

**论文题目:**Structure-CLIP: Towards Scene Graph Knowledge to Enhance Multi-modal Structured Representations **本文作者:**黄雨峰(浙江大学)、唐霁霁(网易伏羲)、陈卓(浙江大学)、张荣升(网易)、章鑫峰(网易)、陈伟杰(网易)、赵增(网易)、吕唐杰(网易)、胡志鹏(网易)、张文(浙江大学) 发表会议:AAAI 2024
论文链接:https://arxiv.org/pdf/2305.06152.pdf
代码链接:https://github.com/zjukg/Structure-CLIP 欢迎转载,转载请注明出处

一、引言
视觉语言模型(VLMs)已在多种多模态理解和生成任务中展现了显著的性能表现。然而,尽管这些多模态模型在广泛的任务中表现出色,但是它们能否有效地捕获结构化知识(即理解对象间关系以及对象与其属性间关系的能力)仍然是一个未解决的问题。
如图(a)所示,我们在分析CLIP模型时发现,与图像不匹配的标题(A horse is riding an astronaut)相比,图像与正确匹配的标题(An astronaut is riding a horse)之间的CLIP分数(即语义相似性)表现出较低的数值。图(b)展示了当交换用来修饰两个对象的属性时,模型在准确区分它们的语义上可能遇到挑战。这些发现表明,CLIP模型产生的通用表征能力无法区分那些包含相同单词但在结构化知识方面存在差异的文本段落。换言之,CLIP模型表现出类似于词袋模型的特点,未能有效理解和捕捉句子中的细粒度语义。

针对上述问题,我们提出了Structure-CLIP,旨在通过场景图知识增强多模态结构化表示。与NegCLIP的随机交换方法不同,Structure-CLIP采用了基于场景图的引导策略来进行单词交换,以更精确地捕捉底层语义意图。此外,我们提出了一种知识增强编码器,它利用场景图来提取关键的结构信息,并通过在输入层面上融合结构化知识,从而增强结构化表示的能力。在Visual Genome Relation和Visual Genome Attribution两个数据集上的实验结果展示了我们的Structure-CLIP模型的卓越性能以及其组件的有效性。此外,我们在MSCOCO数据集上进行了跨模态检索评估,结果表明Structure-CLIP仍保留了充分的通用表征能力。 总的来说,我们的贡献点可以总结成以下三点:
- 据我们所知,Structure-CLIP是第一种通过构建语义负样本来增强细粒度结构化表示的方法。
- Structure-CLIP引入了结构化知识增强编码器,利用结构化知识作为输入来增强结构化表征能力,实现从结构化信息到文本信息的有效知识转移。
- 我们进行了全面的实验,证明Structure-CLIP能够在结构化表示的下游任务上实现最先进的性能,并在结构化表示方面取得了显著的改进。
二、问题设定和解决思路
给定一个图像,以及两个图像标题和,其中图像标题与图像内容匹配,而则与图像不匹配。重要的是,这两个文本标题由相同的单词构成,但其单词顺序有所不同。细粒度图文匹配任务的核心目标是在两个高度相似的图像标题中准确识别出与当前图像匹配的标题。具体来说,任务要求模型使得图像与匹配文本的得分高于图像与不匹配文本的得分。 如图所示是我们提出的Structure-CLIP模型的框架图。在该模型中,我们首先利用场景图来生成由相同词汇构成但含有不同细粒度语义的高质量语义负样本,然后通过对比学习的方式来提升细粒度结构化表示的能力(如图左侧所示)。其次,我们设计并实现了一种结构化知识增强的编码器,该编码器以场景图作为输入,并将结构化知识融入到结构化表示中(如图右侧所示),从而实现了结构化信息向文本信息的有效知识迁移。
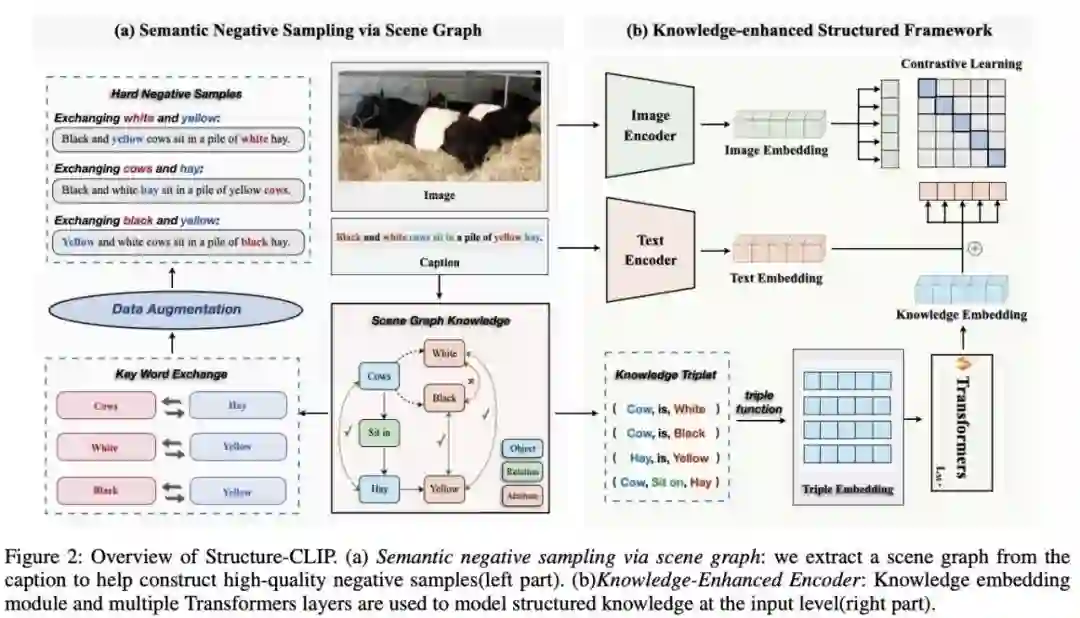
三、方法
3.1 基于场景图的语义负采样对比学习策略
- 场景图生成
在描述视觉场景时,场景图通过更细致地刻画对象间的属性和关系,提供了更精确和全面的语义信息。我们利用场景图解析工具,将文本句子解析成相应的场景图。以标题 Black and white cows sit in a pile of yellow hay 为例,在生成的场景图中,我们可以关注到文本中的关键元素,如 cow 和 hay ;相关属性,如white和yellow,用于描述对象的颜色或其他属性;以及关系,如 sit in ,表示对象之间的空间位置或其他类型的关系。通过这种方式生成的场景图能够将文本信息转换为更详细的对象描述和关系,从而提供更精细的结构化知识表达。这有助于我们更深入地理解句子中表达的结构化知识,可以增强细粒度的视觉-语言联合表示,从而提高模型的整体性能和效果。
- 语义负样本的选择
在本研究中,我们采用了一种基于场景图引导的策略来构建高质量的语义负样本。这一方法与先前随机交换句子中单词位置的方法形成了鲜明对比。我们的语义负样本在保持句子的基本结构不变的同时,改变了句子的细粒度语义。这一策略确保了负样本在语义层面上与正样本存在显著的差异,同时保持了词汇的基本组成。因此,借助这些高质量的语义负样本,我们的模型能够更有效地学习和掌握细粒度的结构化语义表示。 具体来说,对于文本场景图中的三元组,我们通过交换文本中的两个对象主体来生成高质量语义负样本。例如,通过交换文本 An astronaut is ridding a horse 中的对象 astronaut 和 horse,我们可以得到高质量负样本``A horse is ridding an astronaut”。
- 对比学习目标
在本研究中,我们采用的对比学习方法旨在通过靠近图像与其对应原始标题,同时将图像与生成的高质量语义负样本分离,以此来学习高效的多模态表征。为此,我们设计了一个多模态对比学习模块,其损失函数定义如下: 为了确保模型在不同应用场景中均能展现出稳定的通用表征能力,我们采用了一种联合训练策略。该策略结合了传统的小批量图像-文本对比学习损失和新提出的损失函数。具体而言,原始的图像-文本对比学习损失整合了从图像到文本的对比损失以及从文本到图像的对比损失。因此,综合考虑两个方向的损失,图像-文本对比学习的总体损失可表示为: 因此,我们的方法结合了hinge损失与InfoNCE损失,从而实现更全面的优化。具体地,最终的损失函数表达式为: 我们实施的联合训练策略一方面有效地保持了模型的通用性,这一点在跨模态检索任务中表现为显著的性能提升。另一方面,该策略极大地增强了模型在处理结构化表示方面的能力。这种改进不仅有效提高了模型在理解句子中细粒度语义信息的能力,还增强了捕获深层次语义联系的能力,从而在处理复杂文本和图像数据时表现出更高的准确性。
3.2 结构化知识增强框架
编码器采用场景图作为文本输入的辅助信息,旨在通过这种独特的结构化输入来增强模型的结构化表征能力,并实现从结构化表征到文本表征的高效知识迁移。我们设计的知识增强编码器旨在将知识结构化并整合到模型输入中。结构化知识包括对象及其属性和对象间的关系。通过从生成的场景图中提取这些结构化信息,我们能够获取丰富的语义信息,从而有效地捕捉文本的细粒度语义。这一过程涉及了对对象及其属性和对象间关系的明确建模。 首先,我们为两种结构化知识(即属性对和三元组)制定了统一的输入格式,然后通过三元组编码方式来获取三元组向量表示,将 K 个三元组转换为 K 个语义嵌入向量。再然后将三元组语义嵌入向量输入到Transformer层中来获得最终的结构化表征。知识增强编码器能够从提供的所有三元组输入中提取丰富的结构化知识。这种结构化知识对于增强模型的表征能力至关重要,并且对提升模型的整体性能有显著影响。然而,仅仅依靠结构化知识可能在某种程度上限制模型在捕捉通用语义方面的能力。因此,为了实现更全面的语义理解,我们提出了一种将文本嵌入与结构化知识嵌入结合的方法,来得到文本侧的整体表征。通过这种方式,我们的模型不仅能够捕捉到整个句子所蕴含的词汇级信息,还能够综合理解句子中的结构化知识,从而捕获更详细的语义信息。
四、实验
4.1 实验结果
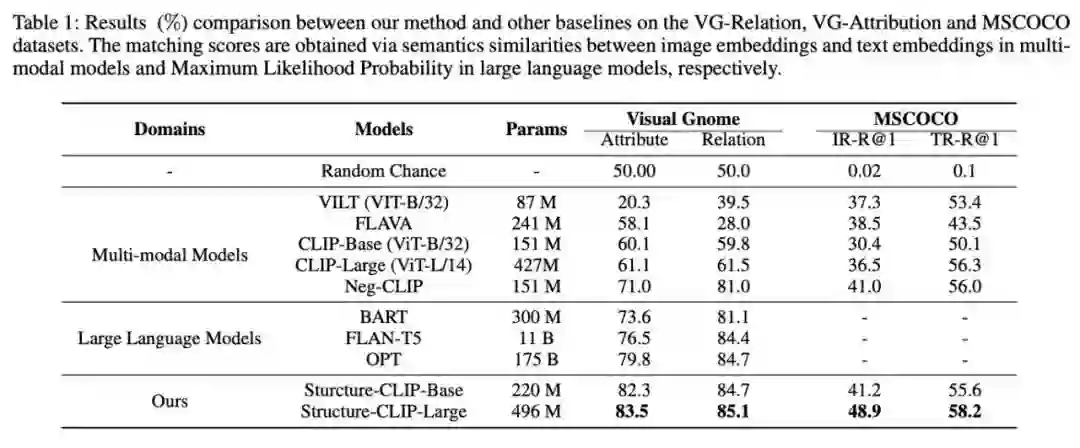
我们将Structure-CLIP与八种代表性的现有方法进行了比较,这包括多种多模态模型以及先进的大型语言模型。在VG-Relation和VG-Attribution数据集上,我们的Structure-CLIP模型展现出了卓越的性能,超越了所有参考的基线模型,实现了最先进的性能表现。这一结果也表明了通过结合场景图知识,我们的模型显著增强了其结构话表示能力。 我们也对Structure-CLIP模型在通用表示任务上的性能进行了详细评估。实验结果表明,在显著增强结构化表示能力的同时,Structure-CLIP模型仍然保持了良好的通用表示能力。
4.2 消融实验
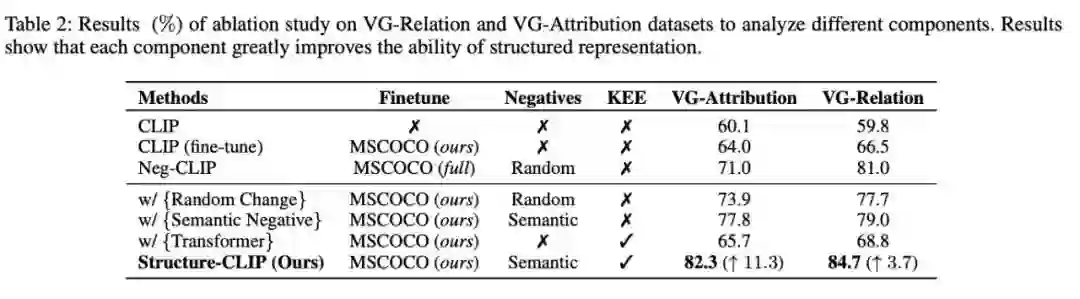
- 成分分析
我们对CLIP-base模型的多个增强版本进行了详细的消融研究。在采用语义负采样策略的情况下,模型性能相比于传统的随机负样本采样策略实现了显著提升。当知识增强编码器与语义负采样策略结合使用时,模型性能实现了显著提升,这表明知识增强编码器在此组合策略下的效果得到了显著加强。
- 超参数分析
我们对Structure-CLIP在不同超参数和嵌入方法下进行了消融实验。
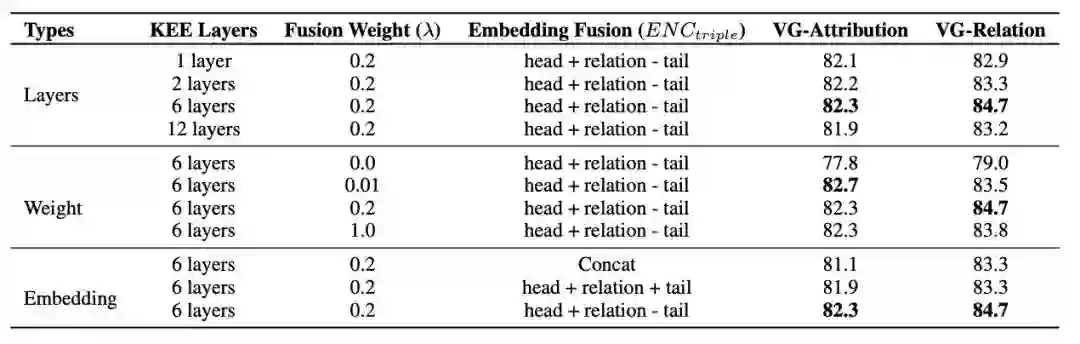
- 三元组编码方式分析
我们探索了三种不同的三元组嵌入方法,以有效整合三元组信息。相比之下,我们提出的三元组嵌入方法既考虑了元素的位置,又综合了它们的组合信息。我们的Structure-CLIP模型在捕捉句子中的细粒度语义信息方面表现出更强的能力,并显著增强了多模态结构化表示的性能。
4.3 Case分析
这些案例清晰地展示了Structure-CLIP在给定图像的情况下成功区分匹配和未匹配的标题,且区分效果非常显著。CLIP模型在确定这些标题与给定图像之间的语义相似性时面临了一定的挑战。特别是在两个属性或对象被交换的情况下,CLIP模型表现出了接近相同的语义相似性判断,揭示了其在捕捉结构化语义方面的局限性。相较于CLIP模型,Structure-CLIP对细粒度语义的微小变化展现了更高的敏感性,这突显了其在结构化知识表征方面的优势。

五、总结
在本文中,我们提出了Structure-CLIP,旨在整合场景图知识来增强多模态结构化表示。首先,我们使用场景图来指导语义否定样例的构建。此外,我们引入了一个知识增强编码器来利用场景图知识作为输入,从而进一步增强了结构化表示。我们提出的Structure-CLIP在预训练任务和下游任务上优于所有最近的方法,这表明Structure-CLIP可以有效地和鲁棒地理解多模态场景中的细粒度语义。****