【泡泡图灵智库】基于RGB-D相机多视图深度学习的一致语义建图
泡泡图灵智库,带你精读机器人顶级会议文章
标题:Multi-View Deep Learning for Consistent Semantic Mapping with RGB-D Cameras
作者:Lingni Ma, Jorg Stuckler, Christian Kerl and Daniel Cremers
来源:IROS 2017
播音员:
编译:凌勇
审核:李阳阳
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——基于RGB-D相机多视图深度学习的一致语义建图,该文章发表于IROS 2017。
视觉场景理解是一个重要的能力,其能使机器人有目的地在环境中行动。在本文中,我们提出了一种新的深度神经网络的方法从RGB-D序列中预测语义分割。关键的创新是训练我们的网络来预测多视图一致语义的自监督方式。在测试时,其语义预测在语义关键帧地图中可以比在单个视图上训练的网络的预测融合更加一致。我们的网络架构基于最近针对RGB的单视点深度学习方法和用于语义对象类分割的深度融合,并且通过多尺度损失最小化loss函数来增强它。我们使用RGB-D SLAM获得相机轨迹,并将RGB-D图像的预测变化到真值注释帧中,以便在训练期间加强多视图一致性。在测试时间,来自多个视图的预测被融合到关键帧中。在训练和测试中,我们提出并分析了几种实现多视图一致性的方法。
主要贡献
1、提出了一个新的使用多视图深度学习方法的语义分割方法, 基于从RGB-D SLAM中获得的相机轨迹, 对具有多视图一致性约束的CNN训练进行正则化。
2、提出并评估了多个在训练过程中增强多视图一致性的变量。
3 、引入了一种共享的原则, 将多个神经网络的输出变换到一个参考帧中. 这样网络不仅学习在视点改变下不变的特征。
算法流程
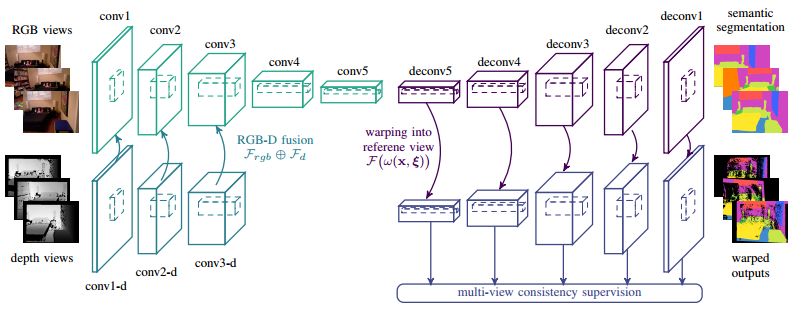
图1 本文中使用的CNN编码-解码器. 输入是带有SLAM估计出轨迹的RGB-D序列. 编码器分别对RGB和Depth图像学习特征, 分辨率最低维数最高的特征图会变换到一个参考帧中添加一致性的约束, 再通过解码器逐步还原到输入的分辨率.
1、面向语义分割的CNN架构
1.1 RGB-D编码-解码器
图1展示了我们CNN的架构, 这个网络遵循这编码-解码的设计. 语义标签集可以定义为 L = {1, 2, ..., K}, 按照惯例, 我们计算在x处分类的得分S = (s1, s2, ..., sk), 网络推断图像中所有像素x为标签j的概率为:
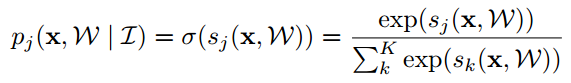
其中W是网络的参数, I是给定的图像.
我们使用交叉熵loss来学习网络参数:
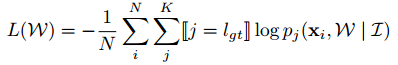
1.2 多尺度深入监督
我们的网络中的编码器部分含有5个2x2的池化层, 将原图像降采样为原来的32分之1, 而解码器部分通过5个存储的反池化接着反卷积层将图像增强为原始分辨率. 为了引导连续的解码器增强, 我们采用了深入监督学习方法, 并且为每个上采样的尺度计算loss.
2、多视图一致性学习和预测
本节将描述将多个连续帧的特征图转换到一个公共参考视图上的多个方法, 以获得结果的一致性. 值得注意的是, 这种方法不仅仅可以在训练中使用, 还可以在预测中使用以融合多个预测结果.
2.1 多视图数据关联
我们训练之前先使用SLAM算法获得相机的姿态, 我们定义每个训练的都带有一个含有语义ground truth的视图Ik。我们引入了多视图几何中的变换的概念, 将不同视图下CNN的输出融合到一个参考视图下. 这个变换曾可以视为一个固定参数的空间变换:
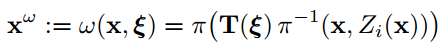
2.2 变换增强
一种实现多视图分割一致性的直接解决方案是将相邻帧的预测变换成具有ground truth注释的关键帧,并在那里计算监督损失。该方法可以被解释为使用可用的附近帧的数据增强的类型。
2.3 贝叶斯融合
记i帧中像素的标签为y并且它的观测是zi, 根据贝叶斯法则有:
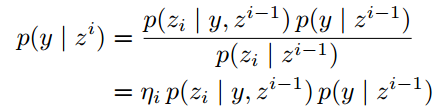
假设观测满足i.i.d条件, 并且后验概率相同, 那么上式等价于:
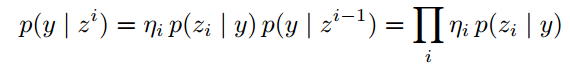
我们使用关键帧像素处标签的对数似然之和而不是使用单独帧的softmax输出作为融合预测的结果.
2.4 多视图最大池化
贝叶斯融合提供了一种在概率空间下的融合输出方法, 我们还开发了一种直接在特征空间里融合的方法. 我们使用一个最大池化层获得最终融合的特征图:
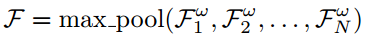
主要结果
我们在NYUDv2数据集上进行了评估. 该数据集含有1449像素化标记的室内RGB-D图像, 并使用了795帧训练, 654帧测试.
1、 单视图分割
我们只使用单独一帧作为预测, 得到了如图2所示的结果.
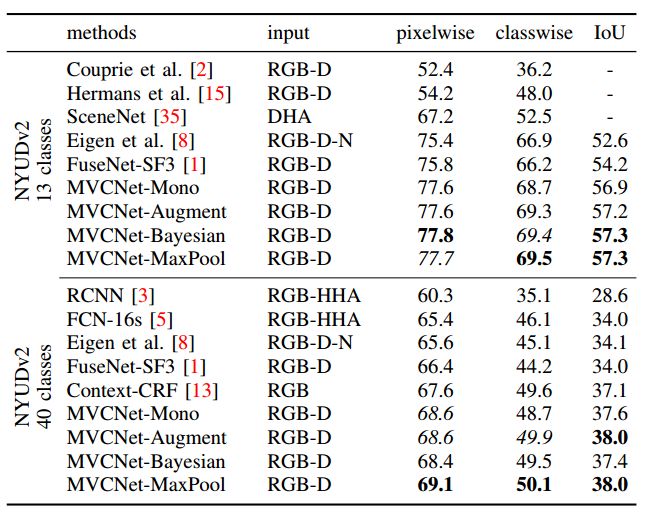
图2 单视图语义分割准确性比较
2、多视图融合分割
如图3所示,使用多视图融合后分割结果明显提升.
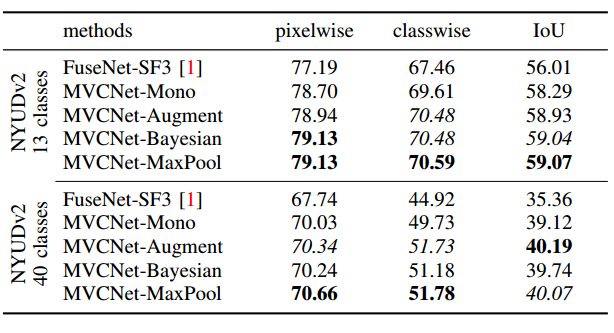
图3 多视图分割结果融合

Abstract
Visual scene understanding is an important capability that enables robots to purposefully act in their environment. In this paper, we propose a novel deep neural network approach to predict semantic segmentation from RGB-D sequences. The key innovation is to train our network to predict multi-view consistent semantics in a self-supervised way. At test time, its semantics predictions can be fused more consistently in semantic keyframe maps than predictions of a network trained on individual views. We base our network architecture on a recent single-view deep learning approach to RGB and depth fusion for semantic object-class segmentation and enhance it with multi-scale loss minimization. We obtain the camera trajectory using RGB-D SLAM and warp the predictions of RGB-D images into ground-truth annotated frames in order to enforce multi-view consistency during training. At test time, predictions from multiple views are fused into keyframes. We propose and analyze several methods for enforcing multi-view consistency during training and testing. We evaluate the benefit of multi-view consistency training and demonstrate that pooling of deep features and fusion over multiple views outperforms single-view baselines on the NYUDv2 benchmark for semantic segmentation. Our end-to-end trained network achieves stateof-the-art performance on the NYUDv2 dataset in single-view segmentation as well as multi-view semantic fusion.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com