大型语言模型(LLMs)在语言理解、生成、推理等方面展现了令人瞩目的成果,并不断推动多模态模型的能力边界。作为现代 LLM 的基础,Transformer 模型提供了具有优良扩展性的强大基线。然而,传统 Transformer 架构需要大量计算,这对大规模训练和实际部署构成了显著障碍。在本综述中,我们系统性地考察了旨在突破 Transformer 内在局限、提升效率的创新 LLM 架构。从语言建模出发,本综述涵盖了线性与稀疏序列建模方法、高效的全注意力变体、稀疏专家混合(MoE)、结合上述技术的混合模型架构,以及新兴的扩散式 LLM。此外,我们还讨论了这些技术在其他模态中的应用,并探讨了它们在开发可扩展、资源感知的基础模型中的广泛影响。通过将近期研究归纳到上述类别,本综述勾勒出现代高效 LLM 架构的蓝图,并期望能为未来迈向更高效、更通用的 AI 系统研究提供启发。 GitHub: https://github.com/weigao266/Awesome-Efficient-Arch
1 引言
1.1 背景
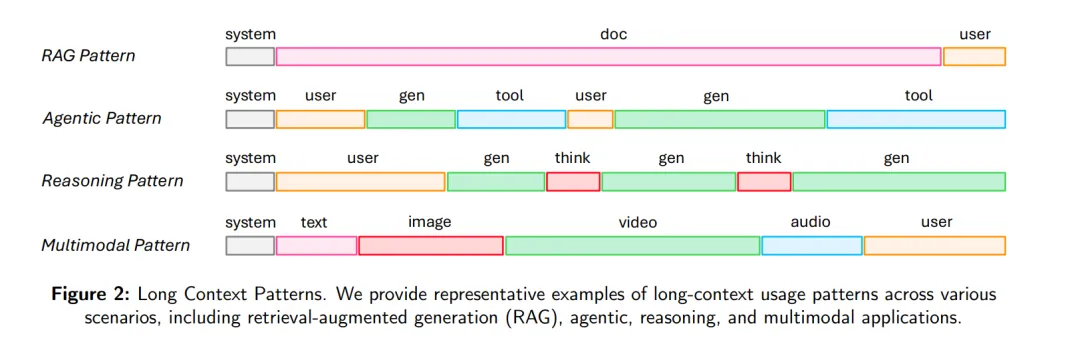
近年来,大型语言模型(Large Language Models, LLMs)在自然语言理解与生成方面展现出非凡的能力,推动了文本生成 [1, 2, 3]、代码生成 [4, 5, 6]、问答 [7, 8]、机器翻译 [3, 9] 等广泛任务的显著进展。诸如 ChatGPT [2, 10, 11, 12, 13, 14, 15, 16, 17]、Claude [18, 19, 20, 21, 22]、Gemini [23, 24, 25]、DeepSeek [26, 27, 28, 29]、Qwen [30, 31, 32, 33]、LLaMA [34, 35, 36, 37]、GLM [38]、Minimax-Text [39]、InternLM [40, 41]、混元(Hunyuan) [42, 43] 等一系列代表性 LLM 家族,不断突破性能边界,同时也重塑了人机交互的方式。 超越其在语言任务中的初始角色,LLMs 正越来越多地应用于两个高要求领域:多模态与复杂推理。在多模态应用中,LLMs 已成为整合并生成跨模态信息的核心。近期的视觉-语言模型(Vision-Language Models, VLMs)进展,如 Qwen-VL [44, 45, 46]、InternVL [47, 48, 49, 50]、Seed-VL [51]、Kimi-VL [52]、Minimax-VL [39],充分体现了这一转变,展示了通过将语言能力与视觉处理结合,显著提升跨模态理解与生成的能力。与此同时,一条快速发展的研究路径聚焦于增强 LLMs 的推理能力,通常称为大型推理模型(Large Reasoning Models, LRMs)。典型系统包括 OpenAI o1/o3 [14, 15]、DeepSeek-R1 [29]、Seed1.5-Thinking [53]、Minimax-M1 [54]、Kimi k1.5/K2 [55, 56] 等,它们引入了长链式思维链(Chain-of-Thought, CoT)提示 [57] 和强化学习(Reinforcement Learning, RL)[58] 等策略,以支持多步推理和更具深思熟虑的认知行为。 尽管 LLMs、VLMs 和 LRMs 在语言理解、多模态处理和复杂推理方面取得了重大突破,但它们也带来了巨大的计算需求 [59, 60, 61]。这种需求显著提高了开发和部署成本,从而对广泛应用构成了实际障碍。该问题在 LLMs、VLMs 和 LRMs 中普遍存在,凸显了模型能力与效率之间的权衡。虽然这些模型为通用智能的发展提供了有前景的路径,但其高昂的资源消耗也引发了一个重要问题:在追求更强大的系统时,我们是否真正考虑过这种“智能”背后的巨大隐性成本?这种“智能”的真实代价又是什么? 许多最新突破背后的核心架构是 Transformer [62],其于 2017 年提出。Transformer 的自注意力机制比传统的循环神经网络(RNNs)[63] 更有效地捕捉长程依赖,从而支持 LLMs 扩展至千亿甚至万亿级参数 [2]。然而,Transformer 的一个主要局限在于其自注意力机制的二次复杂度:计算开销随输入序列长度 N 呈 O(N²) 增长 [64]。这种低效导致训练与推理成本极其高昂,尤其在涉及长上下文输入的任务中 [65]。随着人工智能(AI)的持续发展,长序列场景正变得日益普遍。 如图 2 所示,任务如检索增强生成(Retrieval-Augmented Generation, RAG) [7] 通常要求 LLMs 处理整篇文档。在新兴的 AI 智能体(AI agents) 时代 [66],长序列经常由反复生成与多次工具调用产生。当模型具备更强推理能力(形成 LRMs)时,它们必须处理长链思维链,这同样导致长序列问题。类似地,在多模态应用中 [67],高分辨率图像、视频和音频也引入了额外的长序列挑战。Transformer 架构的另一个关键组件——前馈网络(Feed-Forward Network, FFN)[68],在模型规模扩展时同样面临挑战。当参数数量超过某个规模时,FFN 层的训练成本和推理效率将愈发难以控制。在这种情况下,新的问题出现了:我们如何突破 Transformer 的效率天花板?高昂的“智能”是否是唯一的前进道路?
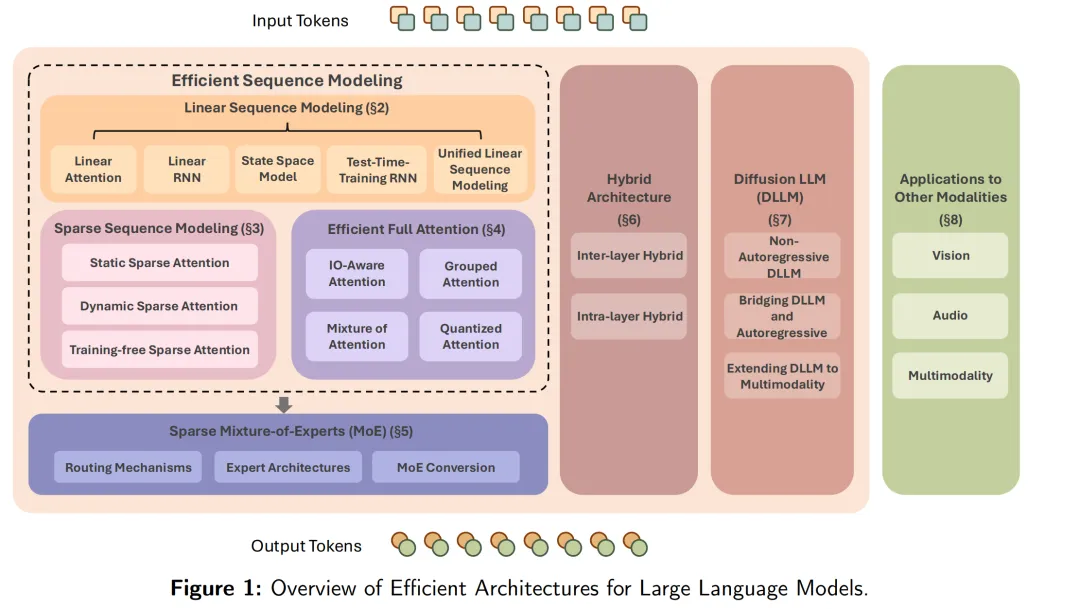
为应对这些迫切挑战并释放 LLMs 的全部潜力,研究界正在积极探索一系列创新的架构设计与优化策略。本综述深入探讨了这些创新方法,并将其系统归类,以提供全面的概览。各类别下的具体方法如图 3 所示,概括如下:
线性序列建模:通过重构注意力机制,将自注意力的二次复杂度降至线性复杂度 O(N),常借鉴传统注意力、RNN 或状态空间模型(State-Space Models, SSMs)的思想。这类方法还能消除推理阶段存储键-值(KV)缓存的需求,从而降低部署成本。
稀疏序列建模:不再计算所有 token 对之间的注意力,而是仅选择性地关注一部分交互(即注意力图),以降低计算和内存需求,同时尽力保持性能。
高效全注意力:在保持二次复杂度不变的前提下,提高标准 softmax 注意力的效率。例如,通过 IO 感知的注意力机制提升内存访问效率,或通过分组查询机制减小 KV 缓存大小。
稀疏专家混合(Sparse MoE):引入条件计算方法,每个输入 token 仅激活部分参数(称为专家),从而在不成比例增加计算开销的情况下大幅提升模型容量。
混合架构:将线性序列建模与传统全注意力层有机结合,可在同一层内实现内层混合,或在不同层之间采用跨层混合,从而平衡效率与模型容量。
扩散式 LLMs:一种新兴方向,探索基于非自回归扩散模型的语言生成,潜在地为高效且高质量的文本生成提供新途径。
跨模态应用:重要的是,这些驱动效率的架构原则并不限于语言领域;它们在视觉、音频与多模态等其他领域也展现出适应性,本综述也将对此加以探讨。