NLP 教程:词性标注、依存分析和命名实体识别解析与应用

本文为雷锋字幕组编译的技术博客,原标题 Holy NLP! Understanding Part of Speech Tags, Dependency Parsing, and Named Entity Recognition,作者为 Peter Baumgartner。
翻译 | 陈涛 程思婕 整理 | 凡江
插播一则小广告:NLP领域的C位课程,斯坦福CS224n正在AI慕课学院持续更新中,无限次免费观看!
简介
当我们提到数据科学时,我们经常想到的是针对数字的统计分析。但实际上,更为常见的是由机构所产生的大量非结构化文本数据,它们需要被量化和分析。其中的一些例子有社交网络评论,产品评价,电邮,采访稿。
为了分析文本,数据科学家经常会用到自然语言处理(NLP)。在本文中,我们将详细介绍 3 个常见的 NLP 任务,并研究如何运用它们来分析文本。我们将讨论的三个任务分别是:
词性标注:这个词语的词性是什么?
依存分析:这个词语与句中其他词语有什么关系?
命名实体识别:这个词语是否是专有名词?
我们将通过spaCy这个 python 库,来调用上述三种功能,从而对圣经中的主要角色进行挖掘,并分析他们的行为。接着,我们将尝试对得到的结构化数据做一些有趣的可视化。
当你有大量的文本文档时,你就可以采用这个方法,去了解文档中有哪些主要的实体,它们出现在文档何处,它们做了什么。比如,DocumentCloud 采用了与此类似的方法来实现「查看实体」的分析选项。
词条与词性标注
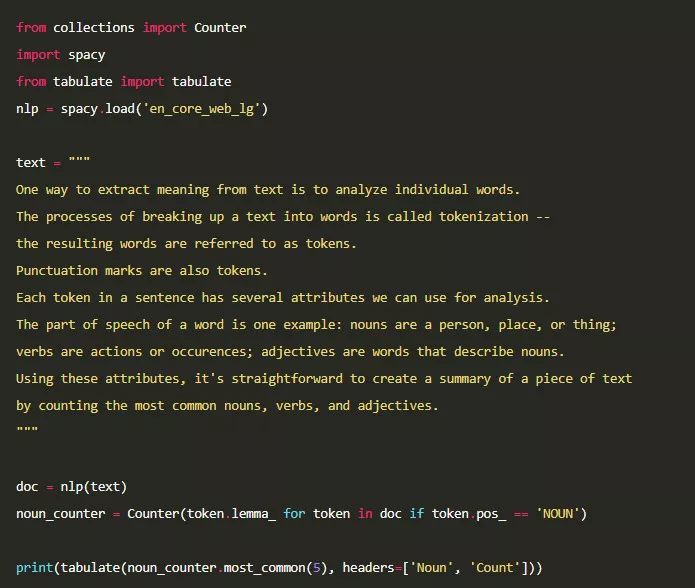
有一种从文本中提取意义的方法是逐一分析每一个词语。将文本切分成词语的过程称为词条化,得到的词语被称为词条。标点符号也是词条的一种。句中的每个词条都有若干属性,我们可以对此进行分析。其中一个例子就是词语的词性:名词表示人物,地点或事物;动词表示动作或事件的发生;形容词则用以描述名词。利用这些属性,可以很方便地统计一段文本内最常见的名词,动词和形容词,从而创建出一份摘要。
利用 spaCy,我们可以对一段文本进行词条化,从而得到每个词条的词性属性。以下面的代码作为示例应用程序,我们对之前的段落进行词条化,并统计其中最常见名词的数目。此外,我们对词条进行了词性还原,即得到每个词的词根,规范了词语的形式。

依存分析
词语之间存在着一定的关系,其中有几种常见的类型。比如,名词可以作为句子中的主语,从而执行一个动作(动词),如同「Jill laughed」。名词也可以作为句子中的宾语,其会受到主语的动作影响,就像此句中的 John:「Jill laughed at John」。
依存分析正是理解句子中词语间关系的一种方法。句子「Jill laughed at John」中有两个名词 Jill 和 John。Jill 是主语,表示发出笑这个动作的人,而 John 是宾语,表示被取笑的人。依存关系是一种更精细的属性,可以用来理解句子中词语间的关系。
词语间的关系可以随着句子的组织方式而变得很复杂。对一个句子进行依存分析,将得到以动词为根的树状数据结构。
让我们来看下这句话的依存分析结果:「The quick brown fox jumps over the lazy dog」。

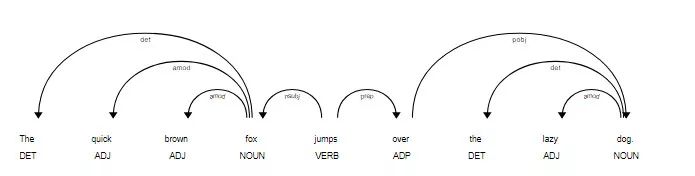
依存关系也是词条属性的一种。spaCy提供了一系列API,可以帮助我们得到词条的各种属性。下面我们将打印出各个词条的文本,词条间的依存关系及其父词条(头词条)的文本。


为了进一步分析,我们需要留意那些带有nsubj关系的词条,这表示它们是句子中的主语。在这个例子中,意味着我们需要将词语「fox」记录下来。
命名实体识别
最后就是命名实体识别了。命名实体是指句子中的专有名词。计算机已经能很好地识别出句子中的命名实体,并区分其实体类型。
spaCy是在文档级层面进行命名实体识别的操作。这是因为一个实体的名称可能跨越多个词条。每一个词条会被标记为实体的一部分,具体实施是按照 IOB 规则 来标记,分为实体的开始,实体的内部以及实体的外部。
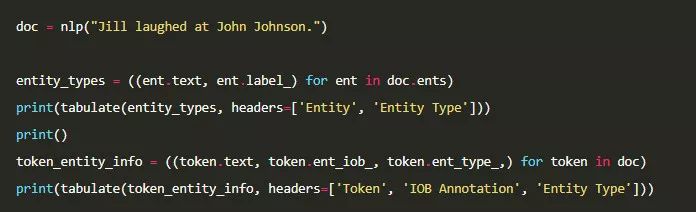
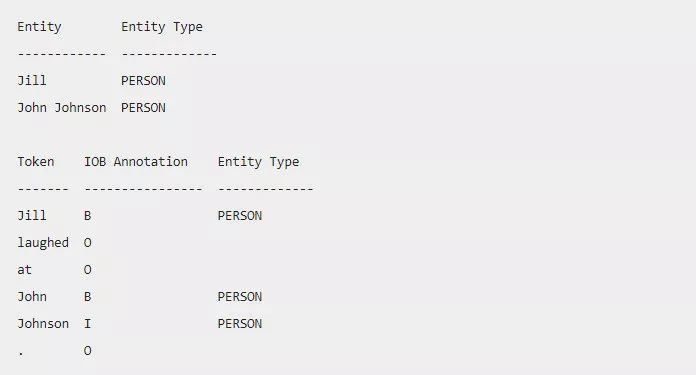
在下面的代码中,我们使用docs.ents函数打印出所有文档级的命名实体。接着,我们打印出每一个词条,它的 IOB 标注及所属的实体类型(如果该词条是某个实体一部分的话)。
我们使用的例句是:「Jill laughed at John Johnson」。
一个实际应用的例子:对圣经进行自然语言处理
分别使用上述提到的方法,效果都挺不错。然而,自然语言处理的真正威力在于我们可以将这些方法结合起来,从而提取出符合语言模式的信息。我们可以使用词性标注,依存分析和命名实体识别去理清大量文本中出现的所有角色及其行为。考虑到圣经的长度及其提到的大量角色,它正是一个应用这些方法的好例子。
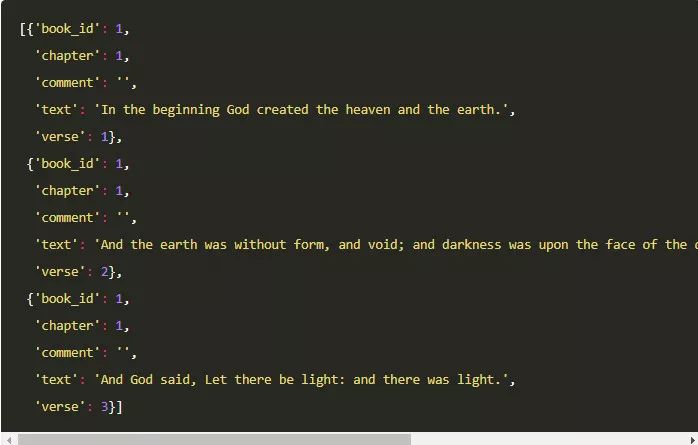
在我们导入的数据中,每一个对象就是一段圣经中的经文。经文是用来索引圣经中的具体章节,一般包括一句或若干句文本。我们会遍历每段经文,提取其中的主语,判断其是否是人名,并抽取出该人物的行为。
首先,我们从 github 仓库中加载 json 格式的圣经。然后,对于抽取出的每段经文文本,利用spaCy对其进行依存分析和词性标注,并将分析后的结果储存起来。
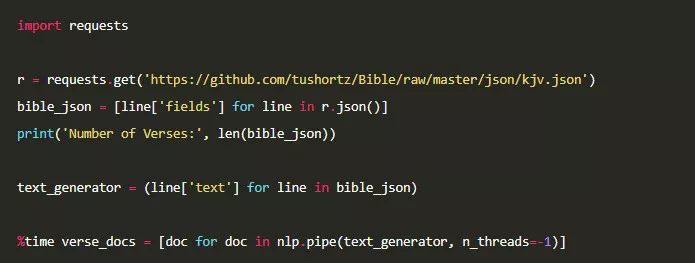

我们将文本从 json 格式中解析出来,并存入verse_docs这个变量里,耗时大约三分多钟,平均一秒钟处理 160 段经文。作为参考,我们可以看一下bible_json的前三行。
使用词条属性
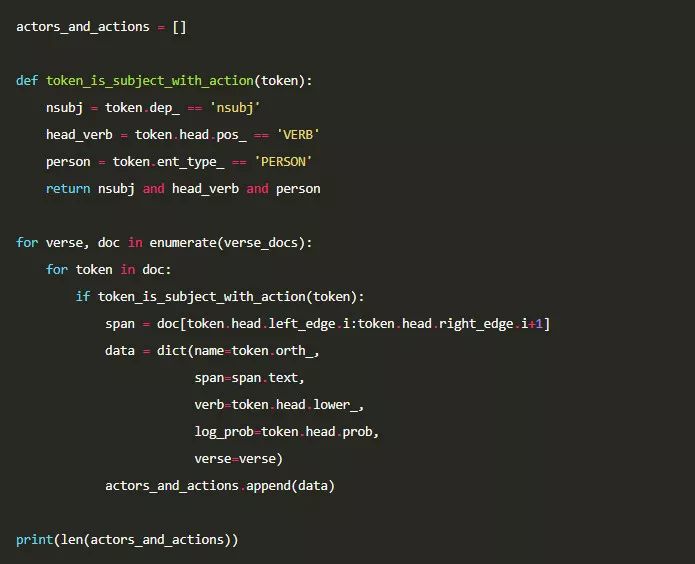
为了提取角色和相关的行为,我们需要对每段经文中的所有词条进行遍历,并考虑 3 个要素。
1)这个词条是否是句子的主语(即查看其依存关系是否是nsubj);
2)这个词条的父词条是否是动词(一般情况下应该是动词,但有时词性标注会和依存分析得出矛盾的结果,我们还是谨慎一点吧。当然我并非语言学家,因此可能此处存在着一些奇怪的极端例子);
3)这个词条是否是指代人的命名实体,我们并不想对非人物的名词进行提取(为了简单起见,我们只提取每个角色的名字部分)。
如果有词条符合上述的三个条件,我们将对其收集下列属性。
1)词条所表示的名词实体的文本;
2)包含名词和动词的文本范围(即短语);
3)其相关的动词;
4)该动词在标准英语文本中出现的对数概率(使用对数概率是因为往往这里的概率值会非常小);
5)该段经文的序号。

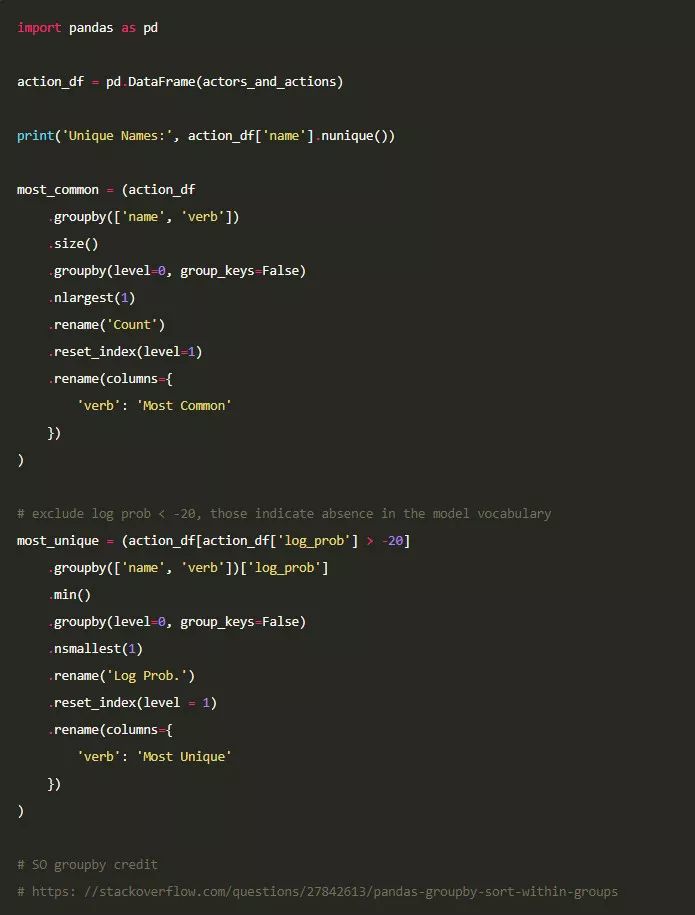
分析
我们已经提取出所有角色和他们的行为,并以列表的形式进行存储。我们先做一个快速分析,计算以下两项。
1)弄清楚每个人物最常见的行为(即动词)。
2)弄清楚每个人物最独特的行为。我们通过查找在英语文本中出现的概率最低的行为,来确定最独特的行为。

让我们看下动词总数量前 15 位的角色及其最常见的动词。

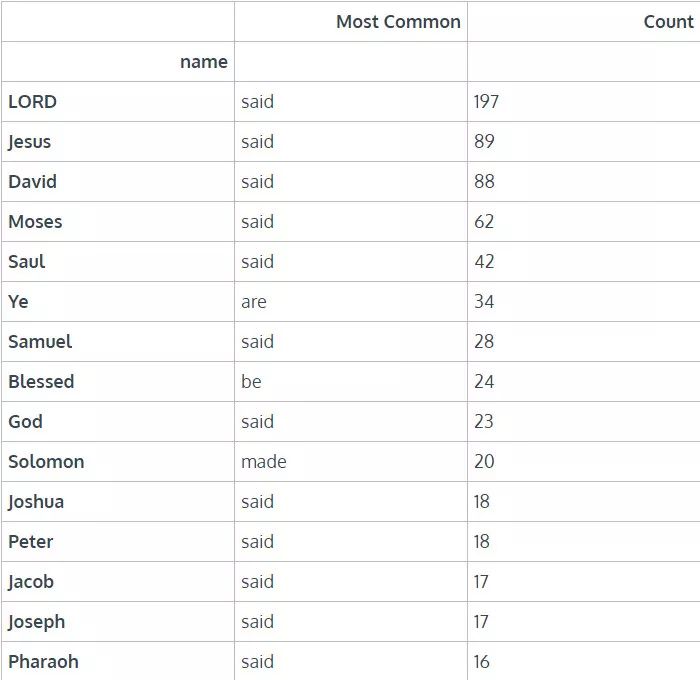
看起来圣经中记录了很多人在说话,除了 Solomon,圣经记录了他做了许多事情。
那么在计算完动词出现的概率后,这些角色最独特的动词又是什么呢。在显示结果中,我们剔除了重复项以保证最终显示的每个词都是唯一的。
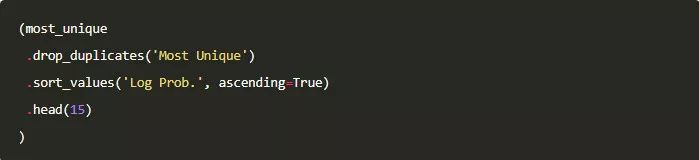
看起来我们得到了一些有趣的新词,可供我们去学习。我最喜欢这两个词:discomfited 和 ravin。
可视化
接下来将结果可视化。我们将使用前 50 位角色的名字及其最常见行为,并画出这些行为出现在整个文本的哪些经文中。在图中,会画出垂直线来表示圣经各卷的开始位置,而名字将以首次出现顺序进行排列。
这样做的目的是了解到这些角色在圣经中的哪个时间点频繁出现。
我们将加入分隔符用以区分圣经中的不同章节。由于我不是一个圣经学者,所以我使用此处的章节划分方法,其主要内容是:
旧约全书
摩西五经或称为律法书: 创世纪,出埃及记,利未记,民数记,申命记。
旧约历史书: 约书亚记,士师记,路得记,撒母耳记上,撒母耳记下,列王纪上,列王纪下,历代志上,历代志下,以斯拉记,尼希米记,以斯帖记。
诗歌智慧书: 约伯记,诗篇,箴言,传道书,雅歌。
先知书: 以赛亚书,耶利米书,耶利米哀歌,以西结书,但以理书,何西阿书,约珥书,阿摩司书,俄巴底亚书,约拿书,弥迦书,那鸿书,哈巴谷书,西番雅书,哈该书,撒加利亚书,玛拉基书。
新约全书
福音书: 马太福音,马可福音,路加福音,约翰福音。
新约历史书: 使徒行传。
使徒书信: 罗马书,哥林多前书,哥林多后书,加拉太书,以佛所书,腓立比书,歌罗西书,帖撒罗尼迦前书,帖撒罗尼迦后书,提摩太前书,提摩太后书,提多书,腓利门书,希伯来书,雅各书,彼得前书,彼得后书,约翰一书,约翰二书,约翰三叔,犹大书。
预言书及启示著作: 启示录。
此外,我们用红色指示线将旧约和新约区分开来。
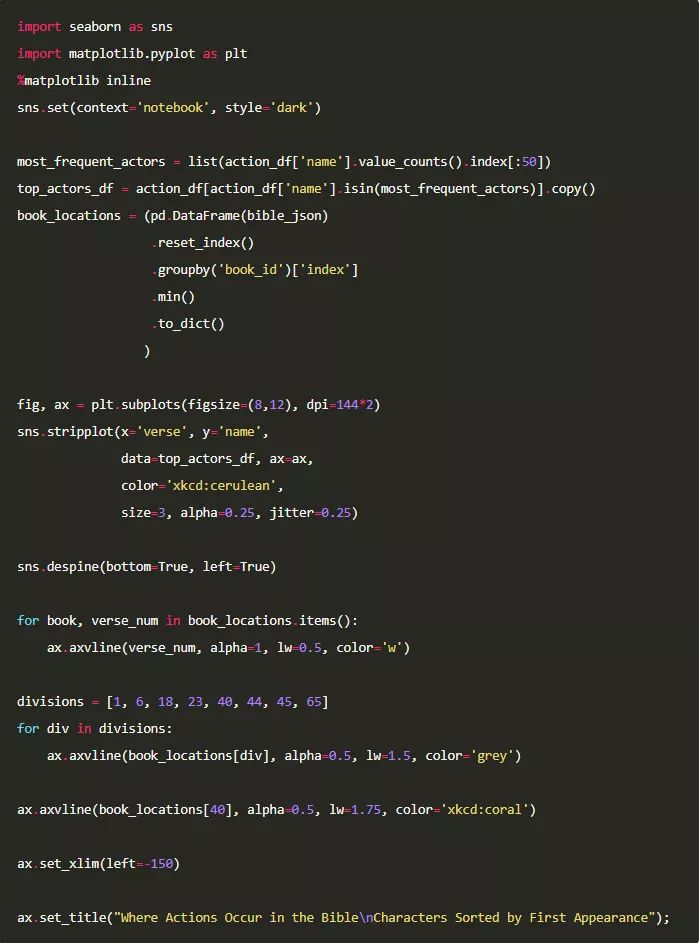
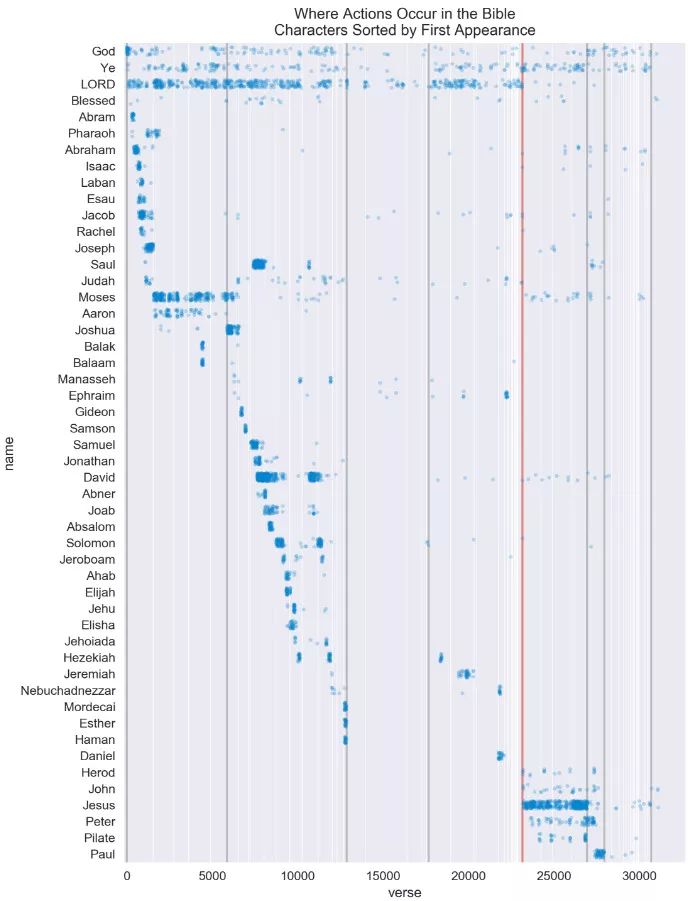
可视化分析
在圣经的开始部分,即创世纪中,上帝被反复提及。
在新约的各卷中,LORD 这个词不再被当做实体使用。
我们可以看到保罗在使徒行传的中间部分被第一次提及。
圣经中的诗歌智慧书部分并没有提到太多的实体词。
福音书详细记载了耶稣的生平。
彼拉多在每一部福音书的末尾都会出现。
此研究方法存在的问题
实体识别无法将两个仅是名字相同的人区分开来。
1. 扫罗王(旧约中人物)
2. 直到使徒行者的中段,使徒保罗一直被称为扫罗。
一些名词并非真实的实体,比如 Ye。
一些名词使用全名的形式可以结合更多上下文信息,比如彼拉多。
下一步
像往常一样,有一些途径可以拓展及提升本文的分析方法。当我在写这篇文章时,我想到以下几点。1)利用依存关系找出实体间的关系,并通过网络分析的方法,去发掘其中的特点。2)在实体获取中,改进实体提取技术,而非目前仅提取名字。3)对非人物实体及其语言关系进行分析,比如圣经中提到了哪些地点。
总结
仅通过使用文本中词条级别的属性,我们就能做出一些有趣的分析了。在本文中,我们讨论了三个重要的 NLP 工具。
词性标注:这个词语的词性是什么?
依存分析:这个词语与句中其他词语有什么关系?
命名实体识别:这个词语是否是专有名词?
我们结合使用了这三种工具,挖掘出圣经中的主要角色以及他们的行为。我们将这些角色和行为可视化,从而了解到每个角色的主要行为在何处发生。
致谢
感谢 Vicki Boykis 和 Austin Rochford 对本文的较早版本提出的建议。
原文链接:https://pmbaumgartner.github.io/blog/holy-nlp/

NLP 灵感研究库
▼▼▼




