

论文题目:Zero-Shot and Few-Shot Learning With Knowledge Graphs: A Comprehensive Survey
**本文作者:**陈矫彦(曼彻斯特大学&牛津大学)、耿玉霞(浙江大学)、陈卓(浙江大学)、Jeff Z. Pan(爱丁堡大学)、何源(牛津大学)、 Ian Horrocks(牛津大学)、陈华钧(浙江大学) **发表期刊:**Proceedings of the IEEE 2023 **论文链接:**https://ieeexplore.ieee.org/abstract/document/10144560
欢迎转载,转载请注明出处****

引言
随着人工智能的飞速发展,机器学习,特别是深度学习,在过去几十年中在许多领域和应用中取得了显著的成就。例如,卷积神经网络(CNN)在图像分类和视觉对象识别方面的准确性常常超过人类,推动了自动驾驶车辆、面部识别、手写识别、图像检索和遥感图像处理等应用的快速发展。同样,循环神经网络(RNN)和基于Transformer的模型在序列学习和自然语言理解方面取得了成功,这些技术推动了机器翻译、语音识别和聊天机器人等应用的发展。然而,大多数机器学习模型的高性能依赖于大量的标记样本进行(半)监督学习,而这些标记样本在现实世界应用中往往成本高昂或不够有效。 在这种背景下,零样本学习(ZSL)和少样本学习(FSL)这两种主要的样本短缺设置备受关注。ZSL被定义为预测在训练中从未出现过的新类别(标签),这些新类别被称为未见类别,而在训练中有样本的类别被称为已见类别。与此相对的,FSL旨在预测那些只有少量标记样本的新类别。零样本学习在过去十年里引起了广泛的关注,提出了许多解决方案。例如,在零样本图像分类中,已经通过CNN从已见类别的图像中学习到的图像特征通常直接被用来为未见类别构建分类器。零样本学习方法通常利用描述类别间关系的辅助信息,如对象的视觉特征(也称为类属性)等。近五年来,知识图谱(KG)作为结构化知识(例如资源描述框架(RDF)三元组)的一种广泛使用的表示形式,引起了广泛的关注,一些基于知识图谱增强的零样本学习方法甚至在许多任务中达到了最先进的性能。 本文回顾了这些研究领域的90多篇文章,介绍了ZSL和FSL中使用的知识图谱及其构建方法,并系统地归类和总结了知识图谱感知的ZSL和FSL方法,将它们分为不同的范式,如基于映射、数据增强、基于传播和基于优化等。此外,本文还介绍了不同的应用领域,包括但不限于图像分类、问题回答、文本分类、知识提取,以及知识图谱补全任务等,最终探讨了不同视角下的挑战和未来的研究方向。 动机和贡献
- 样本短缺挑战: 大多数高性能机器学习模型都依赖大量标记样本。然而,在实际应用中收集这些样本成本高昂且效率不高。当出现新的预测目标时,从头开始重新训练复杂模型在许多情境中是不可接受的,这些情况导致了机器学习中的样本短缺问题。
- 知识图谱(KG)的应用: 针对样本短缺的问题,许多研究开始利用辅助信息,包括知识图谱形式的信息,以减少对标记样本的依赖。
- 综述文章的贡献: 本文综合回顾了超过90篇关于知识图谱感知研究的文章,专注于两种主要的样本短缺情境——零样本学习和少样本学习。
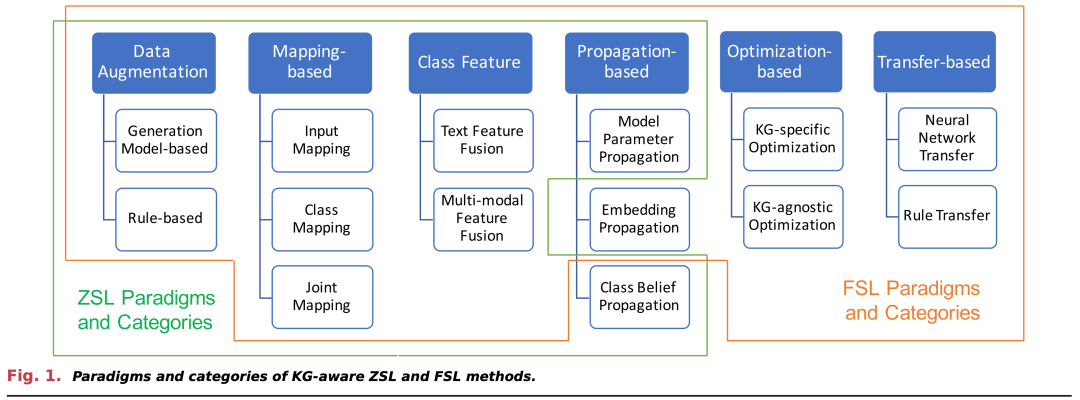
- 系统分类和总结: 文章首先介绍了ZSL和FSL中使用的知识图谱及其构建方法,然后系统地分类和总结了知识图谱感知的ZSL和FSL方法,这些方法被分为不同的范式,如基于映射、数据增强、基于传播和基于优化等。
- 应用领域的展示: 展示了不同的应用领域,包括图像分类、问题回答、文本分类、知识提取以及知识图谱补全任务等,并讨论了不同视角下的挑战和未来的研究方向。
零样本学习(ZSL)和少样本学习(FSL)的背景
ZSL的定义和应用领域
- 应用范围: ZSL被广泛应用于从图像分类和视觉问答(VQA)到文本分类、知识提取和知识图谱补全等不同任务。
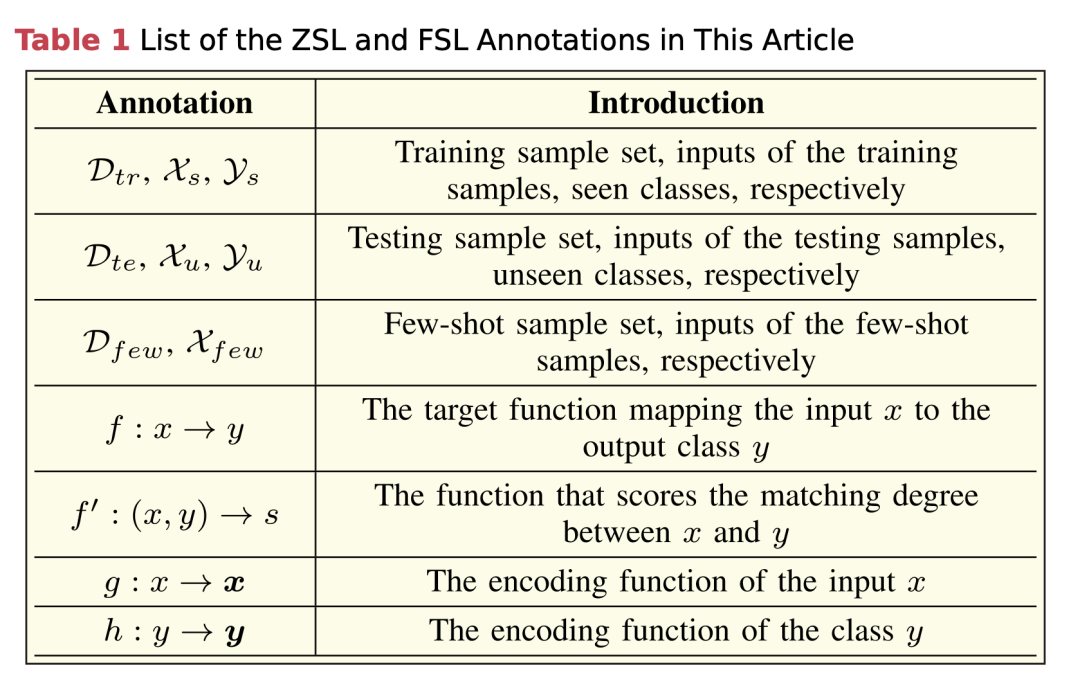
- 监督式机器学习分类定义: 在监督式机器学习分类中,训练数据集 用于训练分类器,从而在测试集 上准确预测标签。
- ZSL的正式定义: ZSL旨在使用训练样本集 训练函数 来预测测试集 上的样本,其中测试样本的类别 与训练样本的类别 不相交,即 。
- 辅助信息的使用: 由于未见类别没有标记样本,ZSL方法依赖于辅助信息,如类属性、类文本描述和类层次结构。
ZSL的发展和辅助信息
- 早期ZSL方法: 最初提出的ZSL方法主要使用类属性来描述对象的视觉特征。
- 文本信息的使用: 从2013年起,类的文本信息(从类名到描述类的句子和文档)开始在ZSL中获得广泛关注。
- 辅助信息的优缺点: 类属性信息易于使用且准确度高,但不能表达某些任务的复杂语义且通常需要人工标注;而类的文本信息易于获取,但可能包含不相关的噪音。

FSL的发展
- FSL定义: FSL旨在预测那些只有少量标记样本的新类别,这些类别的数量较小,不足以独立训练出稳健的模型。知识转移的关键挑战: 对于FSL,关键挑战是选择合适的知识进行转移并适应性地结合这些转移的知识以解决新的预测任务。
知识图谱(KG)的背景
定义和范围
- 定义: 知识图谱(KG)被定义为一个由实体集合 、属性集合 、实体文本集合 和陈述集合 组成的结构,其中每个RDF三元组 表示为 ,即主体 (实体),谓词 (属性),客体 (实体或实体文本)。
- 广泛应用: KG在搜索引擎、推荐系统、临床人工智能和个人助理等许多应用中取得了巨大成功。
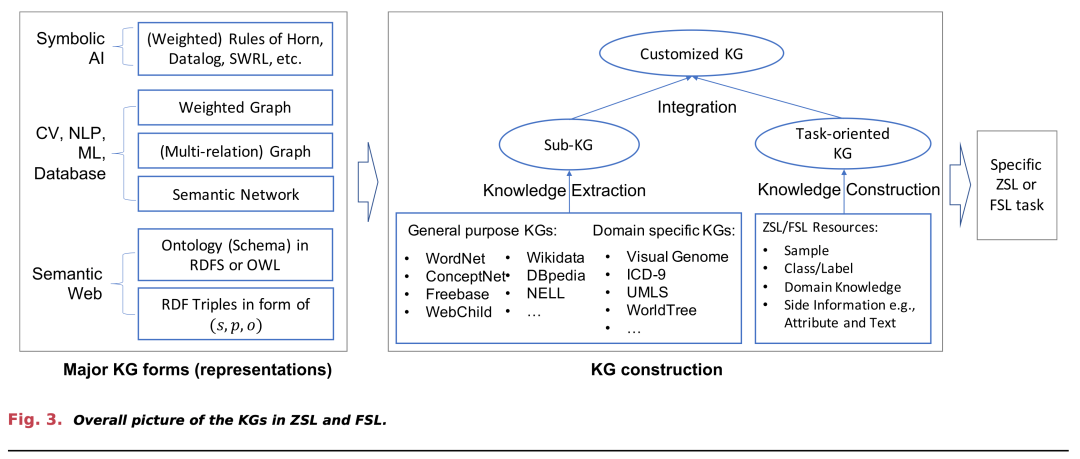
通用目的的KGs
- WordNet: 一个大型词汇数据库,包含各种词汇间的关系,如同义词、上下义词等,广泛用于构建特定任务的类层次结构,尤其在图像分类中。
- ConceptNet: 一个包含常识知识的免费可用语义网络,用于增强ZSL和FSL。
- Freebase: 一个大型KG,由多个来源贡献的关系事实组成,主要应用于开放信息提取。
- Wikidata: 一个快速增长的协作编辑KG,用于增强ZSL和FSL。
- DBpedia: 一个主要从Wikipedia获取知识的大型通用KG,提供层次结构概念和其他模式知识。
- NELL: 一个从网络持续提取的流行KG,用于增强ZSL和FSL。
- WebChild: 一个从网络提取的常识知识集合,虽然在ZSL和FSL中使用较少,但在某些应用中被用作辅助KG。
ZSL和FSL的KG构建
- 特定任务的KG构建: 对于ZSL或FSL任务,有时可以直接应用现有KG,但大多数情况下需要提取或构建适应特定任务的KG。
- 子KG提取: 通过将ML类别与KG实体匹配,然后提取匹配的实体及其相关知识来构建子KG。
- 任务导向的KG构建: 构建特定任务的KG,例如通过使用类别的文本信息来挖掘类别间关系。
- 知识整合: 通过整合不同KG或其他资源中提取的知识来构建高质量的任务特定KG。
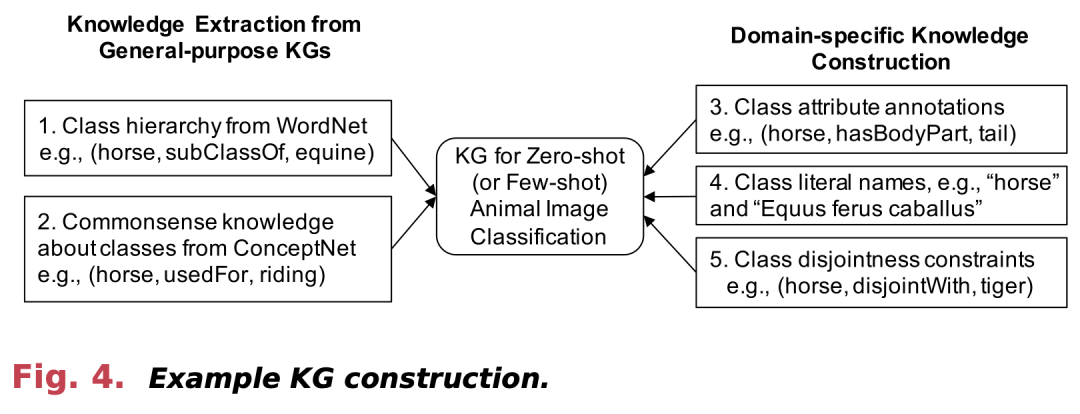
综上所述,知识图谱在ZSL和FSL中的应用不仅仅局限于作为辅助信息的来源,还包括作为解决特定预测任务的关键工具。这些应用展示了KG在不同领域中的广泛适用性和灵活性。 知识图谱驱动的零样本学习(KG-aware ZSL)
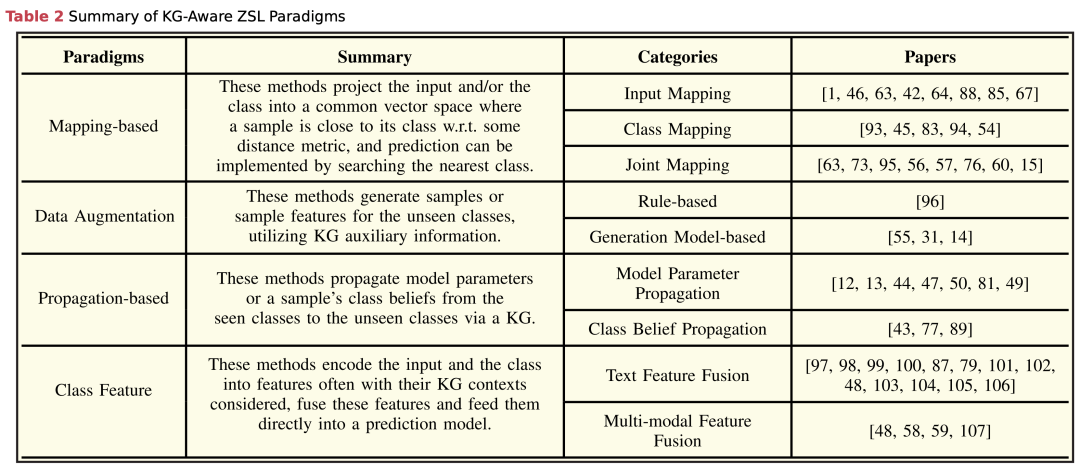
基于映射的范式 (Mapping-Based Paradigm)
- 目标: 构建将输入或类别映射到相同空间的映射函数,使得经过映射后的向量表示可以比较(例如,如果输入的向量与类别向量在某种度量如余弦相似度或欧几里得距离上接近,则输入属于该类别)。
- 映射函数: 映射函数分为输入映射和类别映射。这些映射可以是线性的也可以是非线性的转换网络,通常从训练数据学习而来。
基于数据增强的范式 (Data Augmentation Paradigm)
- 使用数据增强: 通过增加训练样本或其表示来提高ZSL性能。这包括通过生成合成样本或使用半监督学习方法来增加数据量。
- 增强类型: 增强可以是真实数据的变体或通过算法生成的新数据。

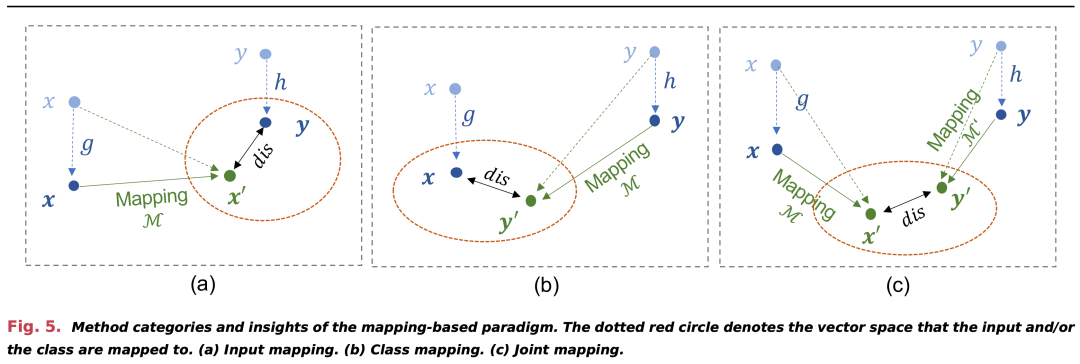
基于传播的范式 (Propagation-Based Paradigm)
- 信息传播: 利用KG中的关系来传播信息,帮助学习过程了解未见类别。
- 应用方式: 通过在KG上使用图神经网络或其他图基础算法来实现类别间的信息传播。
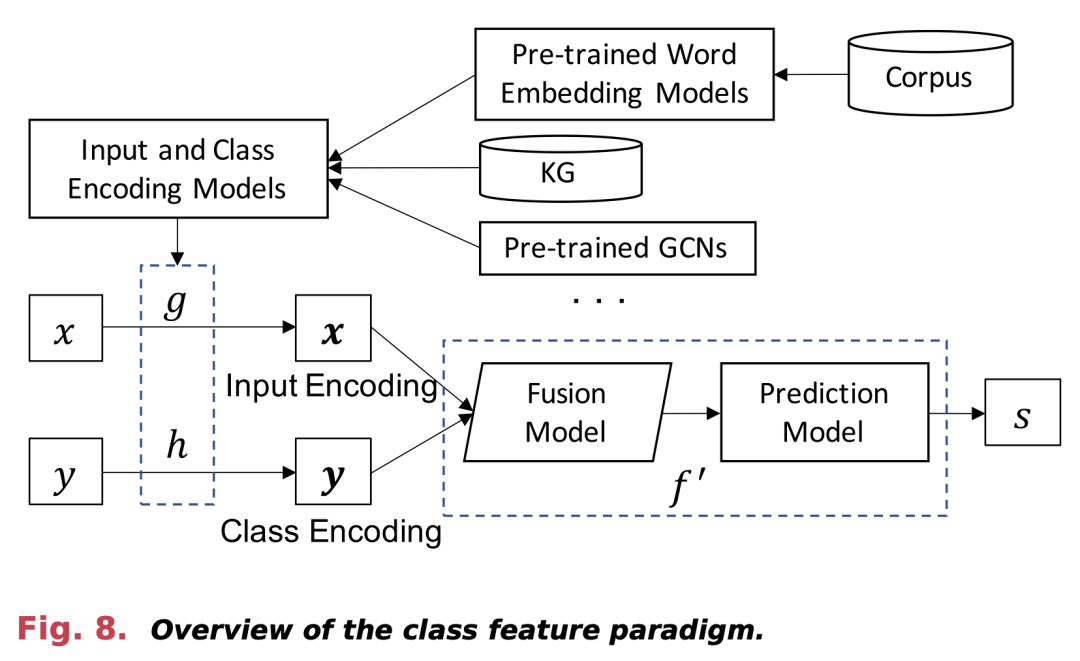
基于类别特征的范式 (Class Feature Paradigm)
- 特征提取: 专注于提取和利用类别特征来改善对未见类别的理解和预测。
- 特征类型: 这些特征可能是从KG中提取的类别属性、文本描述或其他与类别相关的信息。
知识图谱驱动的少样本学习(KG-aware FSL)
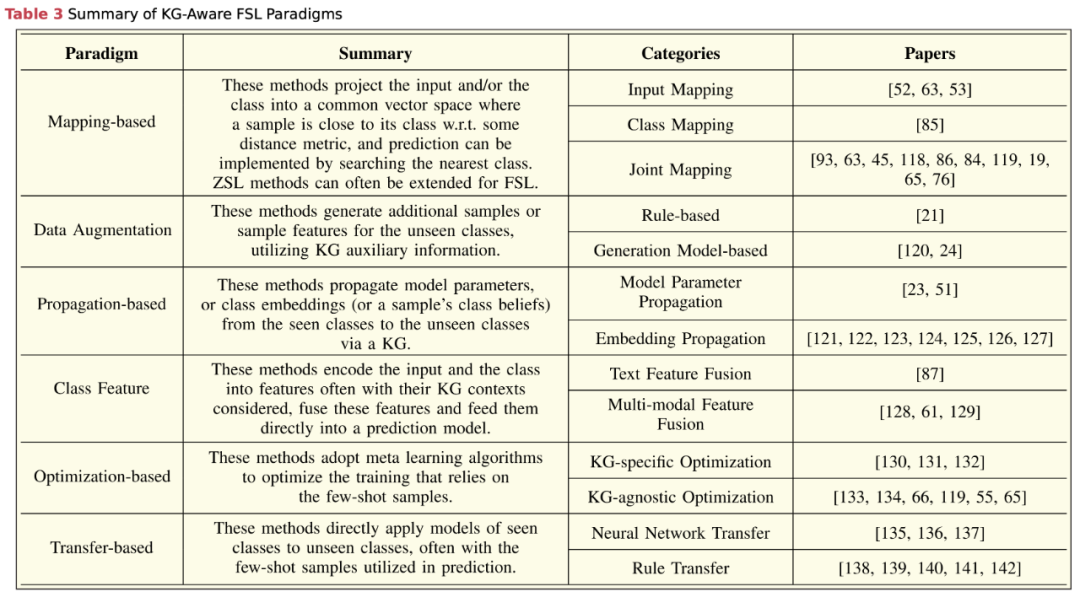
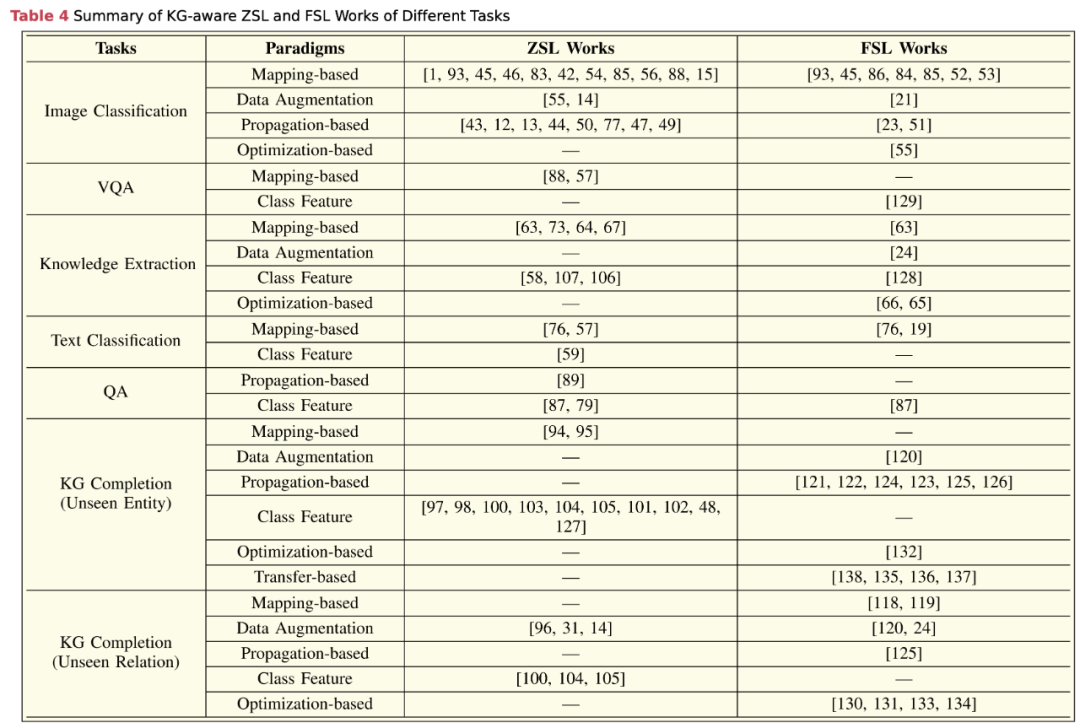
基于映射的范式 (Mapping-Based Paradigm)
- 目标: 构建映射函数,将输入和/或类别映射到同一空间,使其向量表示可比较。
- 映射函数: 输入映射和类别映射, 可以是线性或非线性转换网络,通常从训练数据学习得到。
基于数据增强的范式 (Data Augmentation Paradigm)
- 使用数据增强: 通过生成新的数据或样本特征来解决样本短缺问题,将问题转化为标准的监督学习问题。
- 增强类型: 可以是基于规则的或基于生成模型的,利用任务的背景知识。
基于传播的范式 (Propagation-Based Paradigm)
- 信息传播: 利用KG中的关系来传播信息,帮助学习过程理解未见类别。
- 应用方式: 使用图神经网络或其他图基础算法在KG上实现类别间的信息传播。
基于类别特征的范式 (Class Feature Paradigm)
- 特征提取: 专注于提取和利用类别特征来改善对未见类别的理解和预测。
- 特征类型: 这些特征可能是从KG中提取的类别属性、文本描述或其他与类别相关的信息。
基于优化的范式 (Optimization-Based Paradigm)
- 优化目标: 在学习过程中优化特定的目标函数,以提高对未见类别的预测精度。
- 应用方法: 使用优化算法来调整模型参数,提高学习效率和预测性能。

基于迁移学习的范式 (Transfer-Based Paradigm)
- 知识转移: 利用已见类别上学习到的知识来帮助理解和预测未见类别。
- 转移策略: 包括特征转移、模型参数转移等,以实现跨类别的学习。
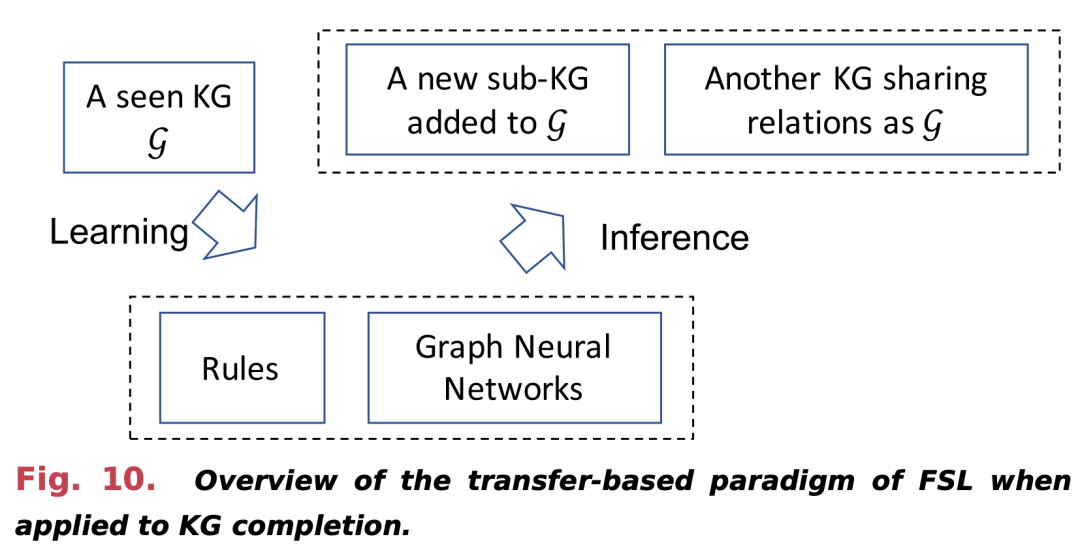
ZSL和FSL比较
- 共同点与差异: 分析和比较ZSL和FSL在方法、应用和性能上的共同点和差异。
- 综合评估: 对两种学习策略的优势和局限性进行综合评估。
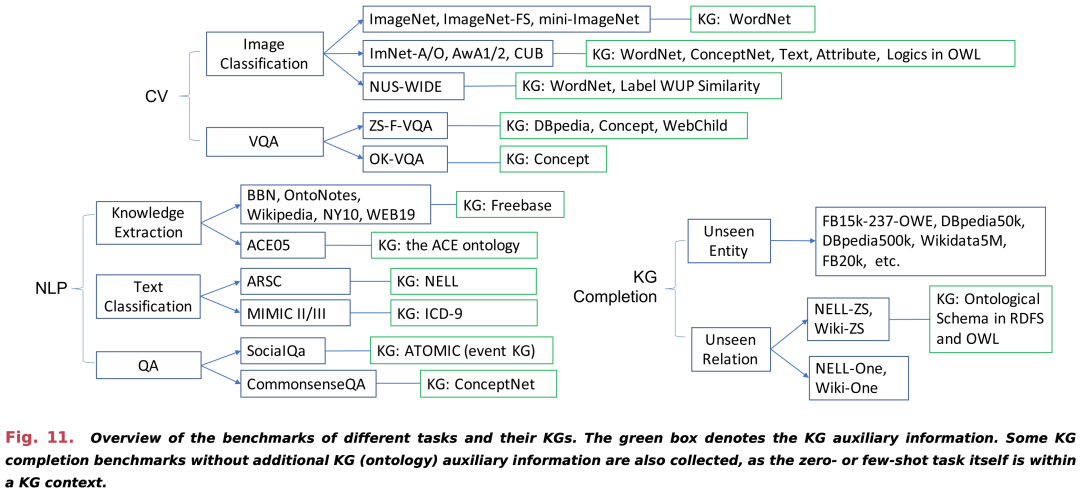
应用方向和数据集(Applications & Resources)
计算机视觉 (Computer Vision)
- 多样化应用: 在计算机视觉领域,KG-aware ZSL和FSL被应用于图像分类、目标识别等任务。
- 数据集: 使用了如ImageNet、AwA2等标准图像数据集,以及特定于任务的数据集。
自然语言处理 (Natural Language Processing)
- 文本分类和问答: 在NLP领域,KG-aware ZSL和FSL用于文本分类、实体提取、关系提取、问答系统等。
- 数据集: 使用了如TREC QA、WikiQA等问答数据集和特定于任务的文本数据集。
知识图谱补全 (KG Completion)
- 关系预测: 应用于预测知识图谱中的缺失关系,如实体关系预测。
- 数据集: 使用了如NELL、Wikidata等知识图谱数据集。
KG质量 (KG Quality)
- 数据质量问题: 讨论了知识图谱中数据质量问题,如不完整性、不一致性等。
- 提高质量: 探讨了如何通过各种技术提高KG的质量和可靠性。
学习范式 (Learning Paradigms)
- 多样性: 分析了各种KG-aware学习范式,包括映射、传播、数据增强等。
- 改进方法: 探讨了如何改进这些范式以提高ZSL和FSL的性能。
ZSL和FSL在KG构建中的应用 (ZSL and FSL in KG Construction)
- 构建方法: 探讨了如何利用ZSL和FSL来构建和改进知识图谱。
- 实用案例: 分析了实际案例,如如何在特定领域(如医学)构建和使用知识图谱。
基准测试 (Benchmarking)
- 性能评估: 讨论了如何评估和比较不同的ZSL和FSL方法。
- 基准数据集: 强调了使用标准和可比较的基准数据集的重要性。

