

**论文题目:**Editing Large Language Models: Problems, Methods, and Opportunities **本文作者:**姚云志(浙江大学)、王鹏(浙江大学)、田博中(浙江大学)、程思源(浙江大学)、黎洲波(浙江大学)、邓淑敏(新加坡国立大学)、陈华钧(浙江大学)、张宁豫(浙江大学) 发表会议:EMNLP 2023
**论文链接:**https://aclanthology.org/2023.emnlp-main.632.pdf **代码链接:**https://github.com/zjunlp/EasyEdit
欢迎转载,转载请注明出处****

**
**
一、引言
随着深度学习与预训练技术的快速发展,大语言模型如ChatGPT、LLaMA、ChatGLM、Baichuan、通义等在自然语言处理领域已经取得了显著的突破。然而,这些大语言模型在学习和理解知识方面仍然存在一些挑战和问题,包括知识更新的困难,以及模型中潜在的错误、偏差和安全隐患等。本文初步探讨了大语言模型知识编辑相关的问题、方法和机遇。
二、模型知识编辑定义
模型知识编辑旨在高效地修改模型在特定输入或领域内的行为,且避免对其他输入产生负面影响。如下图所示,通过模型知识编辑可以实现将事实知识从(美国,总统,特朗普)到(美国,总统,拜登)的高效更新,且不影响其他与之无关的知识。
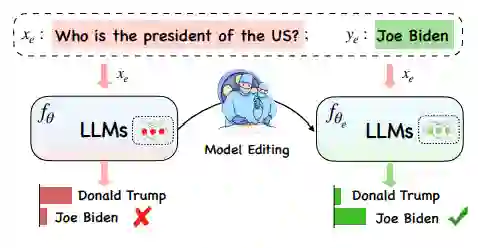
具体的说,模型知识编辑的主要目标是有效地调整基础模型(其中表示模型的参数)在特定编辑描述符上的行为,同时不影响模型对其他样本的行为。最终目标是创建一个编辑后的模型,记为。 给定一个包含编辑输入 和编辑标签(输出) 的编辑描述符,我们期望编辑后的模型产生输出。模型编辑过程通常会影响一系列与编辑实例密切相关的输入的预测,这些输入的集合被称为编辑范围(Editing Scope)。成功的模型知识编辑方法应该可以适用于编辑范围内的所有实例,同时确保不会影响范围外实例的行为。 衡量模型知识编辑的效果一般有以下几个指标: * 可靠性(Reliability):在给定编辑描述下编辑的成功率,这是模型知识编辑任务最基础的要求。常使用在给定编辑描述下,应用编辑方法后,模型的准确率。 * 泛化性(Generalization):在给定编辑描述下,模型在编辑范围内的成功率。常使用在编辑范围内输入集合下,应用编辑方法后,模型的准确率。 * 局部性(Locality):即编辑后的模型不应改变与编辑无关实例的输出。换句话说,编辑操作应专注于特定的知识点或行为,而不影响模型在其他方面的性能。
三、方法
本文梳理了现有的模型知识编辑方法,并将其分为两种范式:修改模型的参数和保留模型的参数。
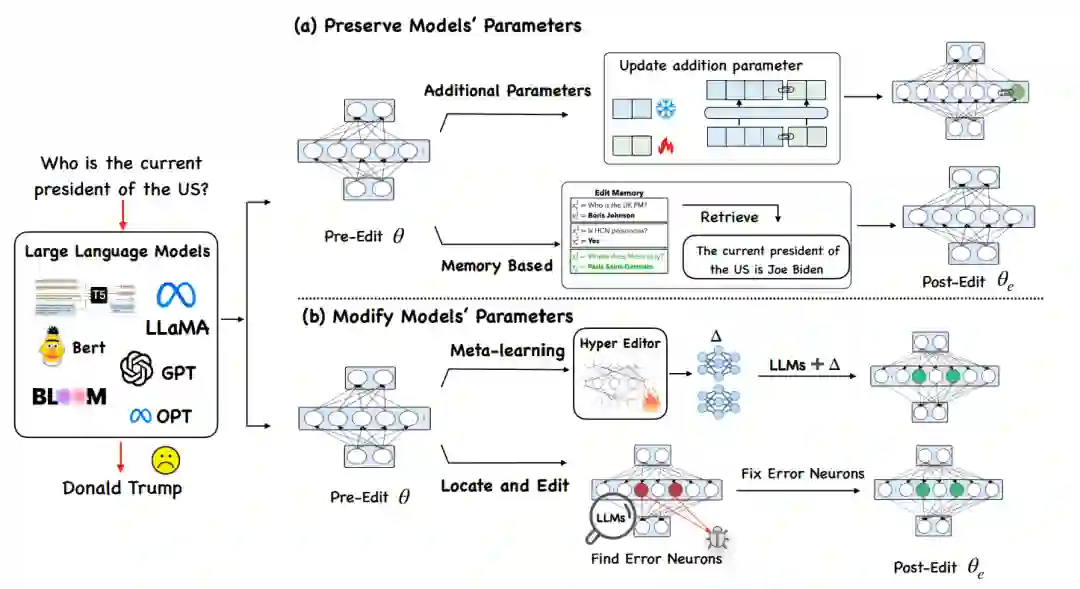
3.1 保留大语言模型参数的方法:
- 基于Memory的方法:这种方法的核心在于将所有编辑示例明确存储在Memory中,并通过一个检索器来提取针对每个新输入最相关的编辑事实,从而引导模型生成相应的编辑事实。SERAC(Mitchell et al. 2022b)就是这种方法的一个典型代表。它采用了一种独特的“反事实模型”(Counterfactual Model),在保留原始模型不变的情况下,引入了额外的处理机制。具体来说,SERAC使用了一种“范围分类器”(Scope Classifier)来计算新输入是否属于存储编辑示例的范围。如果输入与Memory中缓存的任何编辑匹配,那么反事实模型的预测就基于这个输入和最可能的编辑。而如果输入超出了所有编辑的范围,就会给出原始模型的预测。
此外,近期的研究表明,LLMs具有强大的“上下文学习”(In-Context Learning)能力。这意味着模型可以在没有额外新事实模型训练的情况下,仅通过以精炼的知识上下文作为提示,自行生成与提供知识相对应的输出。这类方法通过用编辑事实和从编辑内存中检索的编辑示例提示模型来编辑语言模型,包括MemPrompt(Madaan et al. 2022)、IKE(Zheng et al. 2023)和MeLLo(Zhong et al. 2023)等相关工作。
- 额外参数的方法:这是一种在语言模型中引入额外可训练参数的方法。T-Patcher模型(Huang et al. 2023)是这种方法的一个代表。它在模型的前馈网络(Feed-Forward Network, FFN)的最后一层集成了一个神经元(称为“补丁”),专门用于纠正一个特定的错误。这个“补丁”仅在遇到其对应的错误时才发挥作用。CaliNET模型(Dong et al. 2022)则采用了不同的策略,它集成了几个神经元来处理多个编辑案例。与此不同的是,GRACE模型(Hartvigsen et al. 2022)维护了一个作为适配器(Adapter)的离散代码簿,通过随时间添加和更新元素来编辑模型的预测。这些方法通过在语言模型内部引入额外的可训练参数,提供了一种新的途径来修改和更新模型中的知识。这种方法的优势在于能够在不影响原始模型参数的情况下,针对性地进行知识更新和错误纠正。
3.2 修改大语言模型参数的方法:
基于Mete-learning:这类方法利用超网络(Hyperetwork)来学习编辑大语言模型知识的权重变化量(Δ)。Knowledge Edit(De Cao et al. 2021)采用了一个双向长短期记忆网络(Bidirectional-LSTM)作为超网络,来预测每个数据点的权重更新。然而,KE编辑较大的语言模型时,效果并不是很好。为了解决这种问题,MEND(Mitchell et al. 2022)采用了一种新的策略。MEND通过运用梯度的低秩分解(Low-rank Decomposition)减少了计算量,从而更好地编辑大语言模型。 * Locate-and-Edit:这类方法首先识别定位特定知识相关的参数,然后通过直接更新目标参数来修改它们。Knowledge Neuron(Dai et al. 2022)引入了一种“知识归因”(Knowledge Attribution)技术,用于精确定位体现知识的“知识神经元”(即前馈网络(FFN)矩阵中的关键值对),然后更新这些神经元。ROME(Meng et al. 2022)应用因果中介分析(Causal Mediation Analysis)来定位编辑区域。与KN方法不同,ROME修改了整个FFN的第二个线性变化矩阵。ROME将模型编辑视为具有线性等式约束的最小二乘问题,并使用拉格朗日乘数法来解决它。然而,KN和ROME方法都只能一次编辑一条事实知识。为了解决这个局限性,MEMIT(Meng et al. 2023)在ROME的基础上进行了扩展,实现了多个事实知识的同步编辑。在MEMIT的基础上,PMET(Li et al. 2023)引入了注意力值(Attention Value)以获得更好的性能。
四、实验
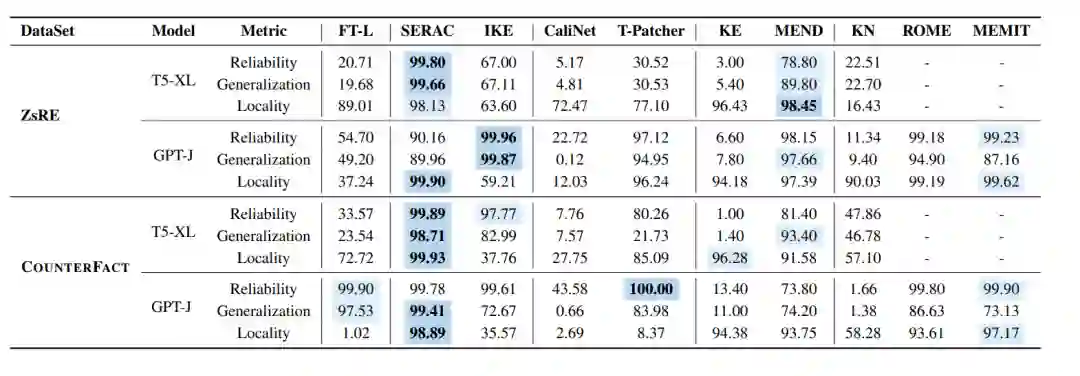
本文在T5-XL和GPT-J上详细比较了不同模型知识编辑方法在ZsRE和CounterFact数据集上的性能。 SERAC和ROME这两种方法在两个数据集上表现较好。SERAC在几项指标上超过90%。ROME也展示了令人印象深刻的表现。MEMIT尽管在泛化方面稍显不足,但在可靠性和局部性方面表现出色。KE, CaliNET, 和KN:这些方法在小型语言模型上表现尚可,但在更大的语言模型上表现一般。 T-Patcher其性能在不同的模型架构和大小中波动。例如,在ZsRE数据集的T5-XL上表现不佳,而在GPT-J上则表现较好。在CounterFact数据集上,T-Patcher在T5上实现了较好的可靠性和局部性,但缺乏泛化能力。相反,在GPT-J上,模型在可靠性和泛化方面表现出色,但在局部性方面表现不佳。 我们也比较了FT-L与ROME,FT-L微调了ROME修改的相同的位置,相比于编辑方而言,FT-L在大语言模型上的效果较为一般。IKE在可靠性方面表现良好,但在局部性方面存在困难,因为prompt可能影响不相关的输入。其泛化能力也有待提高。上下文学习方法可能存在上下文指令遵循失败的问题,因为预训练的语言模型可能不会一致地生成与提示一致的文本。
Batch Edit

本文还对批量编辑(Batch Editing)进行了深入分析。这是因为许多研究通常仅限于更新几十个事实或仅关注单一编辑案例。然而,在实际应用中,经常需要同时修改模型中的多个知识点。本文选择了对批量编辑支持较好的方法(如FT, SERAC, MEND和MEMIT)进行了测试。 MEMIT支持大型语言模型(LLMs)的大规模知识编辑,允许同时进行数百甚至数千次编辑,同时保持最小的时间和内存成本。它在可靠性和泛化性方面的表现保持稳健,但其局部性有所下降。SERAC批量编辑的情况下效果也很不错。但SERAC在处理更多案例时需要更多的的内存消耗。而MEND和FT-L在批量编辑方面的表现不太好,随着编辑数量的增加,模型性能迅速下降。
Sequential Edit
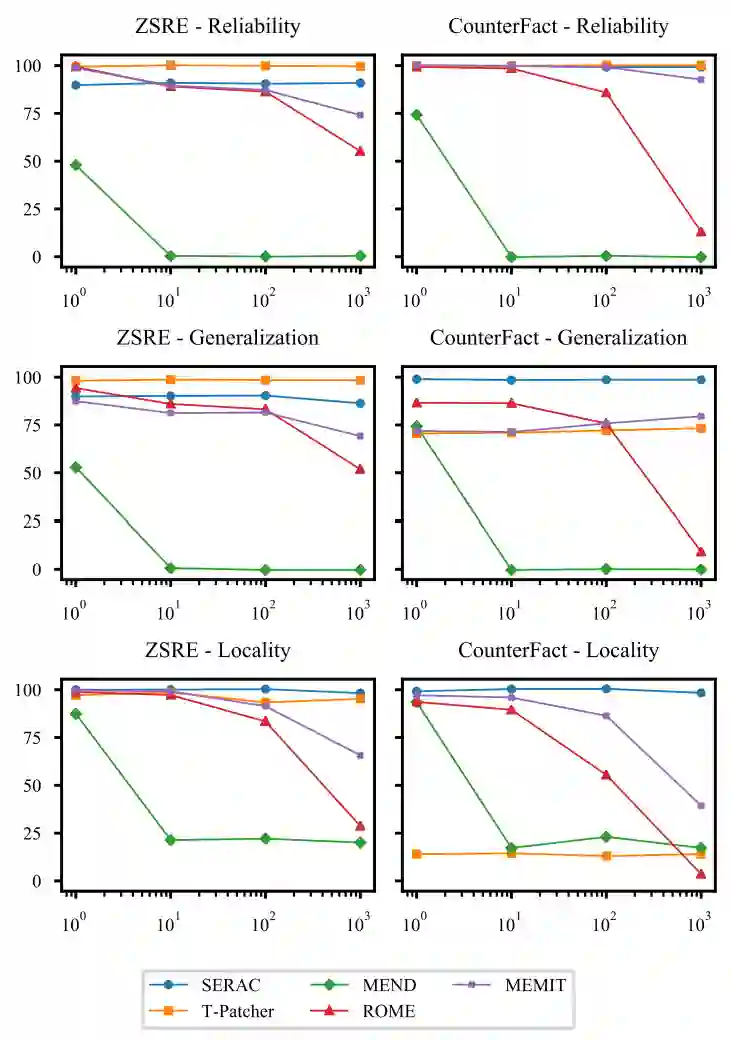
本文继续探讨了持续知识编辑(Sequential Editing)的性能。持续知识编辑是指在进行新的编辑操作时,模型应保留之前的更改,即模型具备持续不断更新模型知识的能力。这是模型知识编辑中的一个关键特性。本文发现ROME,MEMIT和MEND这一类方法需要编辑模型的参数,随着编辑数量的上升,模型的表现会有比较明显的下降,MEND在超过10次的连续编辑后成功率就直线下降。而类似于SERAC和T-Patcher这类保留了模型的原有参数的情况下,模型的连续编辑效果则比较平稳,没有随着编辑次数的增多而下降。
五、分析
5.1 Portability
本文还发现现有的模型知识编辑数据集的构造及评估指标很大程度上只关注句子措辞上的变化,但是并没有深入到模型知识编辑对许多相关逻辑事实的更改,因此,本文引入了“可迁移性(Portability)”指标,衡量编辑后的模型在知识迁移方面的有效性。本文考虑了三种场景:Subject-Alias, Reversed-Relation以及One-hop Reasoning。

主语替换(Subject Replace):由于大多数改写句子只是对关系进行重新表述而保留主语描述,因此通过将问题中的主体替换为别名或同义词来测试泛化能力。这测试了模型是否能将编辑的属性泛化到同一主体的其他描述上。 * 反向关系(Reversed Relation):当编辑主体和关系的目标时,目标实体的属性也会改变。通过筛选合适的关系(如一对一关系)并询问反向问题,测试模型处理这一点的能力,以检查目标实体是否也得到了更新。 * 一跳推理(One-hop):修改后的知识应该能够被编辑的语言模型用于下游任务。譬如如果将“Watts Humphrey 就读哪所大学”的答案从Trinity College改为University of Michigan,显然如果当我们问模型“Watts Humphrey 大学时期居住于哪个城市?”时,理想模型应该回答Ann Arbor而不是Dublin。
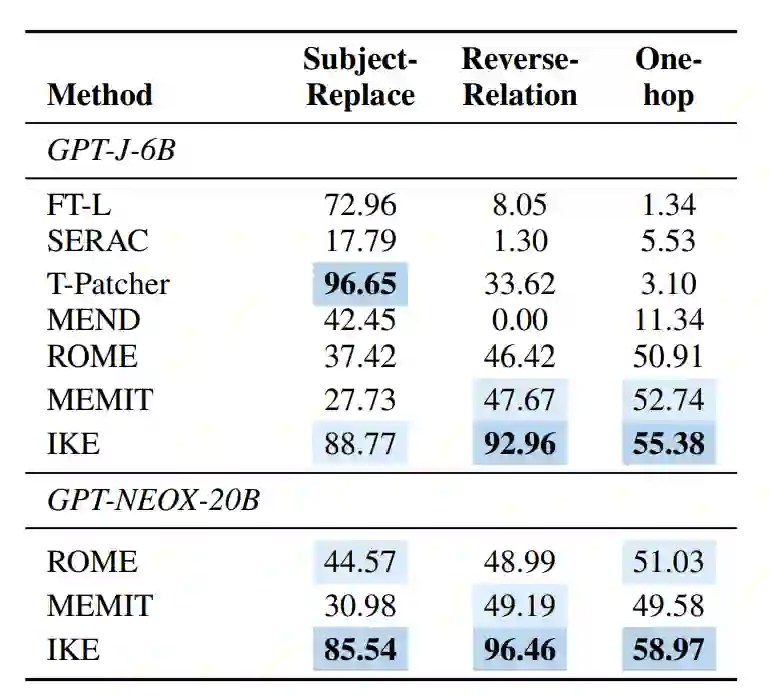
如上表格所示,当前模型知识编辑方法在可迁移性方面的表现欠佳。例如,尽管SERAC在之前的指标上表现出色,但在所有三个可迁移性方面的准确率均不到20%。SERAC的瓶颈在于分类器的准确性和附加模型的能力。 在主语替换场景中,包括SERAC、MEND、ROME和MEMIT在内的方法只能适应特定的主体实体表达,但无法泛化到主体实体的概念。然而,FT-L、IKE和T-patcher在面对替代主体时表现较好。 在反向关系方面,结果表明,当前的编辑方法主要编辑单向关系,IKE是一个显著的例外,在GPT-J和GPT-NEOX-20B上都实现了90%以上的成绩。其他方法改变了主体实体的属性,但没有影响目标实体。 在一跳推理设置中,大多数编辑方法都难以将更改的知识转移到相关事实上。相对而言,ROME、MEMIT和IKE在可移植性方面表现较好(超过50%)。
5.2 Side Effect
本文还从三个不同层面评估了模型知识编辑潜在的副作用:

- 属性(部分)知识是否被改变(Other Attribution):本文认为,在编辑之后模型应保持主体的关键属性不发生变化。比如修改Grant Hill的职业时,不应该影响Grant Hill的国籍属性。
- 事实知识是否会被干扰(Distract Neighbourhood):之前的工作如Hoelscher-Obermaier et al. (2023)发现,如果在其他的输入前拼接编辑的实例,模型倾向于受编辑事实的干扰,并继续产生与编辑相关的结果而不是具体的问题。
- 其他任务性能影响(Other Tasks):基于Wang et al. (2022)的Skill Neuron理论,即大型语言模型的前馈网络具有特定任务知识能力,而我们编辑语言模型的知识时,很有可能对影响模型的能力,因此本文使用了PIQA数据集来评估模型知识编辑是否可能对其他任务(常识推理)的性能产生负面影响。
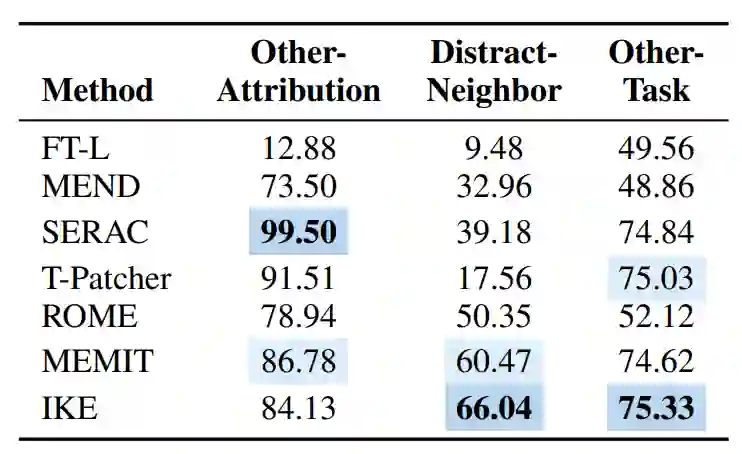
从表格中可以看到当前的编辑方法在“Other Attribution”方面表现出色,表明它们只修改目标特征而不影响其他属性。而FT-L则很容易破坏知识的结构。 然而,在“Distract Neighbourhood”设置中,模型知识编辑的表现普遍较差,这反映在与表格中的结果相比性能下降。IKE是一个例外,由于其固有要求编辑事实在输入之前拼接,其性能相对稳定。 对于”Other Task“ (常识推理)任务,保留参数的方法在其他任务上大体保持了性能。相反,改变参数的方法往往对性能产生负面影响。不过尽管同样改变了参数,MEMIT在常识任务上保持了不错的结果,具有较好的局部性。
六、总结与展望
本文初步分析了模型知识编辑的潜在学术和应用价值,模型知识编辑技术在分析和理解大语言模型的知识机理,以及探究大语言模型的涌现行为和泛化能力等方面可能有一定的帮助。此外,探索如何有效管理知识编辑过程中的复杂交互效应,以及如何提高通用知识编辑方法的精确性和可靠性也是未来研究的关键方向。