

论文题目:Editing Language Model-based Knowledge Graph Embeddings
本文作者:程思源(浙江大学)、张宁豫(浙江大学)、田博中(浙江大学)、陈曦(腾讯)、刘庆斌(腾讯)、陈华钧(浙江大学)****
发表会议:AAAI 2024
**论文链接:**https://arxiv.org/abs/2301.10405 **代码链接:**https://github.com/zjunlp/PromptKG/tree/main/deltaKG ****Demo链接:https://huggingface.co/spaces/zjunlp/KGEditor 欢迎转载,转载请注明出处

一、引言
知识图谱和大型语言模型都是用来表示和处理知识的手段。不同于大型语言模型,知识图谱中的知识通常是结构化的,这样的结构让其具有更强的准确性和可解释性。知识图谱嵌入(Knowledge Graph Embedding,KGE)是一种将知识图谱中的实体和关系转化为低维度、连续的向量空间表示的技术。这种转化使得复杂的关系和属性能够以向量形式表达,从而便于机器学习算法进行处理。这些技术为各种知识密集型任务(例如信息检索、问答和推荐系统)提供了宝贵的后端支持。最近的一些工作表明,基于预训练语言模型的知识图谱嵌入可以充分利用文本信息进而取得较好的知识图谱表示性能。
然而,现有的知识图谱嵌入模型一般是作为一个静态工件被部署在服务中,一经训练好知识图谱表示模型就很难适应新出现的实体以及处理事实知识发生修改的情况,比如,如果让一个在2021年以前训练的知识图谱表示模型去预测<美国、现任总统、?>,那么它最有可能给出的答案是唐纳德·特朗普。但是随着美国总统大选举行,总统换届,到2021年总统就变成了乔·拜登。因此,如何高效地修改其中过时或错误的知识成为了一个挑战。为解决这一问题,本文提出了一种基于预训练语言模型的知识图谱嵌入编辑方法——KGEditor。不同于直接编辑大型语言模型内部的知识,知识图谱嵌入编辑是针对知识图谱中的事实性知识进行操作。并且编辑知识图谱嵌入需要考虑知识的复杂结构,比如一对多,多对多等知识结构。
二、方法
2.1 任务定义
知识图谱表示为,其中代表实体的集合,代表的是关系的集合,表三元组的集合。中的每个三元组可以表示为。对于EDIT子任务,本文将需要编辑的知识定义为或者,其中是错误的或者已经过时的实体,代表编辑的目标实体。 随着外部世界的变化,需要将新的事实加入到现有KG中去。因此有必要将这些新的三元组知识灵活地插入到KGE中。所以引出了第二个子任务ADD,其目的是将前一阶段训练中没有的全新知识植入到模型中去,这类似于KG中的归纳推理设置,但是整个模型是不需要重新训练的。这两种任务示意如图所示: 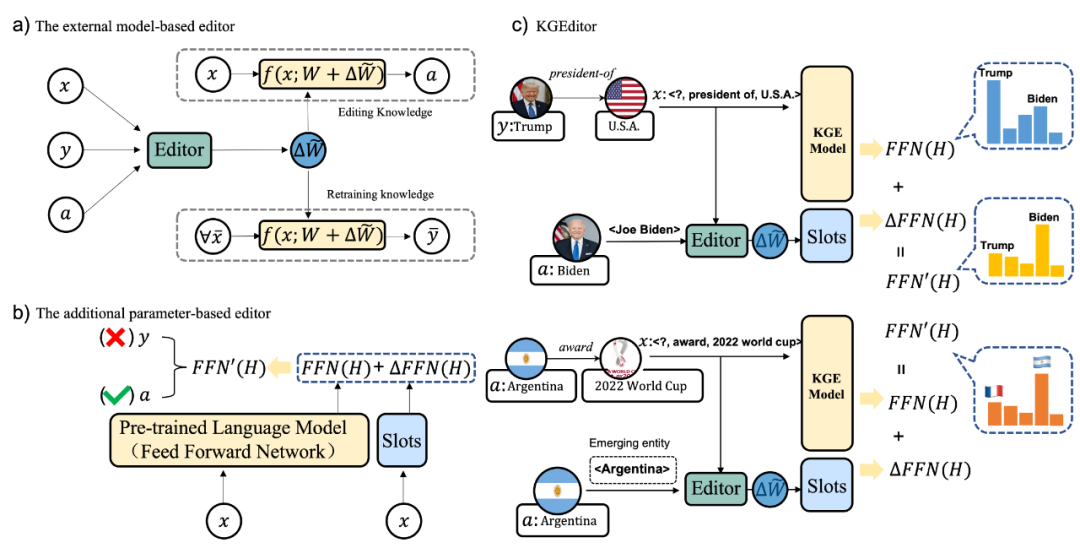
和代表的是KGE模型原始的参数和编辑后的参数,,代表输入和原本错误输出,代表更新后的知识。
2.2 Metrics
**Success@1 metric (Succ@k): **KGE编辑的可靠性是通过链接预测来判断是否将原有错误的知识成果修改回来。为了验证编辑效果的有效性,本文采用了知识图谱补全的设定,即通过对候选实体分数进行排名,生成一个实体列表。通过计算正确实体出现在位置来定义修改后的模型的可靠性,定义为Success@1 metric (Succ@k),其公式如下: **Retaining Knowledge Rate of Change: **知识稳定性是试图去评估编辑方法在成功更新特定三元组知识时,是否对知识图谱表示模型获取的其余知识带来了影响。本文这里主要采用两种评估方式来探究编辑方法对于知识图谱表示模型的影响大小,分别是知识保持率和知识的变化率。知识保持率Retain Knowledge (RK@k)代表的是原始模型预测的实体,在编辑完成后仍然能够正确推断出来的概率。首先本文设定了一个专门用于稳定性测试的数据集:L-test。L-test数据集收集了原始模型预测出来的Top 1的三元组数据,作为观测数据集。如果编辑前后的KGE模型预测相对应的三元组预测保持不变,则认为编辑遵循知识局部性,即不会影响其余事实。通过计算保留知识局部性的比例作为知识编辑稳定性的衡量标准,其定义如下所示: 其中代表从稳定性数据集中抽取出来的数据。是由或者参数化的模型函数。表示带参数的模型,预测的rank在以及以下的个数。 **Edited Knowledge Rate of Change: **为了更好观察编辑对稳定性影响的大小,本文引入了两个额外的指标来衡量编辑带来的影响大小。即编辑知识的变化率(Edited Knowledge Rate of Change)和保留知识的变化率(Retaining Knowledge Rate of Change),两个公式定义如下: 其中 和 表示编辑前后测试集的平均Rank排名。和 表示编辑前后L-Test测试数据集的平均Rank排名。
2.3 模型选择
本文采用的知识图谱嵌入模型都是基于预训练的知识图谱嵌入模型。文中将这类模型进一步细分为两种形式:其一是以KG-BERT为代表的FT-KGE(Finetuning Knowledge Graph Embedding)模型,其二是以NN-KG代表的PT-KGE(Prompt Tuning Knowledge Graph Embedding)模型。 FT-KGE,如KG-BERT,KG-BERT将KG中的三元组视为文本序列。这类方法通过对由[SEP]和[CLS]等特殊token连接的关系和实体的三元组的描述进行训练,然后将描述序列作为微调的输入。通常使用[CLS]来进行二元分类来判断三元组的合法性,注释如下: 其中,代表三元组进行二分类的结果,即是否为正确的标签。 PT-KGE,代表有PKGC和NN-KG,这类方法利用自然语言提示从预训练知识图谱表示模型中获取知识。将知识图谱补全任务转换成与预训练任务相似的完形填空任务。在NN-KG中,通过实体词表扩展来实现PT-KGE,将每个独立的实体视为公共的知识表示。具体来说是将实体视为语言模型中的特殊tokens,将链接预测转变为屏蔽实体的完形填空单词预测。形式上,可以通过对知识图中每个实体的概率进行排序来获得正确的实体,如下所示: 其中表示实体在知识图谱中的概率分布。
2.4 Datasets
为了构建知识图谱编辑数据集,本文借助了目前知识图谱中常见的两个基准数据集:FB15k237和WN18RR。 EDIT Task:未来确定编辑对象,本文收集了在KGE模型链接预测任务上具有挑战性的数据。即本文采样了链接预测中,实体排序在2,500以上的数据(模型难以预测正确的三元组补全数据)。对于稳定性测试集,本文将模型原本能够预测保持在top 的数据保留下来,做为L-test数据集。其构建的具体流程如图所示:
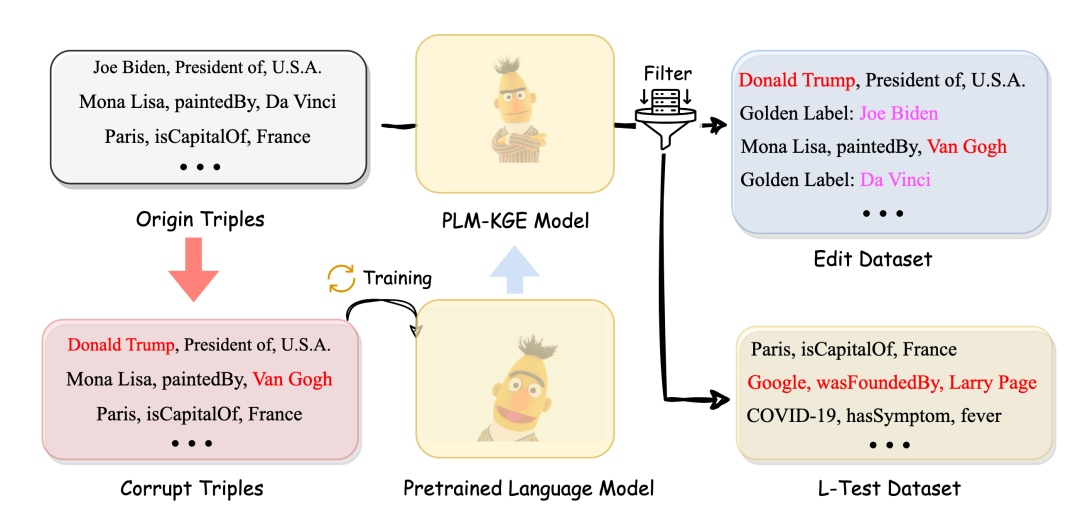
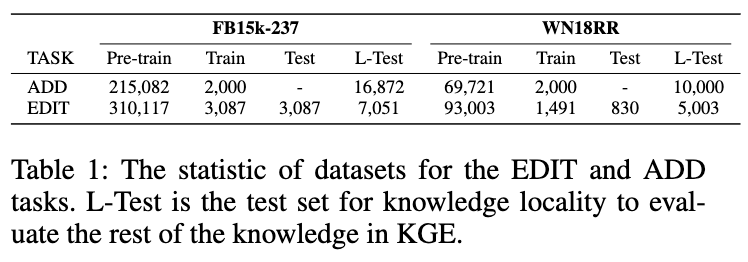
ADD Task:对于ADD任务数据集构建,本文采用了知识图谱补全任务中的归纳推理任务设定(利用已有的知识图谱中的信息来预测或推断缺失的关系和实体),测试数据集中的实体知识都是在训练中没有见过的,所以可以看作为新增的知识。 在FB15k-237和WN18RR上本文都采用相同的数据集设定,处理方式也保持一致。通过以上操作,本文最终可以得到以下四个数据集:E-FB15k237,A-FB15k237,E-WN18RR,和A-WN18RR。其中具体的统计如表所示:
2.5 KGEditor
本文首先在一些通用的知识编辑方法上进行初步的实验测定,发现现有的知识编辑方法存在以下问题。首先基于额外参数的编辑方法CaliNet不管是在Edit还是ADD任务上,表现都比较一般,其效果不如给予额外模型的编辑方法,如MEND和KE等。但是MEND和KE的编辑效率是低的,其额外模型的参数需要去生成网络参数,所以其编辑所需要训练的参数也会随着隐藏层纬度的增大而增加,不会比微调的方式更节约资源。所以本文总结两种方法的优缺点,通过综合两者的优势,提出了一个新的编辑方法:Knowledge Graph Embeddings Editor(KGEditor),其具体示意如图所示:
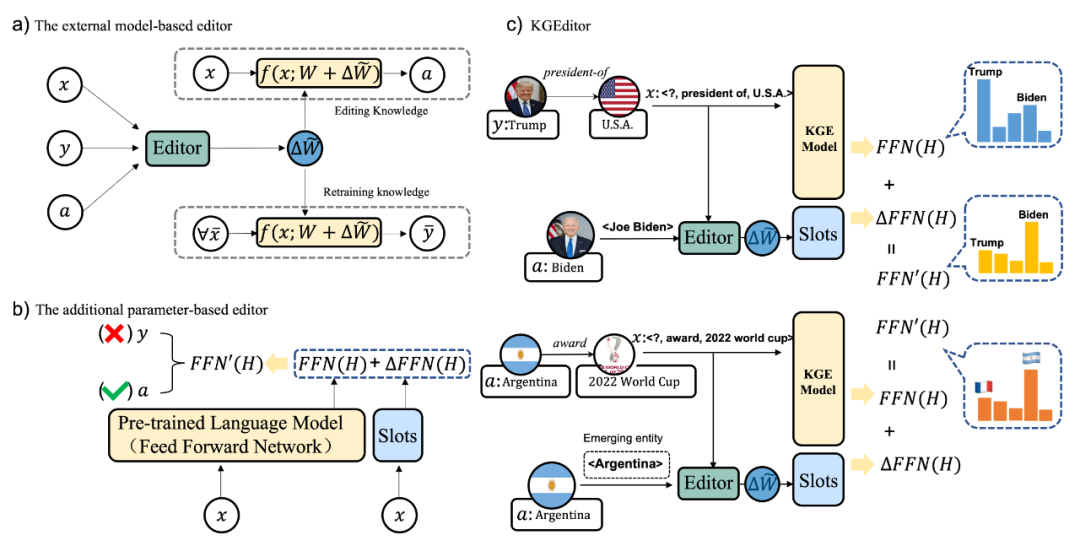
KGEditor可以在不丢失编辑性能的前提下,尽可能节约编辑的资源开销。这样可以节约更多的资源实现更加高效的编辑。直观上来讲,本文构建了一个与FFN架构相同的附加层,并利用其参数进行知识编辑。但是额外FFN层的参数不是依靠微调训练,而是利用额外的超网络来生成附加层的额外调整参数。其公式如下: 其中表示原始FFN层的模型权重,表示额外调整参数的FFN模型参数。是超网络生成的偏移参数。受到了Knowledge Editor的启发,本文采用了双向LSTM来构建超网络,本文对进行编码,然后用特殊的分隔符将它们连接起来以输入双向LSTM。本文将双向LSTM的最后隐藏状态输入MLP中,以生成用于知识编辑的单个向量。为了预测权重矩阵的移位,本文利用以为条件的MLP,预测向量 和标量,最终得到以下公式: 其中指的是Softmax函数,比如i.e., ,指的是Sigmoid函数,即。代表梯度,其中包含有关如何获取中的知识信息。其中超网络的参数是随着的大小线性缩放,使得KGEditor在计算资源和时间方面能够高效地编辑知识图谱表示。
三、实验
3.1 实验结果 本文利用现有的一些主流知识编辑范式与KGEditor进行比较,其中具体包括CALINET、MEND和Knowledge Editor。为了对照,本文对一些其他基础范式基线也进行了对比,首先是直接在少量更新知识上进行微调的范式和Zero-Shot的方法。其次对于K-Adapter这种使用额外参数的方法与CALINET进行比较,其中具体的实验结果如下所示。
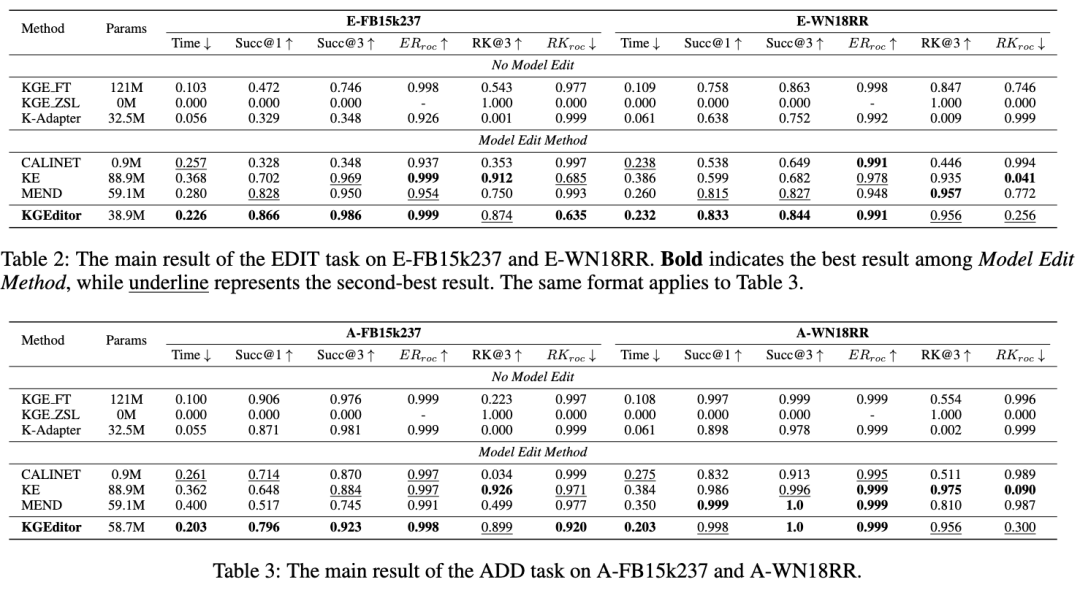
此外,本文还研究了在知识图谱表示编辑过程中,不同数量的编辑事实对模型性能的影响。通过在E-FB15k237数据集上进行不同数量编辑的实验,本文分析了编辑数量对知识可靠性和局部性的影响。其中主要关注三种模型:KE、MEND以及KGEditor在不同编辑数量下的表现,结果如下所示。
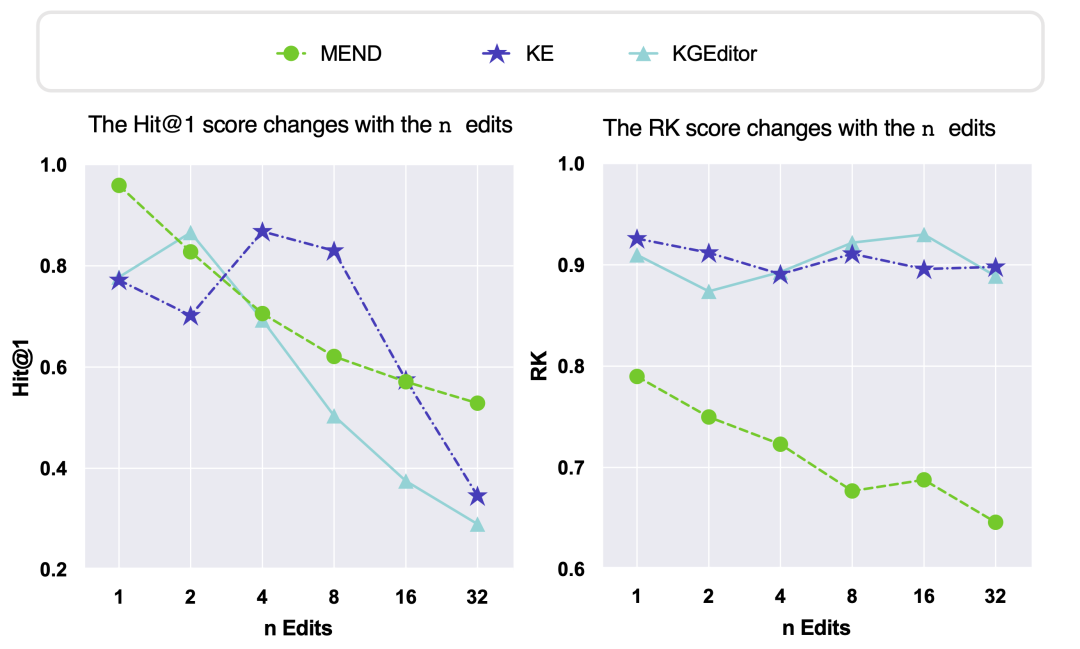
本文还探讨和评估不同基于预训练的知识图谱表示初始化方法在编辑范式上的应用效果。通过在EDIT任务上对FT-KGE和PT-KGE的方法进行实验,本文分析了它们在知识可靠性和局部性方面的性能表现,结果如图所示。
3.2 Case分析
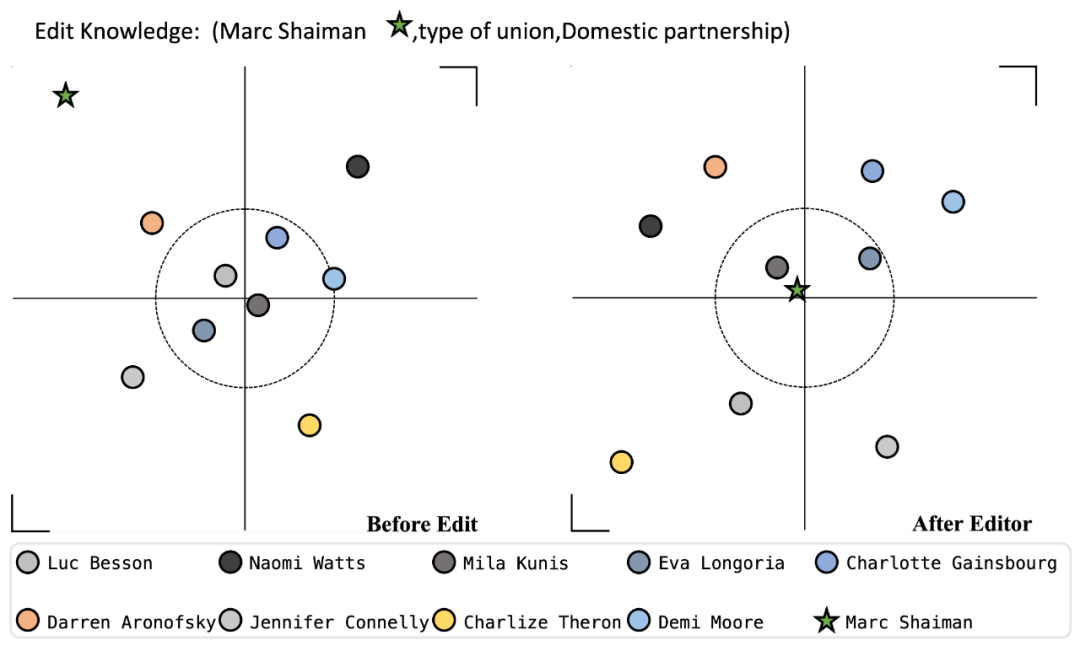
我们随机挑选了一个编辑的Case,并通过可视化展示了编辑前后的实体变化来更清晰地观察KGEditor的性能表现。下图展示了知识编辑应用前后,预测实体位置的显著变化。即在对模型进行编辑后,正确的实体明显靠近圆心,展示了编辑KGE模型的有效性。
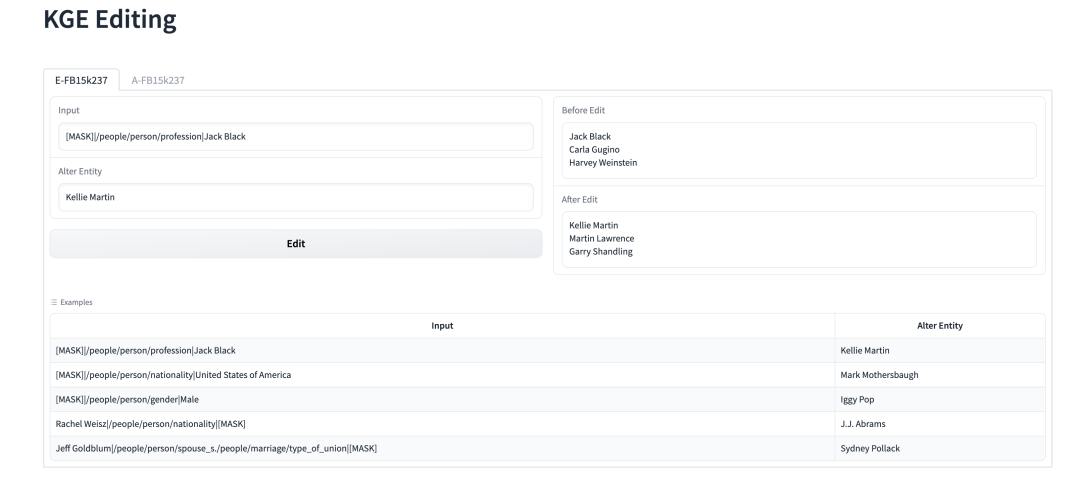
四、Demo
为了方便读者更直观了解我们的工作,我们在huggingface的Space平台,利用Gradio去搭建了一个简易Demo。我们会在结果处展示编辑前后预测实体的变化,具体如下图所示。
五、总结
本文主要介绍了知识图谱嵌入模型的编辑工作。区别于传统的编辑预训练语言模型的任务,KGE编辑是基于知识图谱中的事实性知识进行操作。此外,本文提出了一个新的编辑方法——KGEditor。KGEditor是一种高效修改模型中知识的一种方法,能够有效地节约计算资源的开销。此外,我们的工作还有一些不足之处,比如如何去编辑知识图谱中的一对多以及多对多知识?如何在KGE模型中做到持续更新?这都是一些未来的工作。
