理解 YOLO 目标检测

本文为 AI 研习社编译的技术博客,原标题 :
Understanding YOLO
翻译 | 林恩•霍伊尔、吕鑫灿、攒钱买月亮、康奈尔•斯摩
校对 | Lamaric 整理 | 菠萝妹
原文链接:
https://hackernoon.com/understanding-yolo-f5a74bbc7967
注:本文的相关链接请点击文末【阅读原文】进行访问
理解YOLO目标检测
这篇文章从它的角度解释了YOLO目标检测结构。它将不会描述网络的优缺点以及每个网络设计如何选择的原因。相反的,它关注的是网络是如何工作的。在你阅读之前,你应该对神经网络有一个基本的了解,尤其是CNNS。
本文所有的描述都与原始的YOLO文章有关:您只需要看一次:统一地,实时的目标检测( byJoseph Redmon, Santosh Divvala, Ross Girshick and Ali Farhadi (2015).)
从那时起,人们提出了许多改进,结合最新版本YOLOv2的版本,我可能会在下一次撰写。首先理解最初的版本更加容易,然后再去检查改变了什么以及为什么改变。
YOLO是什么
YOLO(你只看一次),是用于物体检测的一个网络。目标检测任务有两个部分组成:确认出明确物体在图片中的位置,以及对这些物体分类 。此前如R-CNN及其衍生的方法,是在多个步骤中使用一个管道来完成对物体的检测。这导致运行速度慢,难以优化,因为每个独立的模块都必须单独训练。而YOLO,会在一个单独的神经网络中完成这所有功能。
我们将物体检测重构为单一的回归问题,从图像像素中,直接获取绑定盒坐标和分类概率。
因此,简单来说,您将图像作为输入,将其传递给看起来类似于普通CNN的神经网络,并在输出中获得边界框和类预测的向量。
那么,这些预测是什么样的呢?
预测向量
理解YOLO的第一步是它如何编码其输出。 输入图像被分成S×S单元格。 对于图像上存在的每个对象,一个网格单元被称为“负责”预测它。 那是物体中心落入的单元格。
每个网格单元预测B边界框以及C类概率。 边界框预测具有5个分量:(x,y,w,h,置信度)。 (x,y)坐标表示相对于网格单元位置的框的中心(请记住,如果框的中心不在网格单元内,则此单元不对其负责)。 这些坐标被归一化为介于0和1之间。(w,h)框尺寸也相对于图像尺寸标准化为[0,1]。 我们来看一个例子:
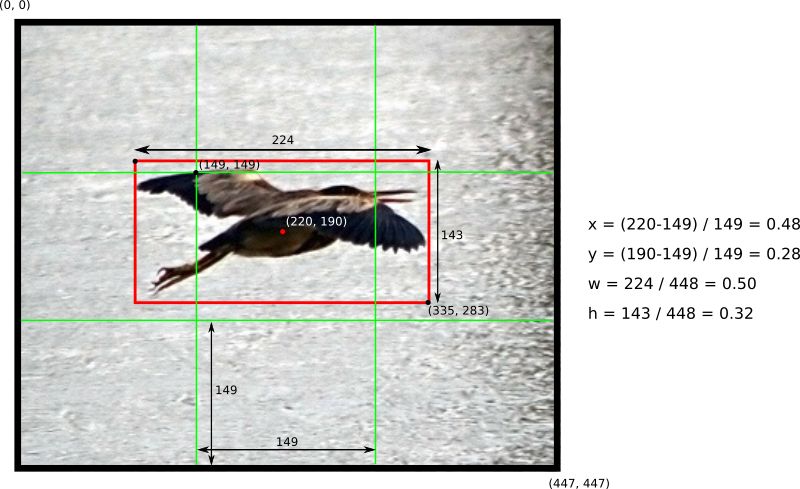
如何计算S = 3的448x448图像中的框坐标的示例。 注意如何相对于中心网格单元计算(x,y)坐标
边界框预测中还有一个部分,即置信度分数。 从下列内容可知:
既然我们已经理解了预测框的五个分量,请记住每个栅格单元会预测B个这种预测框,所以边界预测框相关的输出总共有S x S x B * 5 个。
预测目标所属类别的概率也很重要,Pr(Class(i) | Object)。 这是关于栅格包含目标的条件概率(如果你不知道什么是条件概率,看这里)。实际中,这种概率意味着损失函数不会将不包含目标的栅格计算为错误分类,文章后边我们会看到这一点。网络对于每个栅格将只预测一套类别概率,无关乎预测框数B是多少。共产生S x S x C 个类别概率。
把类别概率加入输出向量,我们得到一个S x S x (B * 5 +C) 的张量作为输出。
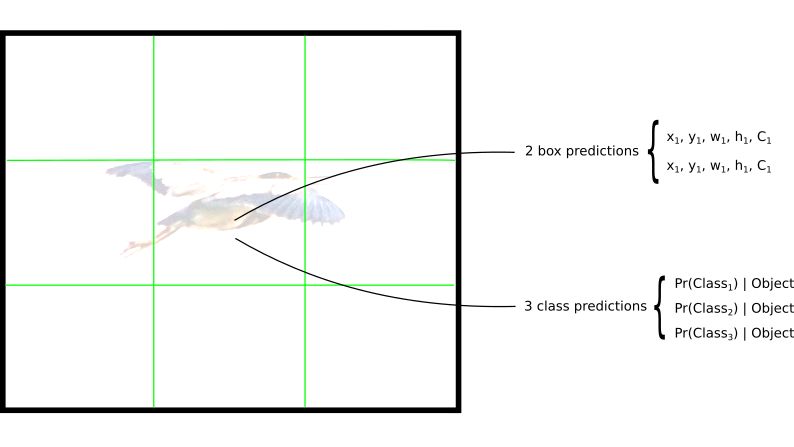
每个栅格预测B个边界预测框和C个类别概率(本例中S=3, B=2 ,C=3 )
网络
一旦了解了预测的编码方式,其余部分就很容易了。 网络结构看起来像普通的CNN,具有卷积和最大池化层,最后是2个完全连接层:
关于架构的一些提示:
请注意,该体系结构是为在Pascal VOC数据集中使用而设计的,其中作者使用S = 7,B = 2和C = 20。 这解释了为什么最终的特征图是7x7,并且还解释了输出的大小(7x7x(2 * 5 + 20))。 使用具有不同网格大小或不同类别数的此网络可能需要调整各层的尺寸。
作者提到有卷积层较少的YOLO的快速版本。 但是,上表显示的是完整版本。
1x1缩减层和3x3卷积层的序列受GoogLeNet(Inception)模型的启发
最后一层使用线性激活函数。 所有其他层使用泄漏的RELU(Φ(x)= x,如果x> 0;否则为0.1x)
如果您不熟悉卷积网络,请看一下这个非常不错的介绍。
损失函数
关于损失函数有很多要讲的,接下来让我们逐步说明。它是从这里开始的:
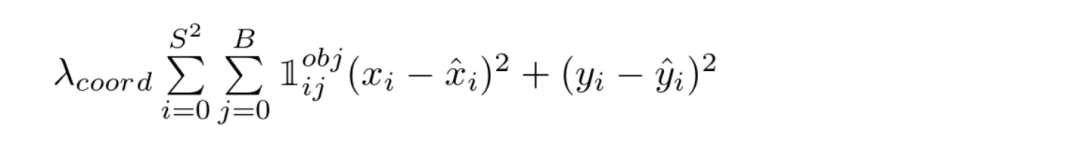
YOLO损失函数——第一部分
该等式计算了相对于预测的边界框位置(x,y)的loss数值。现在不要担心λ,暂且假定λ是一个给定的常数。该函数计算了每一个网格单元(i=0,...,S^2)的每一个边界框预测值(j=0,...,B)的总和。𝟙 obj 定义如下:
1,如果网格单元i中存在目标,则第j个边界框预测值对该预测有效。
0,如果网格单元i中不存在目标
但是我们如何知道那个预测器对该目标负责呢?引用原论文:
对每一个网格单元YOLO预测到对个边界框。在训练时,我们对每一个目标只希望有一个边界框预测器。我们根据哪个预测有最高的实时IOU和基本事实,来确认其对于预测一个目标有效。
等式中的其他项应该是容易理解的:(x,y)是预测边界框的位置,(x̂, ŷ)是从训练数据中得到的实际位置。
接下来我们来到第二部分:
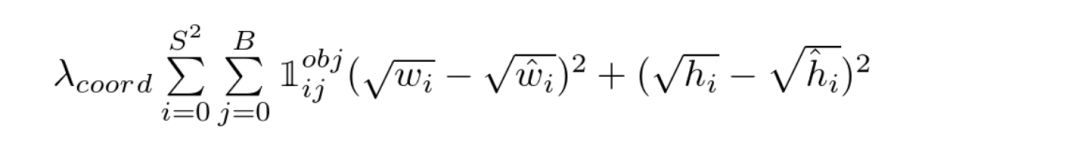
YOLO损失函数——第二部分
这是与预测的边界框的宽度/高度相关的损失。除了平方根之外,该等式看起来与第一个类似。这是怎么回事儿呢?再次引用原论文:
我们的误差度量反应出大箱子的小偏差要小于小箱子。为了逐步解决这个问题,我们预测了边界框的宽度和高度的平方根,而不是直接预测宽度和高度。
接下来是第三部分:
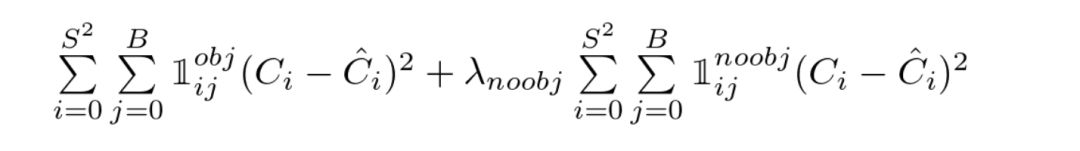
YOLO损失函数——第三部分
此处我们计算了与每个边界框预测值的置信度得分相关的损失。C是置信度得分,Ĉ是预测边界框与基本事实的交叉部分。当在一个单元格中有对象时,𝟙 obj等于1,否则取值为0。
此处以及第一部分中出现的 λ参数用于损失函数的不同加权部分。这对于提高模型的稳定性是十分关键的。最高惩罚是对于坐标预测(λ coord = 5),当没有探测到目标时,有最低的置信度预测惩罚(λ noobj = 0.5)。
损失函数的最后一部分是分类损失:
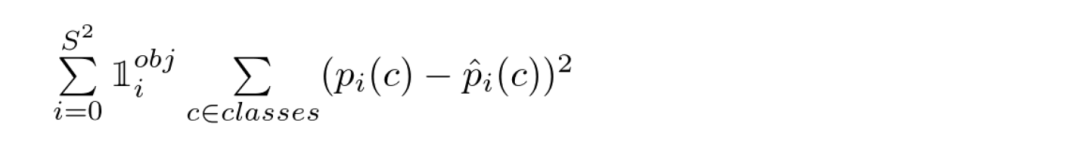
YOLO损失函数——第四部分
除了𝟙 obj 项外,该等式看起来类似于分类的正常求和平方误差。使用该术语是因为当单元格上没有对象时(前面讨论的条件类概率),我们不会惩罚分类误差。
训练
作者将训练过程描述如下
首先,使用 ImageNet 1000级竞争数据集预先训练前20个卷积层,输入尺寸为 224x224
而后,将分辨率增加到 448x448
使用批量大小为64,动量为0.9和衰减度为0.0005的整个网络训练大约135个周期
学习率设置:对于第一个周期,学习率从0.001缓慢上升到0.01,训练大约为75个周期,然后开始减小它
使用伴随着随机缩放和平移的数据增强,并随机调整曝光度和饱和度。
在原论文中更详细地说明了该过程,我想重现该步骤,但我目前还没有做到 :)。
结论
我花了一些时间来获得这篇文章所有细节。如果你正在阅读,我希望通过分享我的评论可以让你的工作更加简单。
我相信测试你是否理解一个算法的最好的方法就是你自己试图从开始去实现它。有很多细节在文章中没有体现出来,只有你自己通过你的双手去构建它的时候才会意识到。
谢谢阅读,如果你有任何评论,请在下面留言。
想要继续查看该篇文章相关链接和参考文献?
复制链接到浏览器打开或点击底部【阅读原文】:
http://ai.yanxishe.com/page/TextTranslation/1168
AI研习社每日更新精彩内容,观看更多精彩内容:
使用 SKIL 和 YOLO 构建产品级目标检测系统
AI课程/书籍/视频讲座/论文精选大列表
如何极大效率地提高你训练模型的速度?
数据科学家应当了解的五个统计基本概念:统计特征、概率分布、降维、过采样/欠采样、贝叶斯统计
等你来译:





