如何用Python做舆情时间序列可视化?
如何批量处理评论信息情感分析,并且在时间轴上可视化呈现?舆情分析并不难,让我们用Python来实现它吧。

(由于微信公众号外部链接的限制,文中的部分链接可能无法正确打开。如有需要,请点击文末的“阅读原文”按钮,访问可以正常显示外链的版本。)
痛点
你是一家连锁火锅店的区域经理,很注重顾客对餐厅的评价。从前,你苦恼的是顾客不爱写评价。最近因为餐厅火了,分店越来越多,写评论的顾客也多了起来,于是你新的痛苦来了——评论太多了,读不过来。
从我这儿,你了解到了情感分析这个好用的自动化工具,一下子觉得见到了曙光。
你从某知名点评网站上,找到了自己一家分店的页面,让助手把上面的评论和发布时间数据弄下来。因为助手不会用爬虫,所以只能把评论从网页上一条条复制粘贴到Excel里。下班的时候,才弄下来27条。(注意这里我们使用的是真实评论数据。为了避免对被评论商家造成困扰,统一将该餐厅的名称替换为“A餐厅”。特此说明。)
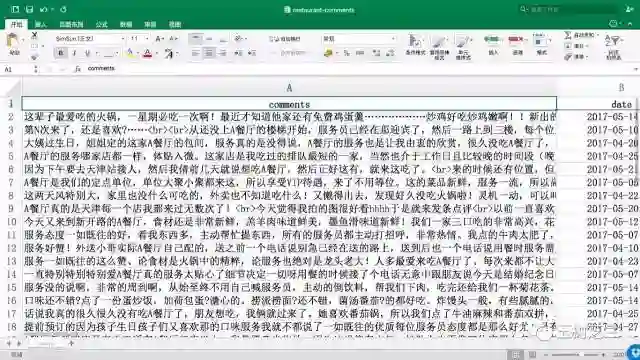
好在你只是想做个试验而已,将就了吧。你用我之前介绍的中文信息情感分析工具,依次得出了每一条评论的情感数值。刚开始做出结果的时候,你很兴奋,觉得自己找到了舆情分析的终极利器。
可是美好的时光总是短暂的。很快你就发现,如果每一条评论都分别运行一次程序,用机器来做分析,还真是不如自己挨条去读省事儿。
怎么办呢?
序列
办法自然是有的。我们可以利用《贷还是不贷:如何用Python和机器学习帮你决策?》一文介绍过的数据框,一次性处理多个数据,提升效率。
但是这还不够,我们还可以把情感分析的结果在时间序列上可视化出来。这样你一眼就可以看见趋势——近一段时间里,大家是对餐厅究竟是更满意了,还是越来越不满意呢?
我们人类最擅长处理的,就是图像。因为漫长的进化史逼迫我们不断提升对图像快速准确的处理能力,否则就会被环境淘汰掉。因此才会有“一幅图胜过千言万语”的说法。

准备
首先,你需要安装Anaconda套装。详细的流程步骤请参考《 如何用Python做词云 》一文。
助手好不容易做好的Excel文件restaurant-comments.xlsx,请从这里下载。
用Excel打开,如果一切正常,请将该文件移动到咱们的工作目录demo下。
因为本例中我们需要对中文评论作分析,因此使用的软件包为SnowNLP。情感分析的基本应用方法,请参考《如何用Python做情感分析?》。
到你的系统“终端”(macOS, Linux)或者“命令提示符”(Windows)下,进入我们的工作目录demo,执行以下命令。
pip install snownlp
pip install ggplot
运行环境配置完毕。
在终端或者命令提示符下键入:
jupyter notebook
如果Jupyter Notebook正确运行,下面我们就可以开始编写代码了。
代码
我们在Jupyter Notebook中新建一个Python 2笔记本,起名为time-series。
首先我们引入数据框分析工具Pandas,简写成pd以方便调用。
import pandas as pd
接着,读入Excel数据文件:
df = pd.read_excel("restaurant-comments.xlsx")
我们看看读入内容是否完整:
df.head()
结果如下:

确认数据完整无误后,我们要进行情感分析了。先用第一行的评论内容做个小实验。
text = df.comments.iloc[0]
然后我们调用SnowNLP情感分析工具。
from snownlp import SnowNLP
s = SnowNLP(text)
显示一下SnowNLP的分析结果:
s.sentiments
结果为:
0.6331975099099649
情感分析数值可以正确计算。在此基础上,我们需要定义函数,以便批量处理所有的评论信息。
def get_sentiment_cn(text):
s = SnowNLP(text) return s.sentiments
然后,我们利用Python里面强大的apply语句,来一次性处理所有评论,并且将生成的情感数值在数据框里面单独存为一列,称为sentiment。
df["sentiment"] = df.comments.apply(get_sentiment_cn)
我们看看情感分析结果:
df.head()
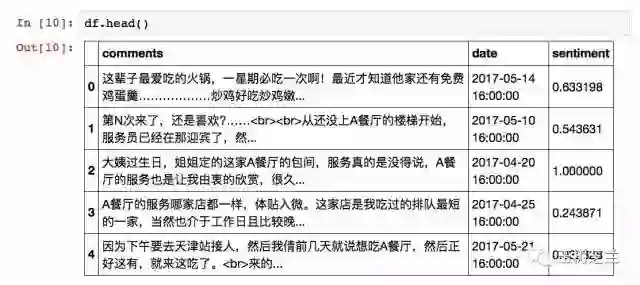
新的列sentiment已经生成。我们之前介绍过,SnowNLP的结果取值范围在0到1之间,代表了情感分析结果为正面的可能性。通过观察前几条数据,我们发现点评网站上,顾客对这家分店评价总体上还是正面的,而且有的评论是非常积极的。
但是少量数据的观察,可能造成我们结论的偏颇。我们来把所有的情感分析结果数值做一下平均。使用mean()函数即可。
df.sentiment.mean()
结果为:
0.7114015318571119
结果数值超过0.7,整体上顾客对这家店的态度是正面的。
我们再来看看中位数值,使用的函数为median()。
df.sentiment.median()
结果为:
0.9563139038622388
我们发现了有趣的现象——中位数值不仅比平均值高,而且几乎接近1(完全正面)。
这就意味着,大部分的评价一边倒表示非常满意。但是存在着少部分异常点,显著拉低了平均值。
下面我们用情感的时间序列可视化功能,直观查看这些异常点出现在什么时间,以及它们的数值究竟有多低。
我们需要使用ggplot绘图工具包。这个工具包原本只在R语言中提供,让其他数据分析工具的用户羡慕得流口水。幸好,后来它很快被移植到了Python平台。
我们从ggplot中引入绘图函数,并且让Jupyter Notebook可以直接显示图像。
%pylab inlinefrom ggplot import *
这里可能会报一些警告信息。没有关系,不理会就是了。
下面我们绘制图形。这里你可以输入下面这一行语句。
ggplot(aes(x="date", y="sentiment"), data=df) + geom_point() + geom_line(color = 'blue') + scale_x_date(labels = date_format("%Y-%m-%d"))
你可以看到ggplot的绘图语法是多么简洁和人性化。只需要告诉Python自己打算用哪个数据框,从中选择哪列作为横轴,哪列作为纵轴,先画点,后连线,并且可以指定连线的颜色。然后,你需要让X轴上的日期以何种格式显示出来。所有的参数设定跟自然语言很相似,直观而且易于理解。
执行后,就可以看到结果图形了。

在图中,我们发现许多正面评价情感分析数值极端的高。同时,我们也清晰地发现了那几个数值极低的点。对应评论的情感分析数值接近于0。这几条评论,被Python判定为基本上没有正面情感了。
从时间上看,最近一段时间,几乎每隔几天就会出现一次比较严重的负面评价。
作为经理,你可能如坐针毡。希望尽快了解发生了什么事儿。你不用在数据框或者Excel文件里面一条条翻找情感数值最低的评论。Python数据框Pandas为你提供了非常好的排序功能。假设你希望找到所有评论里情感分析数值最低的那条,可以这样执行:
df.sort(['sentiment'])[:1]
结果为:

情感分析结果数值几乎就是0啊!不过这里数据框显示评论信息不完全。我们需要将评论整体打印出来。
print(df.sort(['sentiment']).iloc[0].comments)
评论完整信息如下:
这次是在情人节当天过去的,以前从来没在情人节正日子出来过,不是因为没有男朋友,而是感觉哪哪人都多,所以特意错开,这次实在是馋A餐厅了,所以赶在正日子也出来了,从下午四点多的时候我看排号就排到一百多了,我从家开车过去得堵的话一个小时,我一看提前两个小时就在网上先排着号了,差不多我们是六点半到的,到那的时候我看号码前面还有才三十多号,我想着肯定没问题了,等一会就能吃上的,没想到悲剧了,就从我们到那坐到等位区开始,大约是十分二十分一叫号,中途多次我都想走了,哈哈,哎,等到最后早上九点才吃上的,服务员感觉也没以前清闲时周到了,不过这肯定的,一人负责好几桌,今天节日这么多人,肯定是很累的,所以大多也都是我自己跑腿,没让服务员给弄太多,就虾滑让服务员下的,然后环境来说感觉卫生方面是不错,就是有些太吵了,味道还是一如既往的那个味道,不过A餐厅最人性化的就是看我们等了两个多小时,上来送了我们一张打折卡,而且当次就可以使用,这点感觉还是挺好的,不愧是A餐厅,就是比一般的要人性化,不过这次就是选错日子了,以后还是得提前预约,要不就别赶节日去,太火爆了!
通过阅读,你可以发现这位顾客确实有了一次比较糟糕的体验——等候的时间太长了,以至于使用了“悲剧”一词;另外还提及服务不够周到,以及环境吵闹等因素。正是这些词汇的出现,使得分析结果数值非常低。
好在顾客很通情达理,而且对该分店的人性化做法给予了正面的评价。
从这个例子,你可以看出,虽然情感分析可以帮你自动化处理很多内容,然而你不能完全依赖它。
自然语言的分析,不仅要看表达强烈情感的关键词,也需要考虑到表述方式和上下文等诸多因素。这些内容,是现在自然语言处理领域的研究前沿。我们期待着早日应用到科学家们的研究成果,提升情感分析的准确度。
不过,即便目前的情感分析自动化处理不能达到非常准确,却依然可以帮助你快速定位到那些可能有问题的异常点(anomalies)。从效率上,比人工处理要高出许多。
你读完这条评论,长出了一口气。总结了经验教训后,你决定将人性化的服务贯彻到底。你又想到,可以收集用户等候时长数据,用数据分析为等待就餐的顾客提供更为合理的等待时长预期。这样就可以避免顾客一直等到很晚了。
祝贺你,经理!在数据智能时代,你已经走在了正确的方向上。
下面,你该认真阅读下一条负面评论了……
讨论
除了情感分析和时间序列可视化,你觉得还可以如何挖掘中文评论信息?除了点评网站之外,你还知道哪些舆情分析的数据来源?欢迎留言分享给大家,我们一起交流讨论。
硬广
最后插个广告,CVP官网全新改版中,想成为行业牛人,技术网红,就来CVP平台。同时CocoaChina电商开放平台即将上线,优质商品、商家正在征集中,小伙伴们快快来哦~~~
CVP联系QQ:2040382203
电商联系QQ:3479019115






