【泡泡图灵智库】基于草图的图像检索的零元学习
泡泡图灵智库,带你精读机器人顶级会议文章
标题:Doodle to Search: Practical Zero-Shot Sketch-based Image Retrieval
作者:Sounak Dey, Pau Riba, Anjan Dutta, Josep Llados, Yi-Zhe Song
来源:CVPR2019
播音员:
编译:李永飞
审核:尹双双
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——Doodle to Search: Practical Zero-Shot Sketch-based Image Retrieval,该文章发表于CVPR2019。
本文研究了基于草图的图像检索的零元学习问题,即给定一幅学习过程中未见过的类别的手绘草图,在图像数据库中搜索其对应的图像。本文提出了一种新的基于草图的图像检索的零元学习方案,从而推动了这一问题的解决。本文的方案主要针对基于草图的图像检索的零元学习中存在的两个重要却经常被忽略的问题:1)不专业的手绘草图域和真实图像域之间存在很大的差异;2)大规模图像检索的需求。首先,本文创建了一个新的数据集QuickDrawExtended。该数据集由330000幅草图和204000幅图片组成,包含了110个类别的物体。已有的数据集的草图往往比较类似于真实图片,不同于以往的数据集,本文专门挑选了高度抽象的不专业的手绘草图,以最大化域间的差异。为减小域间差异,本文提出了一种新的互信息挖掘方式。并使用外部的语义信息,以辅助语义迁移。令人很意外的是,在已有的数据集上,即使是本文的简化版本,比起当前最优的方法,也能取得更好的效果。在新的数据集上,本文的完整模型比起已有的方法,性能提升很多。为推动这一问题的研究,本文公开了所有的数据集和代码。
主要贡献
本文的主要贡献为:
1) 提出了一个新的草图检索数据集,该数据集中的草图更加抽象,从而保证草图域和图像域存在足够大的差异,且该数据集中的草图来自于不同的人,保证了草图的风格多样性;
2) 设计了一个域分离策略,以弥补域间的巨大差异,这是通过引入梯度反转层(GRL)实现的,该层鼓励编码器从草图和图片中提出互信息;
3) 提出了一种语义损失函数,以保证学习到的中间域能够保留下语义信息。
算法流程
PS:本文研究的是基于草图的图像检索的零元学习问题,即通过给定一幅手绘草图,在数据库中找到其对应的图像,且要求模型能够应对在学习阶段没有见过的图像,即零元学习。由于草图和真实图片之间存在巨大的差异(域间距离大),且要求能够处理训练中不存在的类别,传统的分类网络不适用这类问题。在本文中,作者通过学习一个中间域的方式来解决这类问题,即:通过学习的方法,分别学习一种映射,将草图和真实图片映射的同一流形空间中,在该空间中,类内的差异尽可能小,类间的差异尽可能大。这样草图和真实图片就能用同一参数空间来表达,而后通过最近邻搜索,就能确定草图对应的真实图片。这样既可以处理域间的巨大差异,也可以应对训练模型未看过的分类的情况。下面来具体介绍本文的方法:
1、网络架构
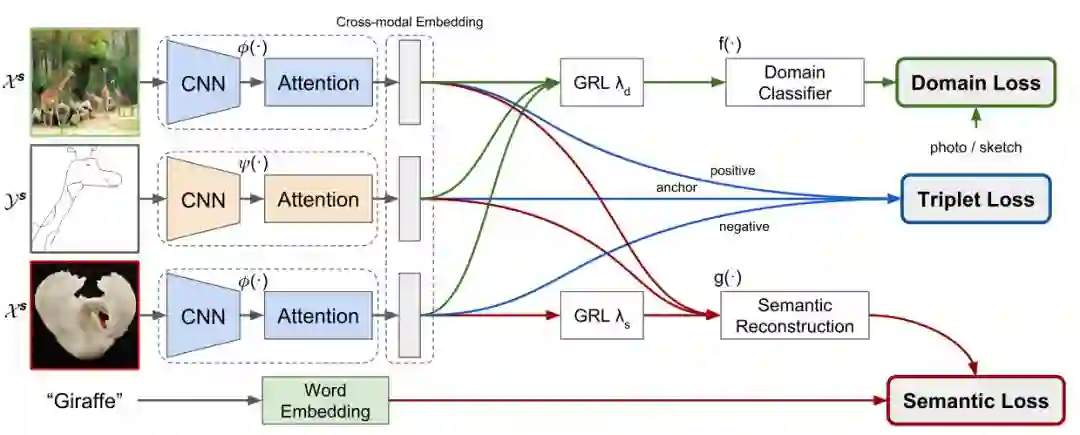
图1. 本文算法的架构。
如图1所示,本文需要学习的即为图片域到中间域的映射关系
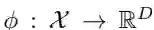
以及草图到中间域的映射关系
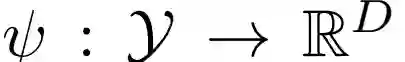
学习的目标是

其中x1和x2来自于图片域,y来自于草图域,且x1和y对应相同类别,x2和y是不同的内别。
2、损失函数
本文采用三种损失函数,即:三元组损失函数、域损失函数以及语义损失函数。
1)三元组损失函数:对于一组训练样本a,p,n, 其中a为草图样本,p为对应的同类别的图片正样本,n为非同一类别的图片负样本,定义三元组损失函数如下:
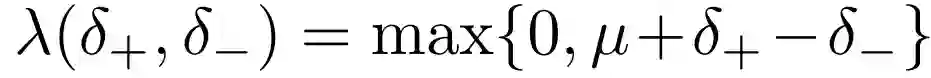
其中,
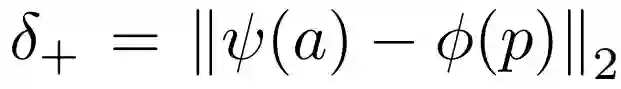
表示在中间域上,正样本和草图的差异,
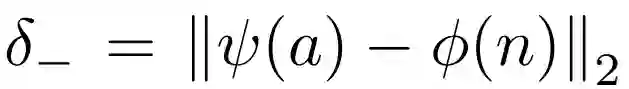
表示在中间域上,负样本与草图的差异。
上式的定义表示,我们希望在学习得到的中间域上,属于同一类的草图和图片之间的差异要比不同类草图和图片之间的差异小一定的阈值,当到达这一阈值的时候,不对参数进行调整(误差为0),否则对网络参数进行调整,以使得网络满足这一要求。
2)域损失函数:域损失函数约束网络,使得草图和真实图片转换到同一中间域。具体的做法为:训练一个分类器,来分辨转换后的图片和草图,当该分类器无法分辨中间域的一个向量是来自图片还是来自草图时,说明图片和草图确实被映射到了同一中间域。因此,域损失函数的定义为分类函数的交叉熵,即:
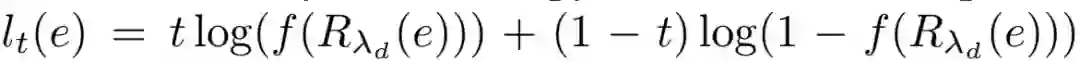
对于一组样本,对应的域损失为:
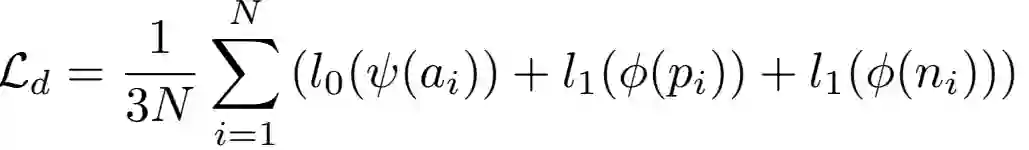
3)语义损失函数:网络训练得到的中间域应该能够尽可能多的保留草图和真实图片的语义信息。本文通过word2vec方法,从中间域重构得到语义向量,通过与对应的语义向量的真值的比对,得到语义损失,即:
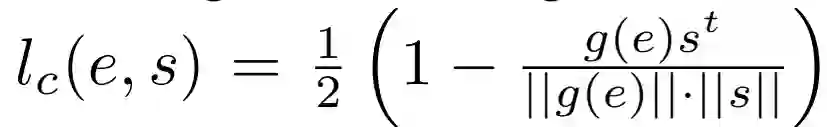
其中g为语义重构函数,s为对应的语义向量真值。
对于一组样本,语义损失函数为:
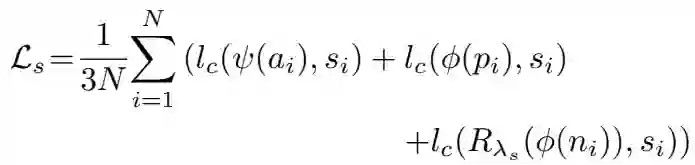
主要结果
本文在三个数据集Sketchy-Extended, TUBerlin-Extended和QuickDraw-Extended上进行了实验,主要验证了本文提出的数据集的重要意义,以及本文方法的有效性。主要的结果如下:

表1. 本文方法和当前最优方法的性能比较。本文的方法和CVAE使用相同的训练集和测试集。由于ZSIH没有说明其实现的细节,因此不知道其测试集和训练集的分割方法。且它没有提供开源的代码,因此在QuickDraw-Extended数据集上无法得到其数据。
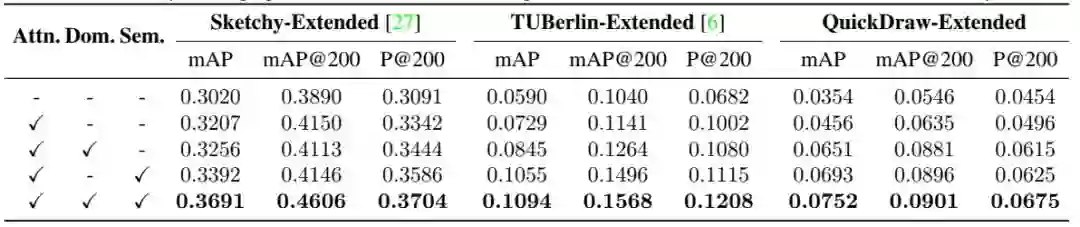
表2. 本文方法的对照试验。三元组损失作为参照,其他不同的损失函数依次加入,以测试其对算法性能的影响。

图2. 给定的索引草图对应的前8个索引结果。所有的示例在训练集中都未出现过(零元学习)。第一行给出了本文方法和CVAE方法的比较。在某些情况下,比如门和窗户的草图,即使对于人类来说,也很难辨别。红色框和绿色框分别代表错误和正确的结果。

Abstract
In this paper, we investigate the problem of zero-shot sketch-based image retrieval (ZS-SBIR), where human sketches are used as queries to conduct retrieval of photos from unseen categories. We importantly advance prior arts by proposing a novel ZS-SBIR scenario that represents a firm step forward in its practical application. The new setting uniquely recognizes two important yet often neglected challenges of practical ZS-SBIR, (i) the large domain gap between amateur sketch and photo, and (ii) the necessity for moving towards large-scale retrieval. We first contribute to the community a novel ZS-SBIR dataset, QuickDrawExtended, that consists of 330, 000 sketches and 204, 000 photos spanning across 110 categories. Highly abstract amateur human sketches are purposefully sourced to maximize the domain gap, instead of ones included in existing datasets that can often be semi-photorealistic. We then formulate a ZS-SBIR framework to jointly model sketches and photos into a common embedding space. A novel strategy to mine the mutual information among domains is specifically engineered to alleviate the domain gap. External semantic knowledge is further embedded to aid semantic transfer. We show that, rather surprisingly, retrieval performance significantly outperforms that of state-of-the-art on existing datasets that can already be achieved using a reduced version of our model. We further demonstrate the superior performance of our full model by comparing with a number of alternatives on the newly proposed dataset. The new dataset, plus all training and testing code of our model, will be publicly released to facilitate future research.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com



