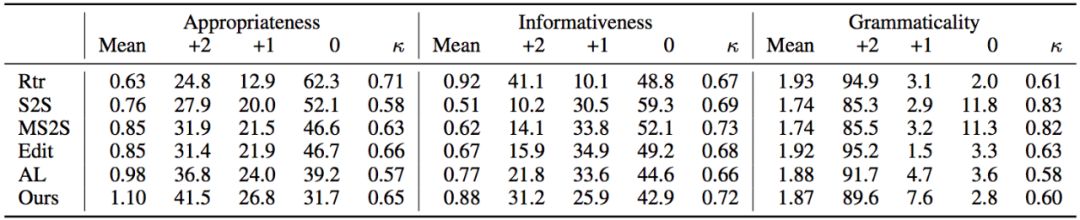
此外,我们还从合适程度、多样程度、流畅程度三个方面进行了人工评价,共有三位标注者独立地对每一个回复从0到2进行评分,结果如表1所示,我们的方法取得了最佳的合适程度评分以及优于其他生成式方法的多样程度评分。
表1 人工评价结果表
3 总结
我们提出了一种检索增强的对抗式回复生成模型,利用检索式方法得到候选回复增强判别器和生成器,并借助对抗式训练使用提升了的判别器更进一步地促进了生成器的提升。候选回复可以近似地看做为一种非结构化的外部知识,后续我们可能会探索在对抗式框架下如何同时引入知识图谱作为结构化的外部知识得到更高质量的回复。
本期责任编辑:张伟男
本期编辑:李照鹏
“哈工大SCIR”公众号
主编:车万翔
副主编:张伟男,丁效
责任编辑:张伟男,丁效,崔一鸣,李忠阳
编辑:李家琦,赖勇魁,王若珂,李照鹏,冯梓娴,顾宇轩


