

论文题目:Schema-adaptable Knowledge Graph Construction **本文作者:**叶宏彬(之江实验室)、桂鸿浩(浙江大学)、徐欣(浙江大学)、陈华钧(浙江大学)、张宁豫(浙江大学) **发表会议:**EMNLP 2023 论文链接:https://arxiv.org/pdf/2305.08703.pdf
**代码链接:**https://github.com/zjunlp/AdaKGC
欢迎转载,转载请注明出处****

引言
传统的知识图谱构建(KGC)方法通常遵循静态信息提取范式,只能通过预定义的 schema 处理固定数量的类别,并在固定框架上进行一次性的训练。结果是,当应用于动态场景或新类型知识出现的领域时,这种方法会显得力不从心。这就需要一个系统能够自动处理不断演化的模式,以提取用于 KGC 的信息。为了满足这一需求,本文提出了一个新的任务,称为自适应 schema 的KGC,旨在基于动态变化的 schema 不断提取实体、关系和事件信息,无需重新训练。本文首先根据三个原则拆分并转换现有数据集以构建基准,即水平 schema 扩展、垂直 schema 扩展和混合 schema 扩展;然后调查了几种众所周知的方法如 Text2Event、TANL、UIE 和 GPT-3.5 的自适应 schema 性能。本文还提出了一个简单而有效的基线,名为AdaKGC,它包含了 schema 增强的前缀指令器和基于字典树的动态解码,以更好地处理演化中的 schema。全面综合的实验结果表明 AdaKGC 能够胜过基准方法,但仍有改进空间。
方法
任务定义
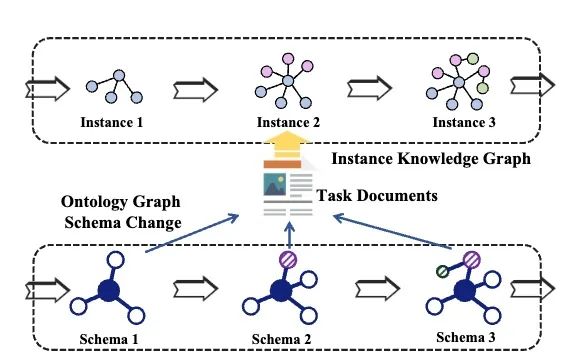
在现实世界中,KGC 系统从非结构化文本中提取结构化知识,并根据频繁调整的 schema (实体类型、关系类型、事件字典等)将其规范化为实例图。给定一组 schema ,其中,n是迭代次数(本文取7)。自适应 schema 的 KGC 任务是为每个迭代生成一组 schema 约束实例 。假设有一个在初始训练集上训练的模型 ,一个可适应模式的数据流 被提供用于评估模型对 schema 动态更新的适应性。每个 包含开发/测试数据 和 schema 。请注意,模型将不会重新训练,但希望模型能够学会随着模式演变的信息提取能力。
数据集构建
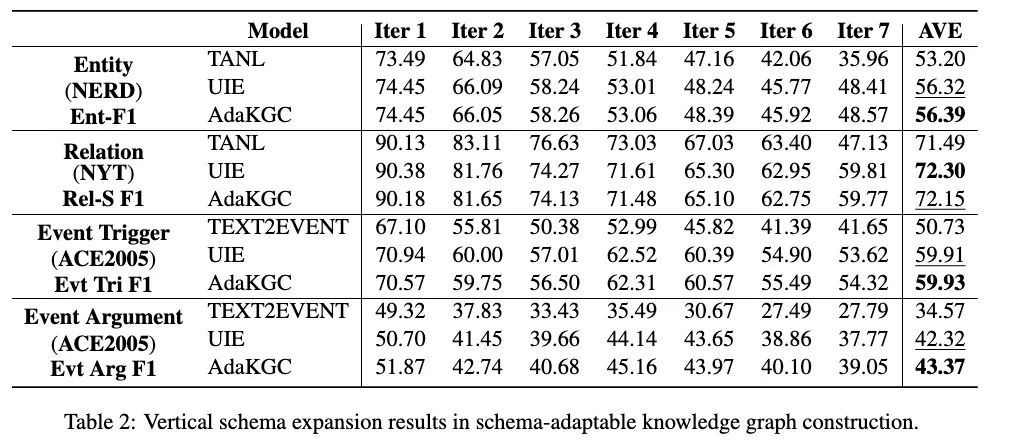
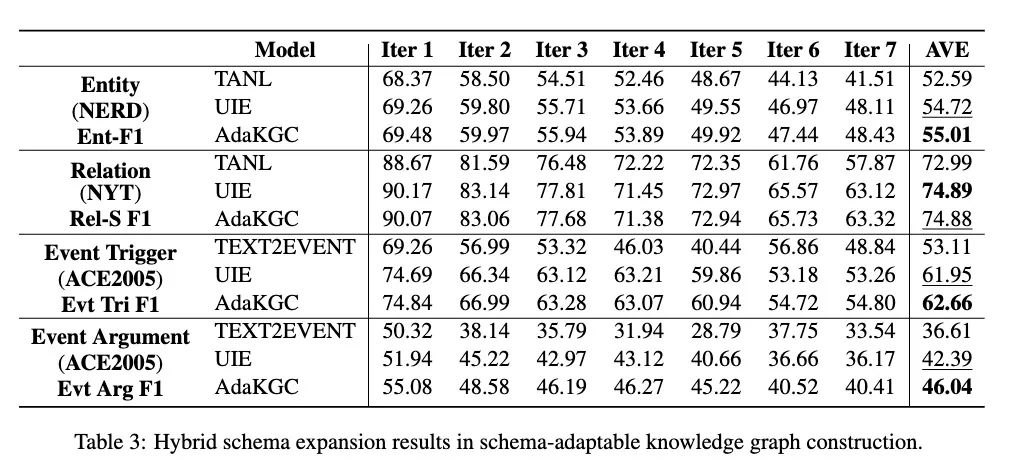
由于缺乏相应的动态变化数据集,本文提出从现有的数据集中动态构建出用于自适应 schema 的KGC任务的数据集。如图 2 所示,本文设计了三个不同类型的 schema 演变的原则:(1)水平 scheme 扩展:要求scheme添加同一级别的新类节点,这可以被认为是一种类增量学习,无需新类实例作为训练数据。基于对邻近新类的泛化效果,可以评估 scheme 特征的迁移能力。(2)垂直 scheme 扩展:要求 schema 添加父类的子类。基于对子类的泛化效果,可以评估 schema 特征的继承和衍生能力。(3)混合 schema 扩展:要求模式在每个迭代中随机水平或垂直扩展节点,这总结了模式图并代表了它们潜在的共同演化模式。除了上述结构扩展外,本文还从语义的角度探索了同义词节点的替换。最终,本文分别在 Few-NERD、NYT、ACE2005 上为 NER、RE、EE 三种任务构建了水平、垂直、混合 schema 扩展迭代数据集。
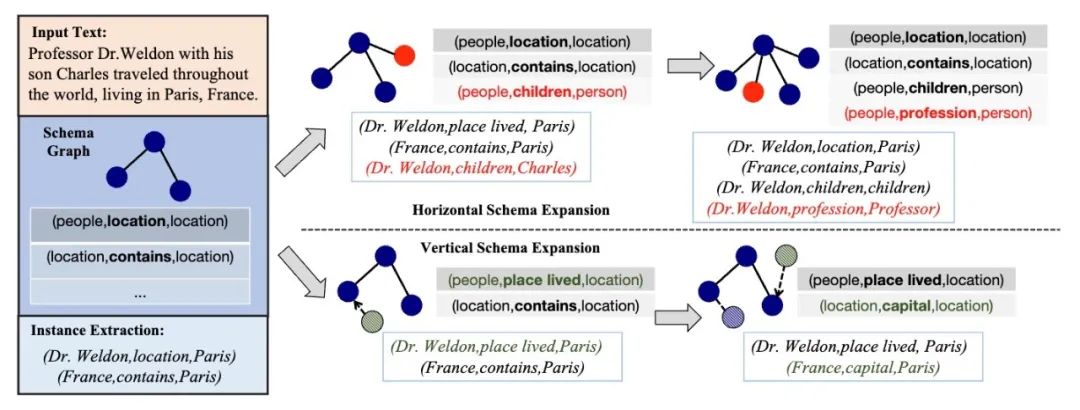
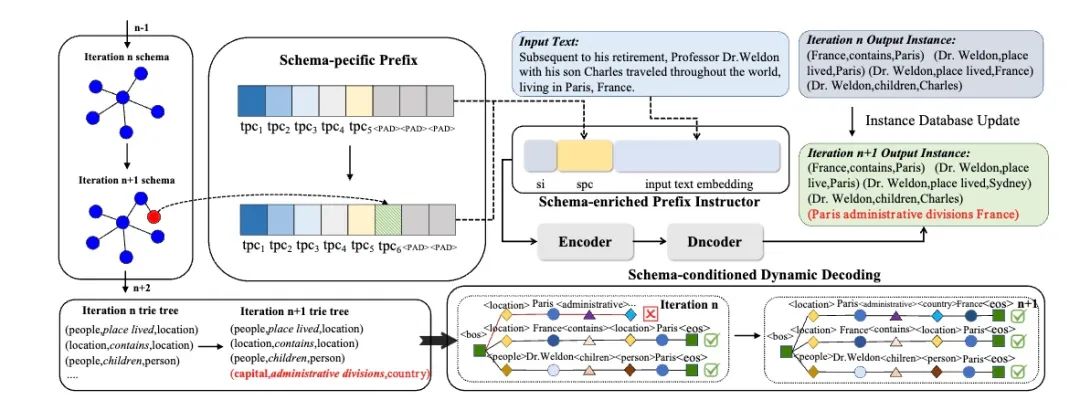
图一:schema 图中的节点(标记为深蓝色)通过在水平 schema 扩展中添加一个新的类节点(标记为红色)而进化,而在垂直 schema 扩展中则由一个新的子类节点 (标记为深绿色)继承。 模型 AdaKGC 使用预训练的编码器-解码器语言模型T5作为基础模型。受prefix-tuning的启发,本文使用特定于任务的前缀指导器来指示任务信息。前缀指导器由可学习参数 构成,并添加到模型的每一层中。其中, 分别是用于添加到编码器和解码器的特定于任务(NER、RE、EE)的前缀, 是包含 schema 信息的前缀,以及填充码PAD。这些可学习的前缀参数均由其相应的单词表示初始化,在监督训练的过程中学习并优化。具体来说,本文按照以下步骤训练模型的参数:(1)首先,冻结其他参数,微调前缀指导器 学习特定于任务的提示;(2)其次,冻结 ,优化特定于schema 的指导器 ;(3)最后,解冻 LM 参数 并协同优化所有参数,以捕获前缀指导器与模型参数之间的关联。 本文在解码过程中还应用了基于字典树的解码机制,该机制通过利用最新的schema动态构建一个字典树。在解码每个token时,可选择的范围都被限制在这颗字典树中,因此极大的降低了搜索空间,以确保生成的 token 是有效的,从而提高生成准确率。AdaKGC具体实例如图3所示。
实验
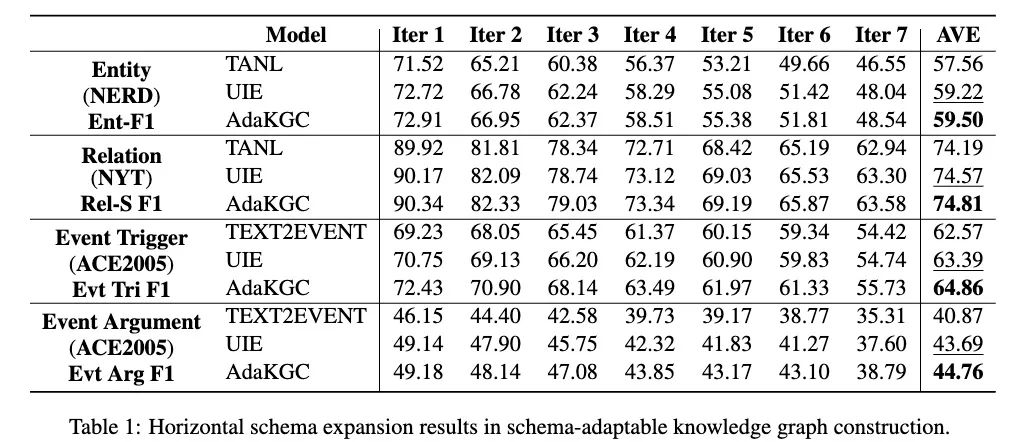
实验部分本文采用了UIE、Text2Event、TANL作为基线对比。图4、5、6分别显示了在水平、垂直、混合扩展设定下的结果。可以看到在所有三个扩展类别上,模型性能随着迭代次数的增加而趋于下降。TANL实现了较低的性能,它采用了增强的语言并隐式地训练模型以学习模式信息。TEXT2EVENT 利用模式作为解码侧的约束信息,并在一些迭代中优于其他模型。尽管 AdaKGC 和 UIE 获得了最优或次优性能,但第1次迭代和第7次迭代的性能有显著下降。与其他模型相比,AdaKGC 在编码器和解码器上都改进了模式增强模块,这使其在大多数设置中都能达到最佳性能。在 ACE2005 混合模式扩展数据集上,AdaKGC 在触发器提取上提高了0.71%,在事件参数提取上提高了3.65%,这表明 AdaKGC 能够在演化的模式下捕获模式特定信息。
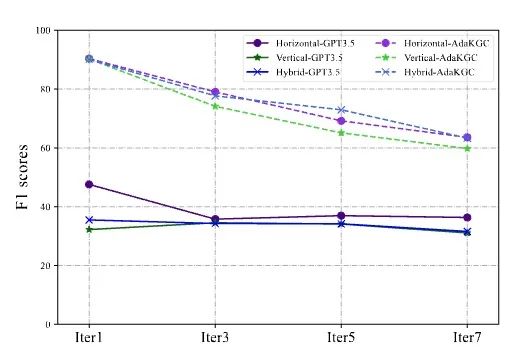
为了探索 LLMs 在自适应 schema 的KGC任务上的性能,本文利用 GPT-3.5 在 NYT 上进行了比较实验。结果如图7所示,GPT-3.5 能够生成符合动态变化 schema 的实例,但由于少样本展示的限制仍然表现低下。本文也在附录中使用ChatGPT抽样了几个案例,出人意料的是,它表现出了稳定的随着模式演变的泛化能力。
结论
本文提出了一个新的任务——自适应scheme的知识图谱构建(KGC)任务,并引入了基准数据集和一个新的基线AdaKGC。用之前的基线方法UIE、Text2Event、TANL在三种模式扩展模式(水平、垂直、混合)上说明了任务的难点,并展示了所提出的AdaKGC的有效性。尽管AdaKGC取得了一定的成果,但是仍然存在改进空间。