

**论文题目:**Unveiling the Pitfalls of Knowledge Editing for Large Language Models **本文作者:**黎洲波(浙江大学)、张宁豫(浙江大学)、姚云志(浙江大学)、王梦如(浙江大学)、陈曦(腾讯)、陈华钧(浙江大学) **发表会议:**ICLR 2024 **论文链接:**https://arxiv.org/abs/2310.02129 代码链接:https://github.com/zjunlp/PitfallsKnowledgeEditing 欢迎转载,转载请注明出处

一、引言
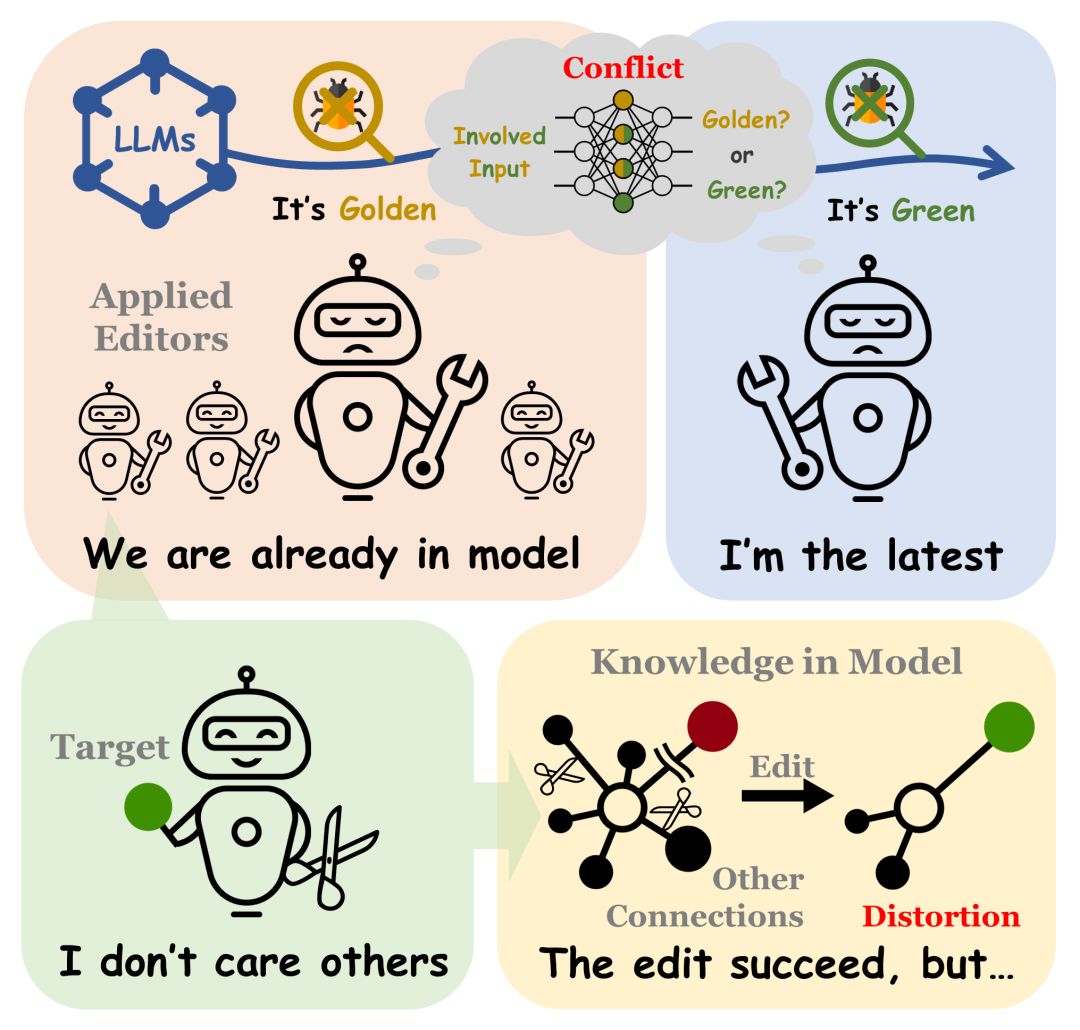
随着大型语言模型的兴起,自然语言处理(NLP)社区面临的主要挑战之一是如何高效地对模型进行微调。如果需要短期内改变模型的某些行为,重新进行参数微调可能会过于耗时和昂贵,在这种情况下,模型知识编辑(Knowledge Editing)技术就显得尤为重要。本文主要研究模型知识编辑的鲁棒性,并重点探索两个新问题:知识冲突(Knowledge Conflict)和知识扭曲(Knowledge Distortion)。
二、背景
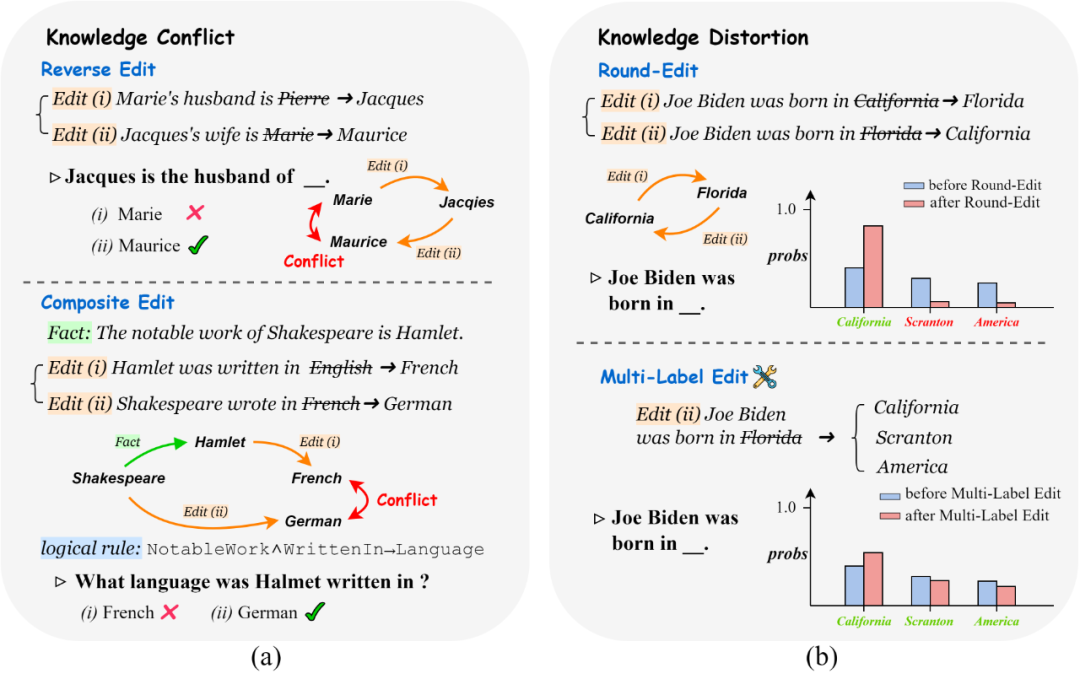
本文研究的知识编辑方法均为修改参数的方法,即通过直接修改模型参数从而改变模型的输出或行为,而无需重新进行完整的训练或微调过程。当同时编辑多个知识点时,编辑之间可能会发生影响。 1)当知识点之间存在某种关系约束时,如果某些旧知识未能成功更新,可能会在模型中引入知识冲突。这种冲突发生在旧知识和新知识之间,表现为模型在处理相关联的知识点时出现的矛盾或不一致。 2)当编辑样本属于一个复杂的知识结构时,知识编辑过程中可能难以保持样本的均衡性,进而导致模型中已有的知识结构遭受破坏。这种现象被称为知识扭曲。
探索和评估这两类问题并构建知识编辑鲁棒性基准尤为重要。首先,这有助于揭示现有知识编辑方法的潜在弱点,从而引导方法在进行知识编辑时关注模型知识的一致性问题。其次,通过这样的探索,可以帮助开发出不会对模型造成潜在危害的鲁棒知识编辑方案。这不仅能够确保在进行知识编辑时,不会对模型的内部原有知识产生潜在的负面影响,还能够提高长期应用知识编辑时模型的可靠性。
三、研究方法
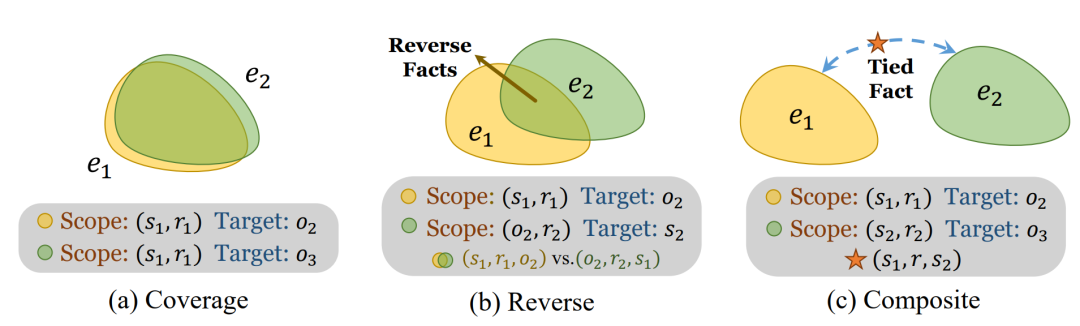
在研究知识编辑时,特别是进行编辑效果评估指标构建时,常使用的一个概念是编辑范围(Editing Scope)。编辑范围是编辑样本在整个输入空间的作用范围,如果我们将知识编辑理解为在某一些与编辑样本相关的输入上改变模型的输出表现,那么我们可以在样本空间做出划分,受到影响的输入称为编辑内输入,未受到影响的称为编辑外输入,这种编辑范围的划分是知识编辑的评估基准,我们使用探测样本来进行指标评估时也会在此范围内外进行采样,根据采样位置的不同,就会产生不同的结果,但在一套评估体系下,采样的方式应该尽量统一。在编辑范围的视角下,我们将三种冲突编辑的编辑对各自的编辑范围用下图来展示,并依据此来构建CONFLICTEDIT数据集。
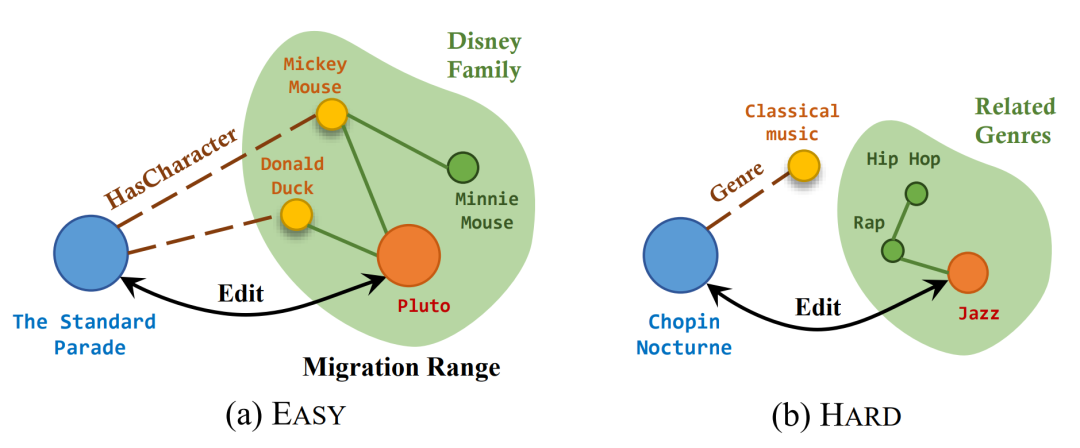
我们设计了一个新的指标冲突得分(Conflict Score,CS),用以衡量知识编辑方法处理知识冲突问题的能力。我们通过计算知识编辑后新知识比旧知识生成概率更高的比率来计算CS,即 其中是通过探测输入得到目标知识k的概率。此外,我们使用两种模式显式(CSexp)和隐式(CSimp)来计算。由于旧知识是导致知识冲突的重要原因,我们设计了指标冲突强度(Conflict Magnitude,CM)来估计k_o的预测概率降低情况: 其中是编辑后的中间模型参数。为了便于分析实验结果和比较评估范式的差异,我们采用成功得分(Succ)作为反映基本编辑性能的指标,即 在组合编辑设置中,关联知识也对构成知识冲突很重要,因此我们将的概率变化视为依赖知识损害(Tied Fact Damage,TFD),计算方式类似于CM计算公式,其中我们用替换。同时,我们为了对比覆盖编辑和单条编辑在结果上的不同,我们增加了单条(Single)实验的结果作为基准。我们发现,ROME在前馈层逆编码矩阵中添加新的键值(Key-Value)映射的方式时,通过优化如下表达式来最大化编辑目标尾实体的生成概率从而得到映射值向量的最优解,关注到的一部分如下: 当作为前馈层在头实体末尾的词元i位置输出时(即时),模型对探测输入在目标尾实体的预测概率达到最大。这种方式相比于直接优化下一个词元生成概率分布交叉熵损失的优点在于,它仅针对头实体隐藏层编解码过程进行优化,我们猜想这个过程产生过拟合的情况会更少。而不产生过拟合问题就意味着下一个词元生成时,与目标尾实体语义相近的词元的生成概率也可能提高,这种现象我们称为迁移(Migration)。根据这种现象,我们将 ROUNDEDIT 数据集划分为简单(EASY)和困难(HARD)模式,如下图所示。
我们定义了三个新的指标来衡量知识编辑方法导致的知识扭曲程度。扭曲程度(Distortion,D)指标估算了在来回编辑前后,正确标签集合上相对预测概率分布的JS散度,即: 其中,是关于Obj的标准化概率分布,该指标衡量了知识扭曲的程度。此外,我们引入了一个更具体的指标,称为忽略率(Ignore Rate,IR)。IR指标量化了在知识编辑过程中中的实体(排除目标实体)在编辑后模型进行预测时被忽视的程度。IR的计算方式如下:, 其中是的生成概率。进一步地,我们设计了失败率(Failure Rate,FR)指标,用于计算其的情况比率,即: 为了参考数据集上的基本性能,我们也计算了与知识冲突中相同的成功分数(Succ),用来计算来回编辑中每条编辑的平均成功率。
四、实验分析
我们在GPT2-XL和GPT-J上进行实验,并在表1中汇总了单条编辑、覆盖编辑、反向编辑和组合编辑几个场景的实验结果。加粗结果表示在每种情况下的最佳表现,而红色结果表明在该设置下完全失败,蓝色结果则标记了知识编辑方法在依赖知识上不可忽视的损害。
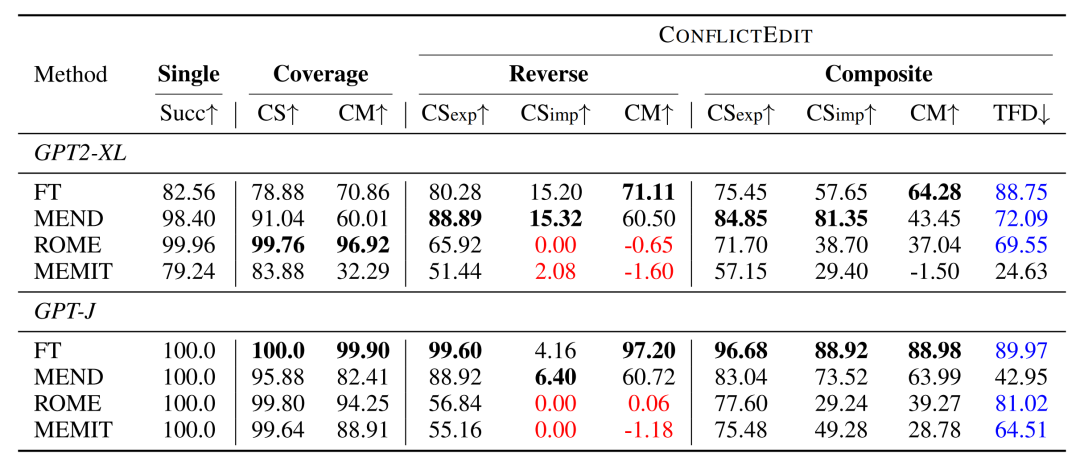
- 覆盖编辑: 在覆盖编辑设置中,知识编辑技术的任务不仅包括注入新知识,还要更新现有信息以确保知识的一致性。得到的CS分数可以揭示在知识编辑方法在应用一对编辑后的可靠性和泛化性能。值得注意的是,结果可能会受到一对编辑中第一个编辑的的影响,这与单条编辑成功分数不同。从经验上看,我们注意到FT在GPT-J中获得较高分数,但在GPT2-XL中分数较低,这是由于其在泛化方面的劣势。ROME在GPT2-XL和GPT-J中都有效,显示了其在编辑知识方面的可比能力。MEND和MEMIT获得较低的分数,特别是在CM指标上,这表明在这种情况下知识编辑失败。
- 反向编辑: FT和MEND使用作为训练输入,并通过梯度下降更新模型参数,这在反向编辑的知识更新方面更有效。因此,FT和MEND在CM上获得更高的分数,这说明通过最新的编辑样本消除了旧知识。ROME和MEMIT以尾实体作为优化目标,将正确的尾实体优化到探测输入,因此以完全不同的方式应用反向编辑。CS分数表明ROME和MEMIT在这种反向编辑中完全失败,这可能是由于它们在反向关系推理方面的表现不佳。在评估CM指标时,MEND和MEMIT保留了模型中的原始知识,对于在语言模型中维持知识一致性构成了重大挑战。
- 组合编辑: 我们观察到,FT和MEND在这种设置中表现出色。相比之下,ROME和MEMIT在编辑过程中表现出色,但编辑后的知识与其他信息脱节。此外,我们注意到大多数以前的知识编辑方法会在TFD分数非常高的情况下对相关知识造成破坏,但这并不是我们想看到的,对于组合编辑设置,知识编辑方法在修改知识的同时,还可能破坏语言模型中已学习知识的关联。

对于知识扭曲,我们在GPT2-XL和GPT-J上进行实验,最终在上表中总结结果。使用FT和MEND编辑后的模型中中观察到显著的知识扭曲,这一点通过它们高IR和FR值得到证实。ROME和MEMIT虽然仍然显示出一定程度的扭曲,但与FT和MEND相比,它们的值更低。这表明ROME和MEMIT已经整合了独特的机制,以在知识编辑期间最小化对大型语言模型隐含知识结构的干扰。此外,我们从EASY和HARD场景中观察到一个有趣的现象:当Succ指标达到高值时,FT和MEND不仅表现不佳,而且在两个数据集中也显示出最小的变化;相比之下,ROME和MEMIT不仅在绝对值上显示出优势,而且在EASY和HARD设置中的IR和FR之间也显示出很大的差距,这说明ROME和MEMIT的编辑方法通过语义关联性有效地实现了范围迁移。同时,我们发现MEMIT在知识扭曲上表现更好,因为它将参数更新分摊到了多个隐藏层,保证了参数改变的幅度,从而具有更好的鲁棒性。
五、总结
我们发现一些较为先进的方法在这些特定场景下容易忽视知识编辑对模型内部知识一致性的破坏问题。这种问题往往是由于这些方法在模型内部知识更新上不够彻底,或者泛化性过强所致。我们的研究结果强调了在知识编辑领域内深入探讨并解决这些问题的重要性。同时,在对现有知识编辑方法进行实验分析后,我们发现尽管知识编辑在处理复杂知识结构方面相比于微调有优势,但它仍然难以避免对语言模型中的知识结构造成潜在破坏。