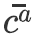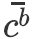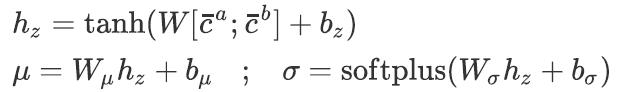论文名称:Modeling Event Background for If-Then Commonsense Reasoning Using Context-aware Variational Autoencoder
论文作者:杜理,丁效,刘挺,李忠阳
原创作者:杜理,丁效
下载链接:https://arxiv.org/abs/1909.08824
转载须注明出处:哈工大SCIR
理解事件并推断事件相关常识知识对于多种NLP任务具有重要意义。给定某一特定事件,人类可以轻易推断出该事件的意图、效应等,然而这类If-Then推理任务对于AI仍具相当挑战性。针对此,研究者提出了一个If-Then类型事件常识推理数据集Atomic和基于RNN的Seq2Seq模型以进行此类推理。然而,同一事件可能对应多个意图,基于RNN的Seq2Seq模型倾向于生成语义接近的答案。此外,学习事件背景知识将有助于理解事件并进行If-Then推理任务。为此,我们提出一个上下文感知的变分自编码器以学习事件背景知识并进行If-Then推理任务。实验结果显示相比于基线方法该方法能有效提高推理结果的准确性与多样性。
事件相关常识知识推理近年来日益受到研究者的关注。为此,Rashkin等人(2018)与Sap等人(2018)分别提出了事件相关If-Then类型推理数据集Event2Mind与Atomic。这两个数据集关注于给定事件后,推断事件的原因、结果等知识。同时他们还提出利用经典的基于RNN的Seq2Seq框架以进行此类推理。
然而If-Then推理问题仍存在两个挑战。首先,如图1所示,给定某一事件,对于该事件的感受可能是多样的。对于此类一对多生成问题,研究显示,传统基于RNN的Seq2Seq模型可能倾向于给出某些泛泛的回答(li等人,2016,; Serban等人,2016)。其次,生成合理答案需要建立在对事件背景知识的了解之上。如图1所示,对事件“PersonX finds a job”的感受可能是多样的。然而,在给定事件上下文“PersonX isfired”后,合理的感受将局限于"needy"或"Stressed out"。
为更好应对这两个挑战,我们提出了一个上下文感知的变分自编码器(context-aware variationalautoencoder, CWVAE)。基于变分自编码器的方法被广泛利用于提高一对多生成问题中模型生成的多样性(Bowman等人,2015; Zhao等人, 2017)。在传统变分自编码器的基础上,我们引入了一个额外的上下文感知隐变量(Context aware latent variable)以学习事件背景知识。在预训练阶段,CWVAE在一个故事语料构成的辅助数据集上(包含丰富的事件背景知识)预训练,以使用上下文感知隐变量学习事件背景知识。随后,模型在Atomic/Event2Mind数据集上微调,以使得模型适应各个If-Then推断目标(如事件意图,事件效应等)。
图1 If-Then推理问题的两个挑战同一事件可能使人产生多种感觉。
背景知识有助于If-Then推断过程。
但是这一知识在数据集中并不存在。
3.背景
在介绍Atomic与EventMind数据集以及正式定义问题之前,为清晰起见,我们定义以下术语:
Base event:If-Then推理的前提事件,如图1中的“PersonX finds a new job“。
Inference dimension:特定的If-Then推理类型,如事件意图、事件效应。
Target:推理目标。如图1所示,给定base event “PersonX finds a new job“和Inference dimension"XReact", Target可以是"needy"或"relieved"。注意同一base event可能对应多个 target。
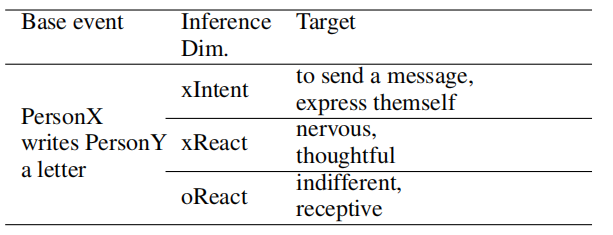
Event2Mind数据集通过众包形式构建,包含约25K条base event,以及300K target。表1展示了一个Event2Mind数据集中的例子。
表1 Event2Mind数据集中的一个例子。”x“和”o“分别指PersonX和others。
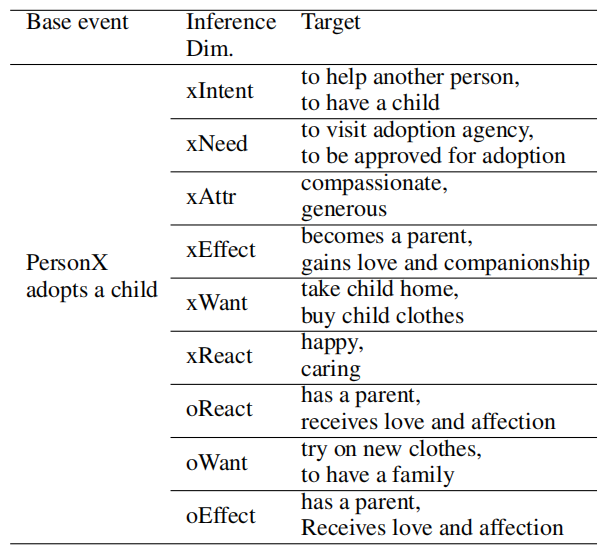
Atomic数据集相比于Event2Mind规模更大。表2展示了一个Atomic中的例子。尽管Atomic同时包含Event2Mind中的inference dimension,二者的base event并不完全相同。
表2 Atomic数据集中的一个例子。”x“和”o“分别指PersonX和others。
问题定义 If-Then推理问题可以定义为一个一对多的条件生成问题:给定base event
![]() ,和一个inference dimension
,和一个inference dimension
![]() ,模型需要生成target
,模型需要生成target
![]() 并使其尽量接近于人工标注,其中
并使其尽量接近于人工标注,其中
![]() 和
和
![]() 均由一系列词构成。
均由一系列词构成。
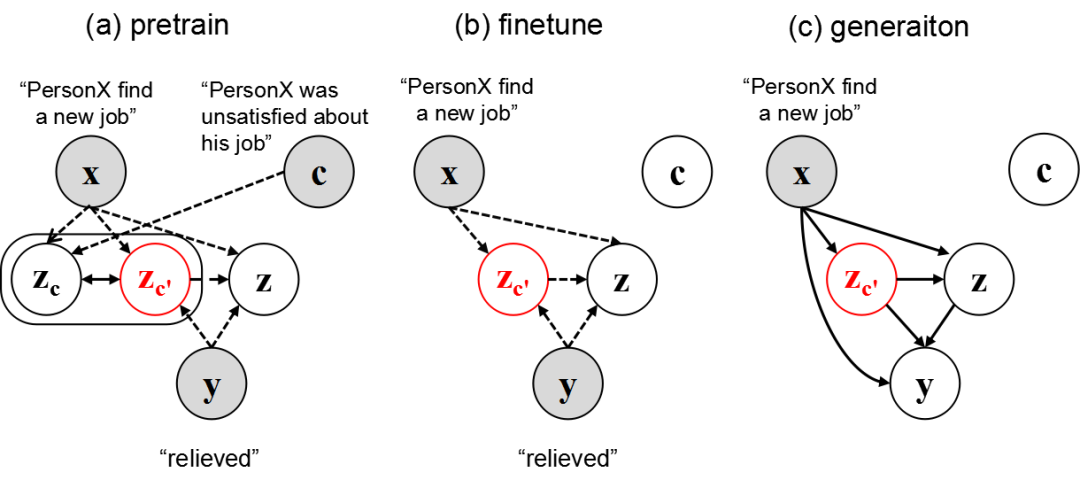
本文将If-Then推理问题概括为[(background), event]-target关系,并利用CWVAE建模这一关系。为实现这一目的,如图2(a)所示,在CWVAE中,我们引入了一个上下文获取隐变量(context-acquire latent variable)
![]() 用以直接获取事件背景知识,和一个上下文感知隐变量(context-aware latent variable)
用以直接获取事件背景知识,和一个上下文感知隐变量(context-aware latent variable)
![]() 用以从
用以从
![]() 处学习事件背景知识。因为Atomic与Event2Mind数据集中并不存在事件背景知识,我们设计了一个两阶段训练过程:
处学习事件背景知识。因为Atomic与Event2Mind数据集中并不存在事件背景知识,我们设计了一个两阶段训练过程:
预训练:
从辅助数据集上学习事件背景知识 如图3(a)所示,在预训练阶段, 上下文获取隐变量能够直接获取到有关于事件上下文
![]() 的知识。随后,通过最小化
的知识。随后,通过最小化
![]() 与上下文感知隐变量
与上下文感知隐变量
![]() 之间的距离,事件背景知识得以从
之间的距离,事件背景知识得以从
![]() 传递至
传递至
![]() 。
微调:
使学到的事件背景知识适应于每个Inference Dimension 如图2(b)所示,在此阶段,CWVAE在Atomic与Event2Mind的每个inference dimension上进行微调。进而,如图2(c)所示,在推断阶段,给定事件后,CWVAE得以利用
。
微调:
使学到的事件背景知识适应于每个Inference Dimension 如图2(b)所示,在此阶段,CWVAE在Atomic与Event2Mind的每个inference dimension上进行微调。进而,如图2(c)所示,在推断阶段,给定事件后,CWVAE得以利用
![]() 中蕴含的有关于事件背景的知识生成targets。
中蕴含的有关于事件背景的知识生成targets。
![]()
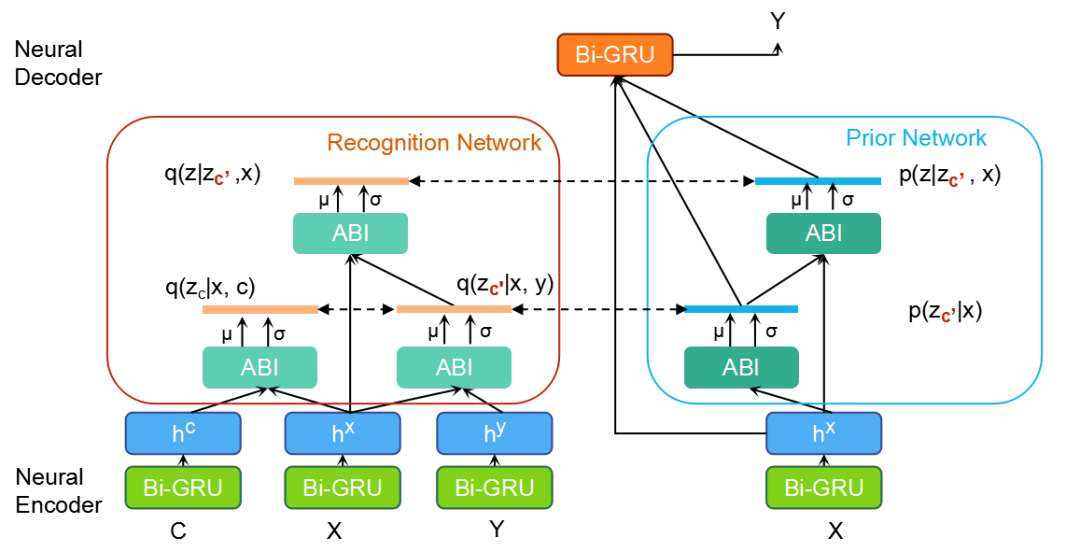
图3展示了CWVAE的具体结构。模型总体分为四部分:编码器(Neural Encoder)将
![]() 与
与
![]() 编码为向量表示,先验网络(Prior Network)建模
编码为向量表示,先验网络(Prior Network)建模
![]() 与
与
![]() ,识别网络(Recognition Network)建模
,识别网络(Recognition Network)建模
![]() ,
,
![]() 与
与
![]() ,解码器(Neural Decoder)则整
,解码器(Neural Decoder)则整
![]() 与
与
![]() 中蕴含的信息以生成
中蕴含的信息以生成
![]() 。
。
![]()
编码器由双向GRU构成,将上下文
![]() , base event
, base event
![]() 与target
与target
![]() 编码至向量表示
编码至向量表示
![]() ,
,
![]() , 与
, 与
![]() 。
。
识别网络利用向量表示
![]() ,
,
![]() ,
,
![]() 建模
建模
![]() ,
,
![]() ,
,
![]() 。上述三个分布均为各向同性的高斯分布(换言之,协方差阵为对角阵)。
。上述三个分布均为各向同性的高斯分布(换言之,协方差阵为对角阵)。
我们提出了一个基于注意力机制的推理模块ABI(Attention Based Inferer)以估计上述分布的均值![]() 和标准差
和标准差![]() :
:
(1)
ABI的具体结构见下文。
先验网络 利用![]() 建模
建模![]() 和
和![]() 。上述两分布同样为各向同性的高斯分布。其均值与方差亦利用ABI估计:
。上述两分布同样为各向同性的高斯分布。其均值与方差亦利用ABI估计:
(2)
其![]() ,
, ![]() 是前馈神经网络。
是前馈神经网络。![]() 是注意力机制中的上下文向量(context vector),
是注意力机制中的上下文向量(context vector), ![]() 是解码器中的隐含状态。我们按照Bahdanau等人(2014)的方式定义
是解码器中的隐含状态。我们按照Bahdanau等人(2014)的方式定义 ![]() 和
和![]() 。但隐含状态
。但隐含状态![]() ,其中
,其中![]() 是
是![]() 中第
中第![]() 个词的词嵌入向量。通过这种方式,在解码过程中CWVAE能够直接利用
个词的词嵌入向量。通过这种方式,在解码过程中CWVAE能够直接利用![]() 中蕴含的事件背景知识。此外,
中蕴含的事件背景知识。此外, ![]() 与
与![]() 中的随机性可以增强生成的多样性。
中的随机性可以增强生成的多样性。
基于注意力机制的推断器 受Parikh等人(2016)的启发,基于注意力机制,我们按以下方式计算
![]() 或
或
![]() 的均值与方差:给定两个向量序列(如上下文与base event的表示 )
的均值与方差:给定两个向量序列(如上下文与base event的表示 )
![]() ,
,
![]() ,我们首先利用互注意力机制(Parikh等人,2016)得到向量序列
,我们首先利用互注意力机制(Parikh等人,2016)得到向量序列
![]() 与
与
![]() 的上下文向量序列
的上下文向量序列
![]() 与
与
![]() 。随后,对于两组上下文向量序列进行平均池化操作可得两个向量
。随后,对于两组上下文向量序列进行平均池化操作可得两个向量
![]() ;
;
![]() 。
。
通过上述操作,![]() 与
与 ![]() 携带了序列
携带了序列![]() 与序列
与序列![]() 的语义交互信息。在
的语义交互信息。在![]() 与
与![]() 的基础上,通过下列操作,我们得到均值
的基础上,通过下列操作,我们得到均值![]() 与标准差
与标准差![]() :
:
(4)
辅助数据集基于三个故事数据集构建:ROCStory(Mostafazadeh等人,2016), VIST(Huang等人,2016),WritingPrompts(Fan等人, 2018)。我们将上述数据集中的每个故事分成长为5句话的子段落,并将每个子段落的前三句话定义为base event的上下文,第四句话定义为base event,第五句定义为target。表3给出了一个例子。
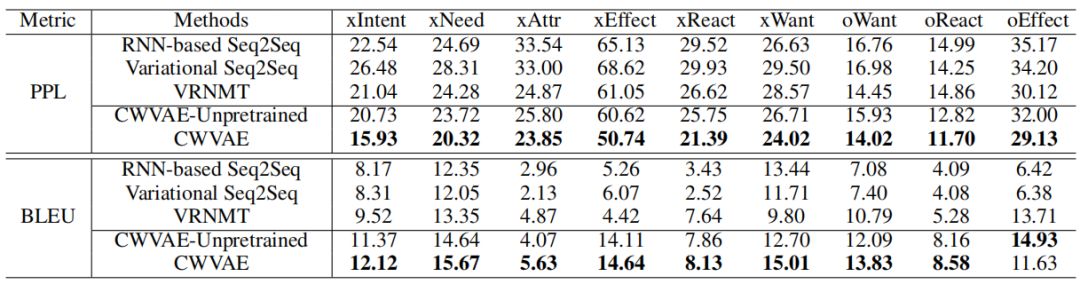
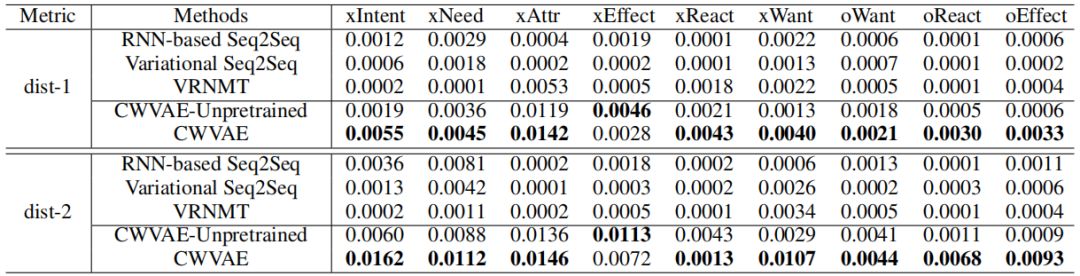
我们使用BLEU与困惑度作为衡量生成准确性的指标,利用distinct-1gram与distinct-2gram的数量作为衡量生成多样性的指标(Li等人, 2017)。此外,我们还从生成的准确性,多样性与流畅性三个角度对模型进行了人工评价。
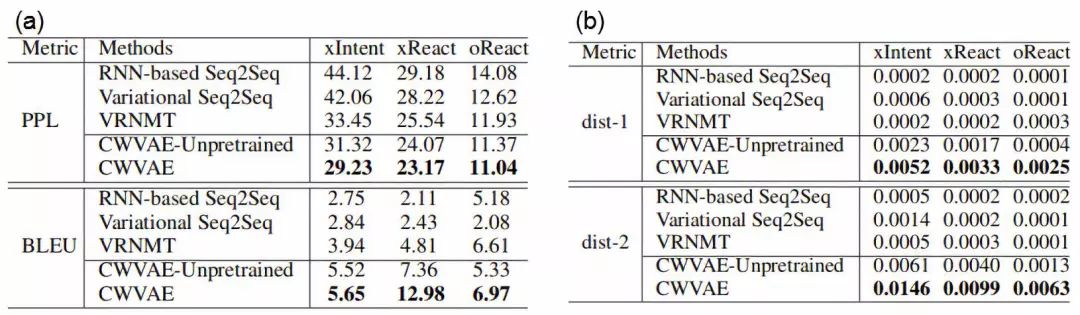
表4 (a) Event2Mind数据集上的perplexity与BLEU score;
(b) Event2Mind数据集上的distinct-1与distinct-2
表5 Atomic数据集上的perplexity与BLEU score
表6 Atomic数据集上的distinct-1与distinct-2
表4--6展示了CWVAE与基线方法在Event2Mind与Atomic上的BLEU与困惑度,以及distinct-1与distinct-2指标。从中可以观察得出:
(1) 通过将基于变分的Variational Seq2Seq,VRNMT, CWVAE-unpretrained以及 CWVAE与其他基于RNN Seq2Seq的模型发现,基于变分法的模型生成的多样性总体而言高于其他基于RNN Seq2Seq的模型。这确认了采用基于变分的模型提高生成多样性的合理性 。
(2) 通过将CWVAE-unpretrained与其他基线模型对比发现,总体而言CWVAE-unpretrained在两个数据集上均表现出了较好的准确性与多样性。这显示了CWVAE在捕获target的潜在语义分布、生成合理推理结果上的能力。
(3) 将CWVAE-unpretrained与CWVAE对比发现,总体而言预训练能够提高模型在准确性与多样性两方面上的表现。这是由于,事件背景知识能够指导推理过程。而通过预训练,模型能够学到事件背景知识。
人工评价结果见表7。总体而言,在两个数据集上,CWVAE也表现出了较好的准确性,多样性与一致性。
表7 (a)Event2Mind数据集上的人工评价结果; (b)Atomic数据集上的人工评价结果
针对If-Then推理问题,本文提出了一个上下文感知的变分自编码器(CWVAE)和一个两阶段的训练过程。利用额外的上下文感知隐变量,CWVAE得以学习事件背景知识,并利用这种知识指导If-Then推理过程。通过两阶段训练过程中的预训练阶段,CWVAE学习事件背景知识。在随后的微调阶段,使得学到的背景知识适应于各类推理目标。实验结果显示CWVAE在两个数据集上均表现出了较高的准确性与多样性。
本期责任编辑:张伟男
本期编辑:王若珂
“哈工大SCIR”公众号
主编:车万翔
副主编:张伟男,丁效
执行编辑:李家琦
责任编辑:张伟男,丁效,崔一鸣,李忠阳
编辑:赖勇魁,李照鹏,冯梓娴,王若珂,顾宇轩
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公众号:”哈工大SCIR” 。
![]()

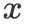 ,和一个inference dimension
,和一个inference dimension
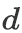 ,模型需要生成target
,模型需要生成target
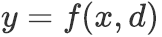 并使其尽量接近于人工标注,其中
并使其尽量接近于人工标注,其中
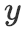 均由一系列词构成。
均由一系列词构成。
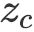 用以直接获取事件背景知识,和一个上下文感知隐变量(context-aware latent variable)
用以直接获取事件背景知识,和一个上下文感知隐变量(context-aware latent variable)
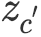 用以从
用以从
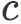 的知识。随后,通过最小化
的知识。随后,通过最小化
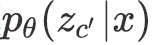 与
与
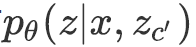 ,识别网络(Recognition Network)建模
,识别网络(Recognition Network)建模
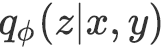 ,
,
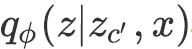 与
与
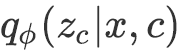 ,解码器(Neural Decoder)则整
,解码器(Neural Decoder)则整
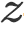 与
与
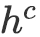 ,
,
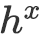 , 与
, 与
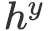 。
。
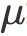

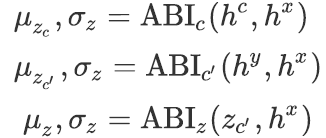
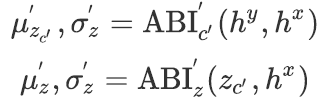
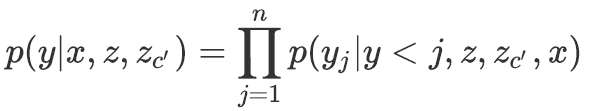
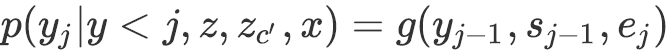
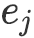
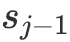
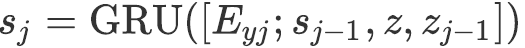

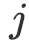
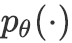 或
或
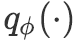 的均值与方差:给定两个向量序列(如上下文与base event的表示 )
的均值与方差:给定两个向量序列(如上下文与base event的表示 )
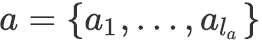 ,
,
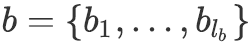 ,我们首先利用互注意力机制(Parikh等人,2016)得到向量序列
,我们首先利用互注意力机制(Parikh等人,2016)得到向量序列
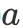 与
与
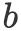 的上下文向量序列
的上下文向量序列
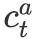 与
与
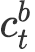 。随后,对于两组上下文向量序列进行平均池化操作可得两个向量
。随后,对于两组上下文向量序列进行平均池化操作可得两个向量
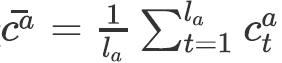 ;
;
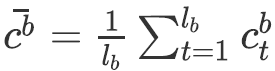 。
。