赛尔原创 | EMNLP 2019 基于BERT的跨语言上下文相关词向量在零样本依存分析中的应用
论文名称:Cross-Lingual BERT Transformation for Zero-Shot Dependency Parsing
论文作者:王宇轩,车万翔,郭江,刘一佳,刘挺
原创作者:王宇轩
下载链接:https://www.aclweb.org/anthology/D19-1575/转载须注明出处:哈工大SCIR
1.简介
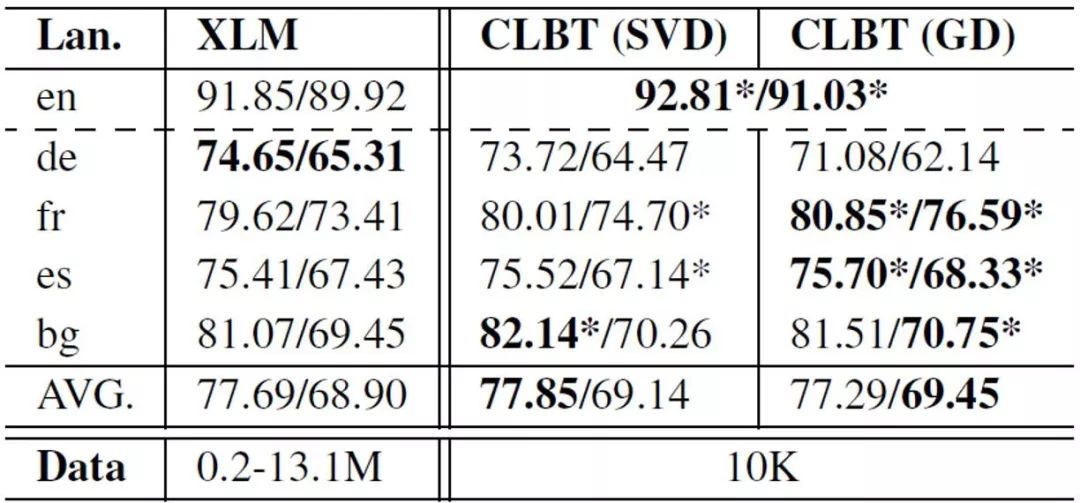
跨语言词向量对于跨语言迁移学习具有重要意义。本文提出一种简单快捷的离线跨语言BERT投射方法,该方法能够利用预训练好的BERT模型生成跨语言上下文相关词向量。我们在零样本跨语言依存分析任务中实验了这种词向量,取得了远超使用传统跨语言上下文无关词向量方法的目前最好结果。我们还将这种词向量与XLM(一种使用跨语言数据重新训练BERT的方法)进行了对比,实验表明在与该方法取得相近结果的情况下,我们的方法所需的训练数据和计算资源远少于XLM,同时训练速度也更快。
我们公布了代码和训练好的17种语言投射到英语的模型,使用这些模型可以快速将不同语言的BERT表示向量投射到同一语义空间中。
代码及模型路径为:
https://github.com/WangYuxuan93/CLBT
2.背景和动机
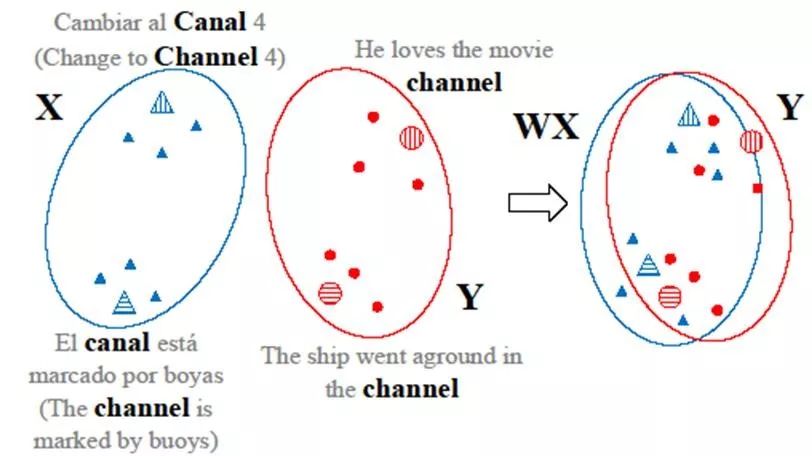
图1 CLBT模型示意图
3.方法
传统上下文无关的跨语言词向量学习方法一般只需要双语词典作为训练的监督信号。但在CLBT的训练过程中,需要包含上下文信息的词对齐数据,才能获得BERT的表示向量。因此我们使用无监督词对齐工具获得包含上下文的词对作为训练数据。
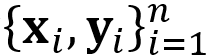 。
训练目标为找到一个合适的线性映射W,使得经过其投射的源语言向量与其对应的目标语言向量距离最小:
。
训练目标为找到一个合适的线性映射W,使得经过其投射的源语言向量与其对应的目标语言向量距离最小:
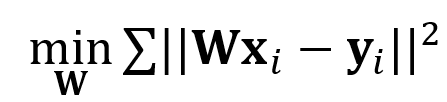
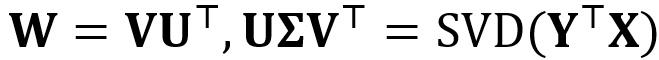
表1 在UD v2.2数据上的实验结果(LAS)与FT-SVD和mBERT的对比
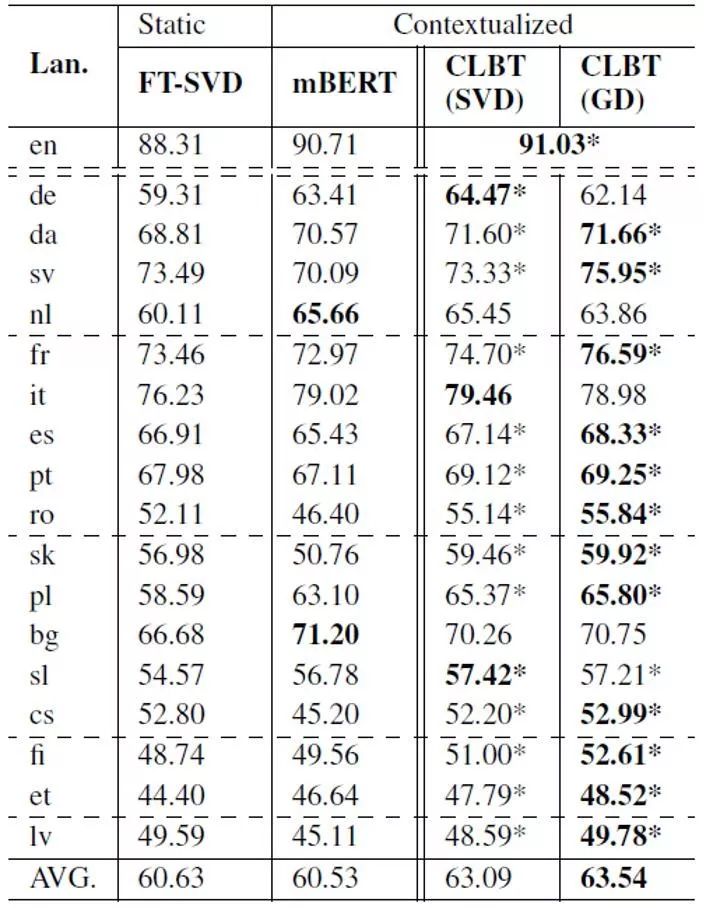
表2 在UD v2.2数据上的实验结果(LAS)与XLM的对比
赛尔原创 | EMNLP 2019 基于上下文感知的变分自编码器建模事件背景知识进行If-Then类型常识推理
赛尔原创 | EMNLP 2019 跨语言机器阅读理解
赛尔原创 | EMNLP 2019融合行、列和时间维度信息的层次化编码模型进行面向结构化数据的文本生成

登录查看更多
相关内容
专知会员服务
10+阅读 · 2019年11月4日




相关VIP内容
专知会员服务
10+阅读 · 2019年11月4日
相关资讯
相关论文