

**论文题目:**When Do Program-of-Thought Works for Reasoning? **本文作者:**毕祯(浙江大学)、张宁豫(浙江大学)、姜一诺(浙江大学)、邓淑敏(新加坡国立大学)、郑国轴(浙江大学)、陈华钧(浙江大学) **发表会议:**AAAI 2024 **论文链接:**https://arxiv.org/pdf/2308.15452.pdf ****代码链接:https://github.com/zjunlp/EasyInstruct 欢迎转载,转载请注明出处

**
**
一、引言
现阶段,程序代码是解决基于大型语言模型(LLM)的复杂推理任务的有效的方式之一,这类方法通常被称为"程序或代码思维链" (program-of-thought)。与传统思维链(chain-of-thought)方法相比,代码思维链方法将复杂问题分解为可执行的代码片段,并且利用代码执行器逐步解决子问题,可以较大程度提升基于大型语言模型的推理能力。然而目前代码程序数据本身的形式与大模型推理能力之间的相关性仍是未解之谜,我们对于构造何种代码指令数据才能提升基于代码思维链的大模型推理能力仍知之甚少。因此,本文致力于分析以下问题: 什么情况下代码思维链数据对语言模型推理最为有效? 本文分析了不同逻辑和结构复杂度的代码程序数据,初步探究了不同复杂度的代码数据与语言模型推理能力的关系。
二、代码程序复杂度估计
在这项工作中,我们提出Complexity-Impacted Reasoning Score (CIRS) 用来度量推理复杂度的分数。CIRS分数用于衡量代码推理步骤(代码思维链)对语言模型推理能力的影响。
我们假设代码编程语言具有独特的优势,原因如下:
- 首先,相较于扁平化的自然语言数据,得益于其面向对象的特征,代码语言能够更加有效建模复杂的结构;
- 其次,程序语言具有相对固有的过程导向逻辑,其面向过程的特性有助于解决多步推理问题;
因此,合理的方式应该从结构和逻辑两个角度评估代码的复杂性。
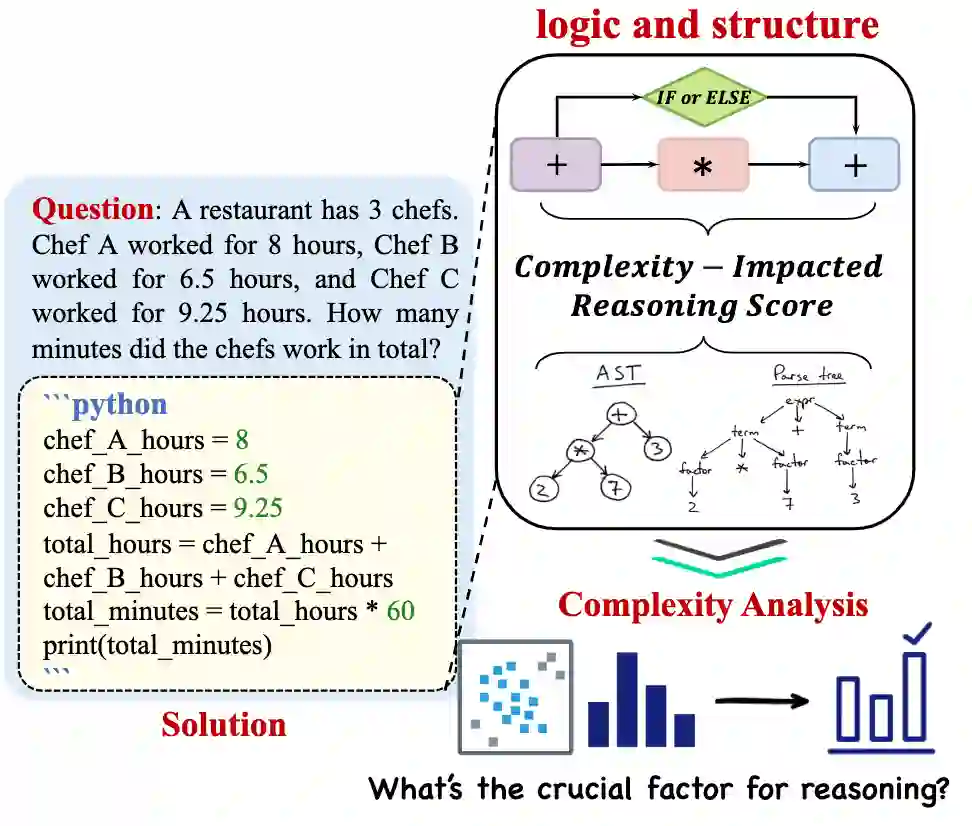
具体来说,为了衡量代码思维链 的推理能力,我们定义为结构复杂性 和逻辑复杂性 的乘积。
**2.1 结构复杂性定义
为了计算结构复杂性,我们衡量抽象语法树(AST)的结构复杂性。具体来说,我们利用抽象语法树中的三个指标来反映其结构信息。 其中 、 和 分别是代码思维链 中的抽象语法树中节点数、节点类型和树深度的特征。我们首先使用函数 对每个特征的累积数据 进行 Z-分数标准化,然后通过均值池化来汇总整体信息。节点数反映了代码的大小。 一般来说,节点数越多,复杂性越高。但是仅凭节点数无法全面衡量代码的复杂性,因为一个具有简单结构的大代码可能比一个具有复杂结构的小代码更容易理解。节点类型帮助识别代码中存在的结构元素,例如条件语句、循环和函数调用。不同的节点类型在代码中扮演不同的角色,并对代码的复杂性有不同的贡献。因此,记录各种节点类型的数量可以增进对代码结构复杂性的理解。最后,抽象语法树 的深度反映了代码中嵌套的级别。更大的树深度可能意味着更复杂的控制流和逻辑,使代码更难理解。同样树深度也不是唯一的衡量标准。一个具有多个简单分支的浅树可能比一个具有少数复杂分支的深树更容易理解。
**2.2 逻辑复杂性定义
受到 Halstead 复杂度 和 McCabe 的圈复杂度的启发,我们定义代码的逻辑复杂性 ,它包含了困难度 和圈复杂度 。 其中困难度 表示解决问题的难度, 表示代码思维链 的圈复杂度。 为了表示理解程序所需的工作量,困难度 定义为: 其中 表示不同操作符的数量, 表示代码中操作数的总数, 表示代码块 中不同操作数的数量。在这个公式中,术语 代表操作符的平均复杂性,而术语 代表操作数的平均复杂性。 为了考虑代码的逻辑循环(知识回路或者控制流),圈复杂度 被定义为: 其中 表示代码控制流图中的边数, 表示代码控制流图中的节点数。高圈复杂度与潜在的程序错误之间存在显著的相关性, 高圈复杂度的模块和方法也会有最多的缺陷。我们注意到高圈复杂度表明程序代码具有复杂的判断逻辑,同时也可能导致较低的质量,并且难以测试和维护。 总的来说,引入对于代码块困难度和圈复杂度的衡量指标,可以同时兼顾码操作符、操作数和代码控制流的复杂性对于代逻辑复杂度的影响。
三、实验分析
本文的实验分为两部分,第一部分我们使用CIRS指标对代码数据进行经验性分析,并且按照分数值进行划分,最后探讨不同复杂度代码块对大模型推理能力的影响。第二部分,我们将第一部分得到的结论用于代码数据的过滤,筛选出对大模型推理能力增益最有效的代码,在多个数据集上做验证。
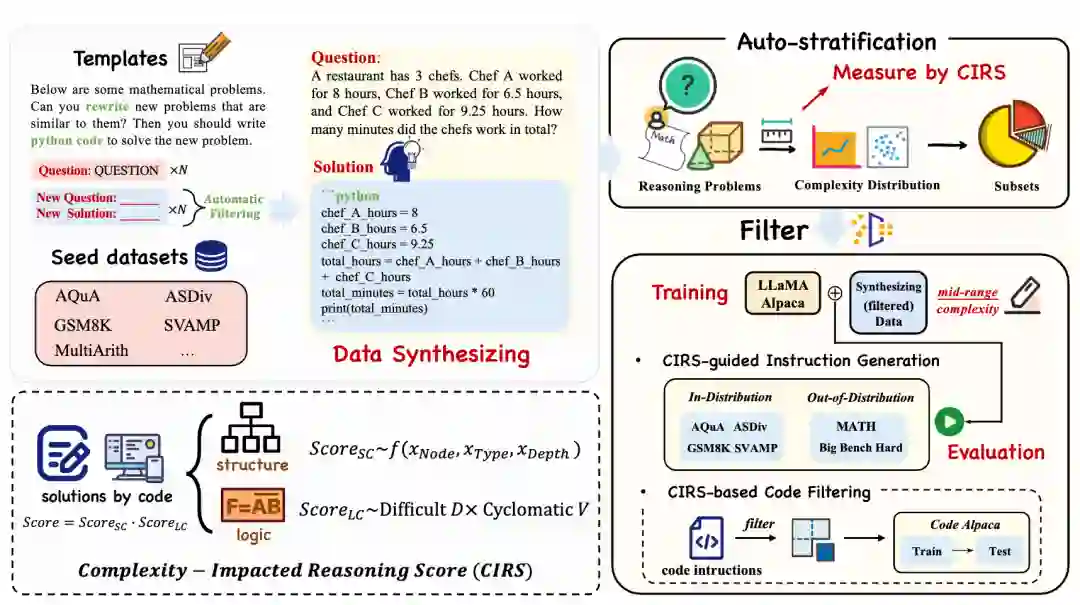
**3.1 经验性实验分析
为了尽量避免现有数据集本身造成的误差,我们选择模拟新的代码数据,种子数据的来源包括GSM8K、MultiArith、Asdiv等训练集。我们从五个种子数据集模拟合成了超过60,000个样本。最后每个数据集生成了大约10,000个样本,并且我们选择尽可能多的数据集以确保数学问题的多样性。在获取到生成的代码数据后,我们使用CIRS指标并根据代码复杂性分布的分析手动将数据分成不同的子集。基于不同的复杂性分数,我们将划分的子集命名为low(低分样本)、medium(中分样本)和high(高分样本)。
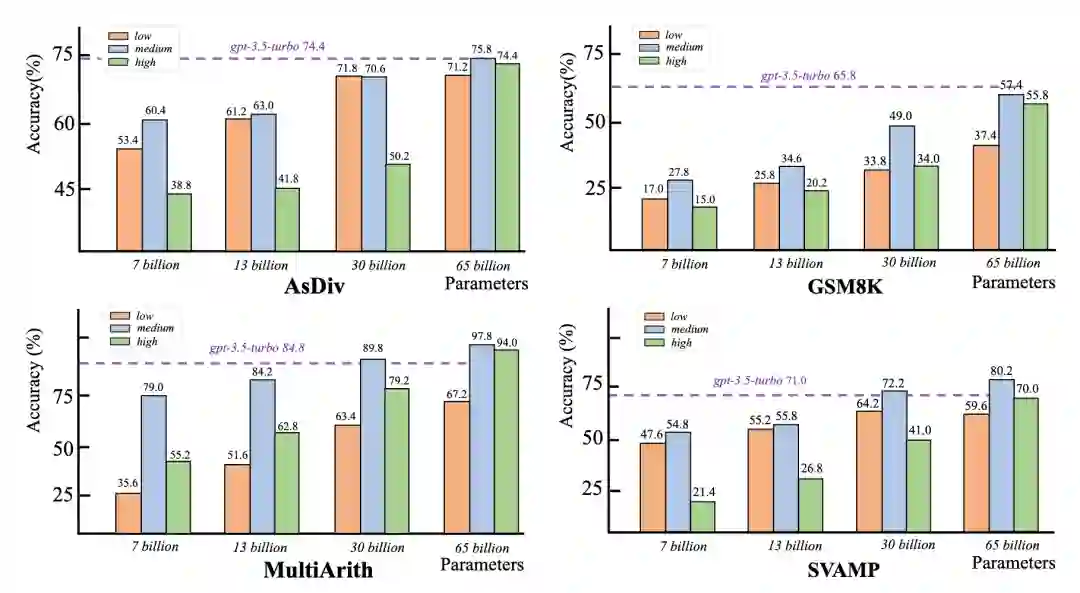
1. 不同代码程序复杂度分数的影响****合适代码的复杂度对于代码思维链的提示的推理能力至关重要
从四个数据集的结果中,我们注意到当代码数据的复杂性处于中等范围时,模型的性能最佳。这表明学习性符号语言对于程序辅助提示的推理能力至关重要。其原因在于,过于简单的复杂性数据对于大型语言模型(LLMs)来说太简单,导致效果不太明显。相反,当复杂性显著增加时,逻辑语义和嵌套结构变得难以理解或学习,这可能对大型语言模型的推理能力产生不利影响。 参数数量越大,代码数据对于大型语言模型的推理能力提升越显著
随着语言模型大小从70亿增加到650亿,其推理能力也在提高。实际上经过微调后,大多数650亿参数量的模型使用代码数据可以达到与gpt-3.5-turbo相当的结果。这表明拥有足够多的参数对于语言模型的实质性推理能力至关重要。此外当语言模型足够大时,不同复杂度代码之间带来的结果差异很小。这说明大量参数的语言模型能够更加擅长处理符号数据,并且内在的具有产生强大推理能力的潜力。 当前语言模型的架构在理解推理能力方面存在局限性
我们观察到,当数据复杂性极高时,语言模型的性能倾向于下降,这反映了大型语言模型的推理能力有其固有的限制。首先,我们认为当前语言模型的架构(例如decoder-only架构)对于理解复杂知识的能力有限,这也限制了其推理能力的涌现。大模型展示强大推理能力的前提是它们能够理解复杂数据中嵌入的结构和逻辑知识。因此,未来的研究需要探索具有更强推理能力的模型基础结构。其次,进一步增强推理能力需要依赖外部工具。我们知道推理问题的范围非常广泛,不仅包括数学推理,还包括常识或更复杂的逻辑推理任务。因此,仅依靠LLM本身是不足以一次性解决所有问题的,需要更强大的外部工具的协助。 2. 不同复杂度分数的数据特征
不同CIRS分数的不同子集显示出不同的结构和逻辑差异,我们还发现不同复杂性分数的结果与推理问题的认知难度级别相对应。低分数的样本包含很少的结构信息。尽管它们包含一些中间推理过程,但这些主要以平面文本描述形式呈现。这些样本通常对应于更简单的、在结构和逻辑上不足的问题。当分数在代码推理步骤中增加时,具有简单逻辑语义和结构的编程语言的存在也随之增加。这些样本通常涉及简单且直接的逻辑操作。得分极高的样本包含大量的结构化函数定义或推理过程,这表明存在许多复杂的条件语句和函数结构。这些样本通常是高度挑战性的数学问题。 3. 排除数据分布本身的影响
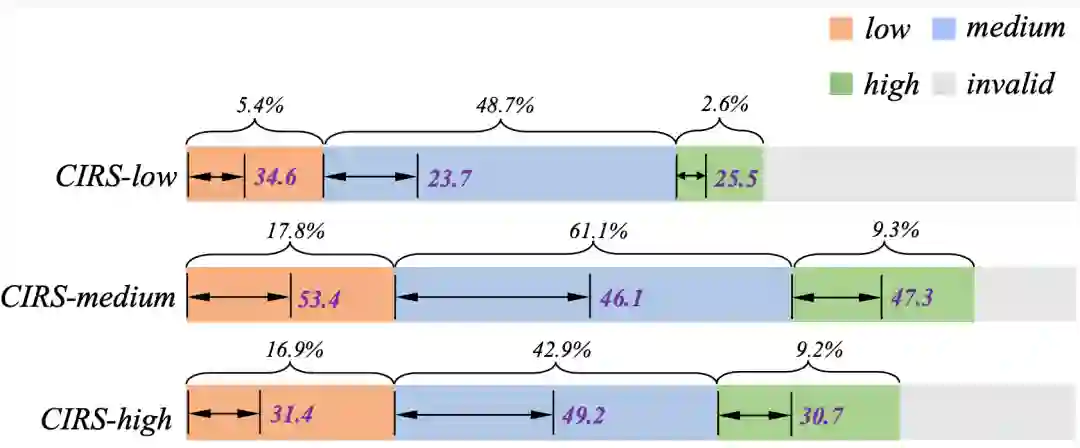
为了消除数据分布本身可能带来的偏差,例如由于出现频率较高而在中等数据范围内的性能提升,我们对不同复杂性分数的结果进行了更深入的分析。从实验结果来看,模型对每种分布的预测准确率与训练数据的数量无关。因此,我们可以初步得出结论,复杂性数据的有效性并非因为数据出现的频率。 4. 代码思维链和文本思维链的比较
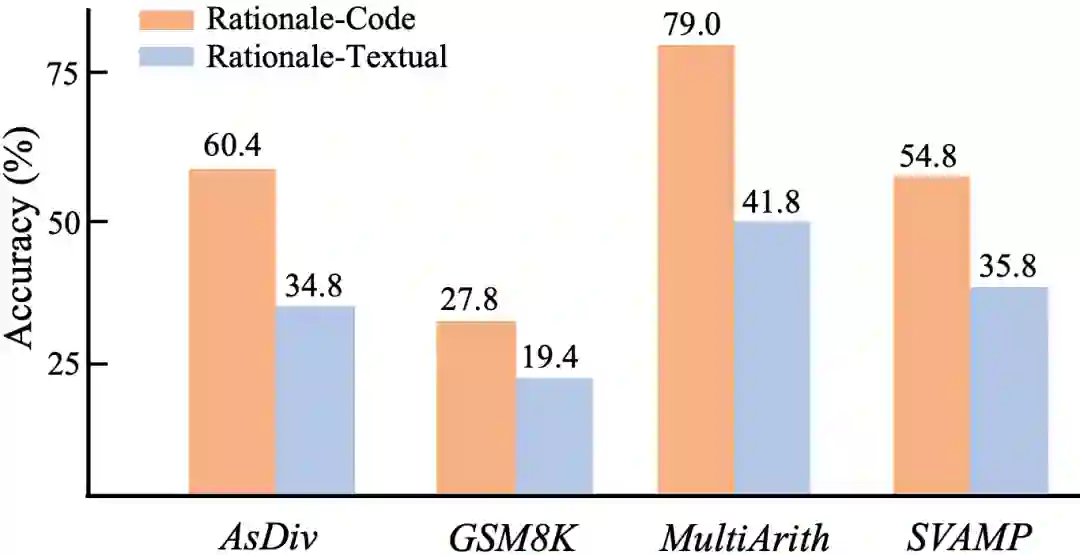
为了验证代码和文本推理链的效果,我们用文本替换了使用相同数据集的代码程序推理过程。代码数据集在所有四个数据集中都展示出明显的优势。这是因为代码本质上包含了逻辑语义和结构信息, 另一个原因是代码可以被外部解释器执行。因此带有代码的提示方法优于扁平化的文本信息。
**3.2 使用CIRS提升大语言模型推理能力
1. 自动合成和划分代码数据算法
我们将第一部分实验的步骤集成为一种自动合成和分层算法,然后将其应用于数学推理的指令生成任务,以及代码生成任务中用来做代码数据过滤。

2. CIRS引导的指令生成
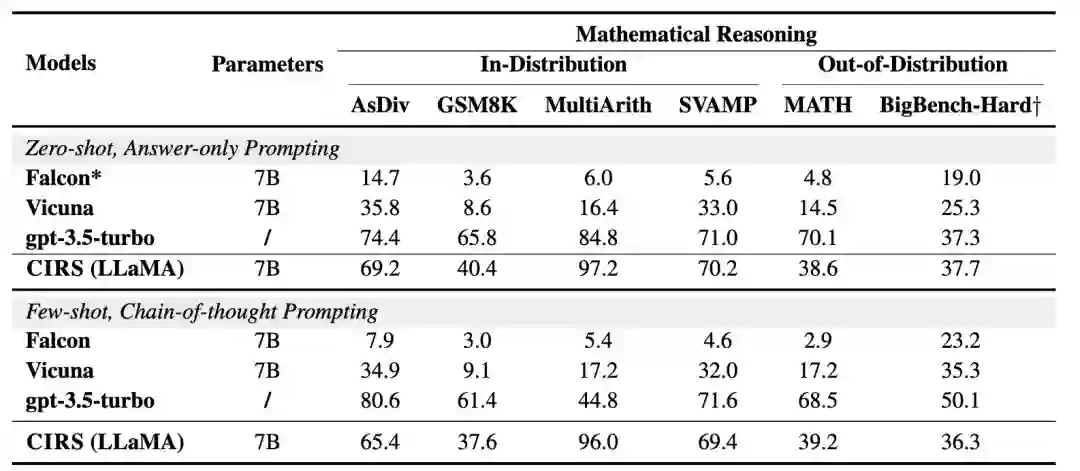
合适的代码数据复杂性对于语言模型表现出最佳的推理能力更重要。因此,我们从源数据集中筛选出更多数据训练一个针对中等复杂性范围的代码数据增强推理模型。在分布内测试条件下,我们发现训练的模型优于Vicuna和Falcon。为了消除数据分布的影响,我们直接测试了模型在分布外设置中的性能。相同的参数下,我们的模型在零样本和少样本提示下表现更好。值得注意的是,我们的方法在零样本设置下在BigBench-Hard与ChatGPT相当。对于MATH数据集,我们注意到我们的模型仍然优于基线模型。但是由于代码数据本身的局限性,我们的模型比ChatGPT差得多。 3. 不同推理复杂度分数的影响
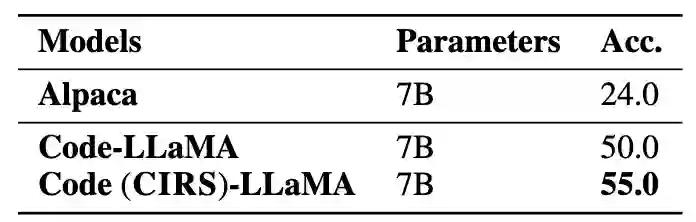
为了验证我们方法在代码相关任务中的有效性,我们过滤训练数据集并获得了更多高质量代码指令的子集。结果表明,Code (CIRS)-LLaMA在纯代码生成任务中表现出有效的性能。我们可以得出结论,优化的结构和逻辑语义对LLM的推理能力最有益。
四、讨论与总结
1. 数学逻辑和代码之间的深层联系是什么?
柯里-霍华德同构(Curry-Howard isomorphism)表明数学逻辑和计算机程序代码之间的互为镜像,同时这也说明了数学证明和计算机程序可以建立某种关联,为我们理解语言模型也提供了启发和思考。语言模型在处理代码时,如果能够理解和应用类型系统,就能更好地处理逻辑推理。类型系统在程序设计中用于约束和推理数据和函数之间的关系,类似于逻辑系统中命题和证明的关系。在编写程序时,人需要对数据和操作进行逻辑推理。这与证明一个逻辑命题的过程有相似之处。语言模型如果能理解和生成程序代码,就表明它在进行某种形式的逻辑推理。通过程序代码的理解和生成,语言模型能够更有效地进行逻辑推理,处理复杂的问题解决方案,这对于理解逻辑问题来解决特定问题是有用的。虽然柯里-霍华德同构直接描述的是逻辑系统和类型系统之间的关系,但将这种理论应用于语言模型和程序代码的融合,可以帮助模型更好地理解和处理逻辑推理和编程任务。这表明了逻辑学和计算机科学之间的深刻联系也适用于人工智能和语言模型的领域。 2. 对于语言模型的推理能力来说,哪种数据格式至关重要?
在本文中,我们探讨了程序思维提示链的推理能力。结果表明,具有某些逻辑和结构特质的优化级别代码数据是关键因素。代码数据之所以高效,是因为它本质上是半结构化的,且在自然界中丰富存在。我们可以证明:(1) 数据的局部结构特性对于提升推理能力至关重要,这与Prystawski等 (Why think step-by-step? Reasoning emerges from the locality of experience) 的观点一致。数据中固有的逻辑连贯性或一定量的知识回路是必要的。(2) 过于复杂的结构信息和逻辑对LLM来说是“太难学习”的。本文的实验结果表明,最有效的是知识的最佳层次复杂度,因为它对大多数大型语言模型来说是可学习的。同时,我们还发现,随着语言模型中参数数量的增加,它们对复杂知识的理解也在提高。 在本项工作中,我们致力于探究代码思维链数据和大模型推理能力背后的机理,并提出CIRS来衡量代码数据形式与大模型推理能力之间的关系。通过考虑代码数据的结构和逻辑属性,我们使用AST来编码结构信息,并根据难度和圈复杂度编码结构特征。通过实证分析,我们发现代码语言的合适水平在程序思维提示的推理能力中扮演着关键角色。进一步的,我们设计了应用数学推理和代码生成任务的自动合成和分层算法。广泛的结果证明了所提方法的有效性。在未来,我们将把这项工作扩展到更多场景,例如常识或逻辑推理任务,并以低计算成本训练强大的推理模型。