ACL 2019 | 多语言BERT的语言表征探索
论文链接:https://arxiv.org/abs/1906.01502
编辑 | 唐里
这篇论文的作者是来自于Google Research的Telmo Pires,Eva Schlinger和Dan Garrette。既然BERT能够在每一层都学习到特殊的表层、句法以及语义特征表示,那么多语言BERT(M-BERT)在上面学到了什么呢?多语言BERT在零样本迁移学习上又表现如何呢?
本文尝试着回答这些问题,作者基于Devlin et al发布的用104种语言组成的单一语料库训练的单个多语言BERT模型,在上面做了一系列实验,最终结果显示多语言BERT在跨语言的零样本迁移学习上表现得非常好。作者设计了一些标注任务,这些任务在一种语言上对该任务进行微调,最后再在另一种语言上进行评估。
除此之外,为了理解为什么会有好的效果以及跨语言泛化表现的程度,作者还设计了探测实验,该实验展示了诸如迁移学习甚至有可能在不同的脚本上进行,以及迁移学习在两种相似的语言上表现得非常好等等。另外探测实验还表明,虽然多语言BERT的多语言表示能够将学习到的结构映射到词汇表,但是似乎没有学习到这些结构的系统转换以适应于具有不同词序的目标语言。
1 模型和数据
多语言BERT是一个由12层transformer组成的预训练模型,它的训练语料包含了104种语言的维基百科页面,并且共享了一个词汇表。值得注意的是,多语言BERT在训练的时候既没有使用任何输入数据的语言标注,也没有使用任何翻译机制来来计算对应语言的表示。
作者利用两个任务进行实验,实体命名识别(NER)和词性标注(POS),这两个任务都具有相似的特征,均可以使用序列标注的网络来进行。
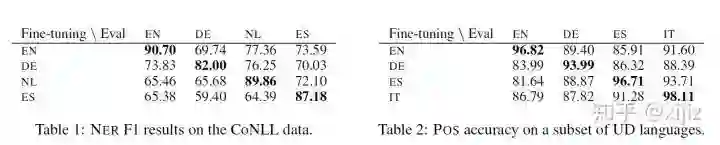
(图3-1. NER和POS实验结果)
如图3-1所示,该图是NER和POS的跨语言迁移学习实验结果,我们可以看到在相似的语言上进行迁移学习会比较好。最极端的例子就是微调和评估都使用一种语言,这种效果是最好的,所以我们可以看到图表中最好的分数都在对角线上。
3.2. 词典记忆
由于多语言BERT使用单个的多语言词典,所以当在微调期间出现的单词也出现在评估语言中时,这会发生一种跨语言的转换迁移,作者称这种现象为词汇重叠(overlap)。作者设计了探测实验来探索这种跨语言的转换迁移有多大程度上是依赖于这种重叠,以及这种转换迁移能否发生在不同的语言文本上,也就是没有重叠现象发生的时候。
如果多语言BERT的泛化能力很大程度上是依赖于词典记忆,那么我们也可能会看到NER在零样本迁移学习上的表现会依赖于词汇重叠。为了测量这个影响,作者计算了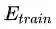

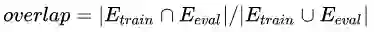
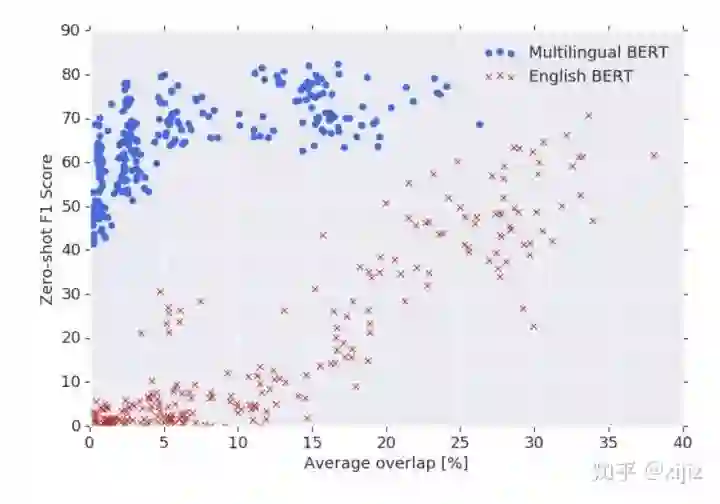
(图3-2. 零样本NER迁移学习与跨语言重叠实验对比图)
如图3-2,该示意图是零样本NER迁移学习F1分数与16种语言重叠实验的对比结果,包含了多语言BERT和英文BERT。我们可以看到英文BERT的性能表现非常依赖于词汇重叠,迁移学习的能力会随着重叠率的下降而逐渐下降,甚至在完全不同的语言文本中(即重叠率为0)出现F1分数为0的情况。但是多语言BERT则在大范围重叠率上表现得非常平缓,即使是不同的语言文本,这证明多语言BERT在某种程度上拥有超过浅层词汇级别的深层次表征能力。
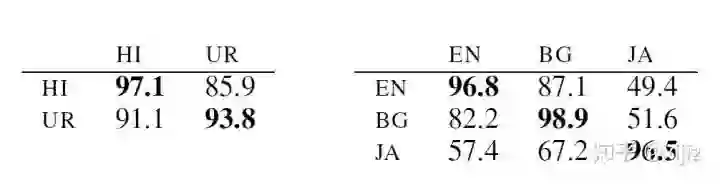
(图3-3. 在不同的语言文本上的POS实验准确率示意图)
为了深入研究多语言BERT为何能在不同的语言文本上具有良好的泛化能力,作者在词性标注任务POS上做了一些实验尝试,结果如图3-3所示。我们可以看到,多语言BERT在只有阿拉伯文(UR)的数据集上进行POS任务的微调,在只有梵文(HI)上的数据集进行测试,仍然达到了91%的准确率,这是令人非常惊讶的。这表明多语言BERT拥有强大的多语言表征能力。
但是,跨语言文本迁移却在某些语言对上表现出糟糕的结果,比如英文和日语,这表明多语言BERT不能在所有的情况下都表现良好。一个可能的解释就是类型相似性,比如英语和日语有不同的主语、谓语以及宾语顺序,但是英语却和保加利亚语(BG)有相似的顺序,这说明多语言BERT在不同的顺序上泛化性能不够强。
3. 语言结构编码
从前面我们可以看到,多语言BERT的泛化能力不仅仅归功于词典记忆,而且还归功于深层次的多语言表征。为了更深入的了解这种表征的本质,作者设计了一系列实验来更深入了解这种表征。
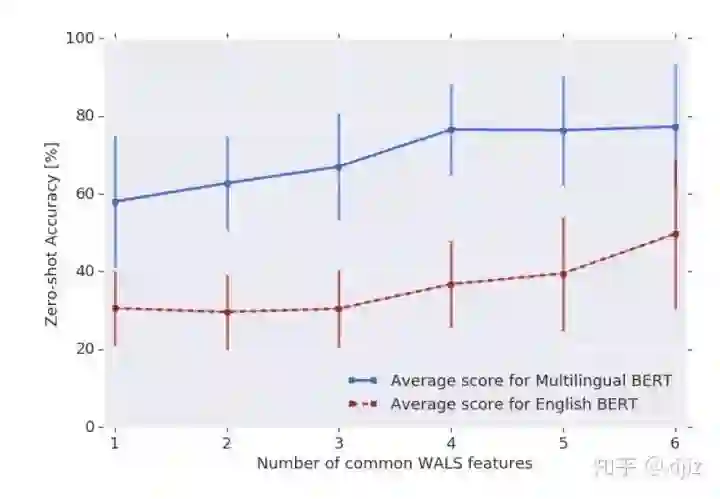
(图3-4. 在零样本迁移学习上POS准确率与WALS特征的对比图)
WALS是与语法结构相关的特征,图3-4展示了多语言BERT在零样本迁移学习上POS任务的准确率与WALS特征数量的对比图。我们可以看到,准确率会随着语言相似度的提升而提升,这证明多语言BERT对具有相似特征的语言的迁移学习更加友好。

(图3-5. POS迁移学习宏平均准确率在不同语言学特征上的对比图)
语言的顺序类型特征一般包括这两种,主谓宾(subject/verb/object, SVO)顺序或者形容词名词(adjective/noun, AN)顺序。图3-5展示了在POS任务上进行的跨语言迁移学习的宏平均准确率与语言类型特征的对比。我们可以看到性能表现最好的情况是语言类型特征一样(SVO和SVO,SOV和SOV,AN和AN以及NA和NA)的迁移学习,这表明虽然多语言BERT能够学习到一定的多语言表征,但是似乎没有学习到这些语言类型结构的系统转换去适应带有不同语言顺序的目标语言。
为了探索多语言BERT在多语言文本混合(Code-switching)和音译(transliteration)的情况下表征能力如何,作者进一步在UD语料库上测试了印地语(HI)和英语(EN)。多语言文本混合是指一个表达里面参杂多种语言,而音译则指将发音相似的外来词语直接通过读音翻译过来,比如酷 (cool)和迪斯科(disco)等。
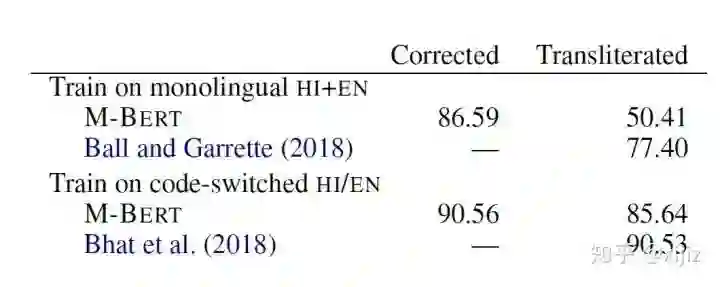 (图3-6. 多语言文本混合以及音译下的POS准确率)
(图3-6. 多语言文本混合以及音译下的POS准确率)
如图3-6所示,该图表是多语言BERT在多语言文本混合和音译下的词性标注任务的准确率结果,其中transliterated代表印地语是以拉丁文的方式书写,而corrected则代表印地语是以梵文的方式书写。我们可以看到,对于corrected的输入,多语言BERT的性能在单个语料库(HI+EN)上与多语言文本混合(HI/EN)表现相当,这进一步正面多语言BERT能够有效地表征多语言信息。可是对于transliterated的输入,这两者的表现就差得挺远,这证明预训练语言模型只能在某些语言上较好地进行迁移学习。
3.4. 特征空间的多语言表征
作者还设计了一个实验探索多语言BERT在特征空间上的多语言表征。作者首先从数据集WMT16中采样了5000个句子对,将句子分别输入到没有经过微调的多语言BERT。然后抽取每个句子在BERT每一层的隐藏特征向量(除开[CLS]与[SEP])并取平均,得到一个表示 。我们计算从一种语言到另一种语言的向量表示: ,这里M是句子对数量。当我们翻译每个句子 时,我们通过 
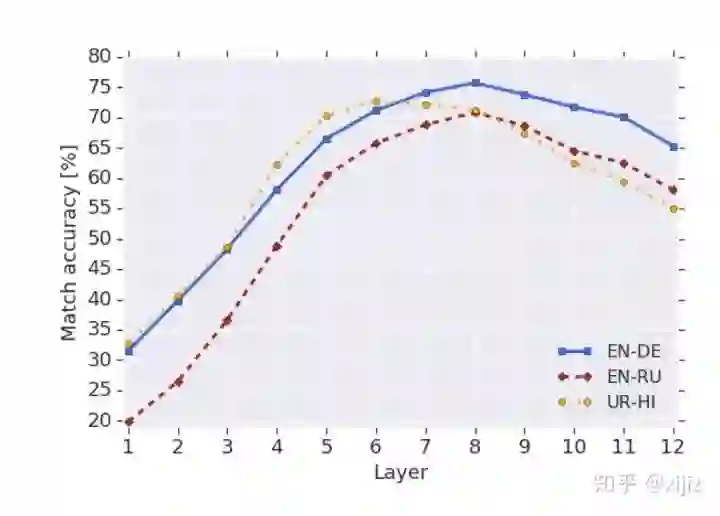
(图3-7. 翻译任务上的最近邻准确度结果图)
如图3-7所以,该图是翻译任务上的最近邻准确度在BERT每一层网络上的结果。我们可以看到,在BERT的非底层网络都实现了较高的准确率,这说明多语言BERT可能一种语言无关的方式,在大多数隐藏层共享语言特征表示。至于为什么在最后几层网络上准确率又下降了,一个可能的解释就是BERT在预训练的时候需要明确与语言相关的信息去预测缺失的单词。