深度学习目标检测算法综述

本文为 AI 研习社编译的技术博客,原标题 :
An overview of deep-learning based object-detection algorithms.
作者 | Thomas Pernet
翻译 | 邓普斯•杰弗、余结、Wintermelly、森鱼、J. X.L. Chan
校对 | 邓普斯•杰弗 审核| 老赵 整理 | 菠萝妹
原文链接:
https://medium.com/@fractaldle/brief-overview-on-object-detection-algorithms-ec516929be93
机器视觉团队@fractal analytics正在致力于解决几个目标检测问题。我们使用了开放源码社区中可用的各种框架,并根据我们的实际用例对它们进行了修改,以便为各种问题语句构建应用程序。我们已经构建了可以基于许多图像数据集(如自然景观图像、交通拥堵图像、卫星图像、零售店图像、过道图像等)上运行的算法。我们还使用了我们的目标检测框架来增强我们的一些视频和图像分类解决方案-我们观察到使用多技术方法,已经带来了更好的结果。
虽然网上有大量可用的资料,但要知道从哪里开始进行目标检测还是相当困难的。这个博客将记录我们在这段探索旅程中学到的很多信息,对于那些想开始学习目标检测的人来说应该是非常有帮助的。
在机器视觉中,目标检测仍然是一个相对未解决的问题,期待在未来几年会有许多的提升。虽然图像分类的准确率在ImageNet挑战中接近2.25%的“前5个错误率”,而且整个社区都宣布实现了“高于人类”的分类准确度,但目标检测算法仍处于早期发展阶段,目前最先进的目标检测算法在COCO数据集上仅实现40.8mAP(mAP值为最高100)。在这些情况下,了解目标检测算法的失败的原因并为特定用例仔细地整理数据集是一种得到最佳结果常遵循的方法。
本博客将讨论深入学习研究社区如何为目标检测问题开发解决方案。我们将讨论有助于提高其时代最先进成果的关键研究论文和技术,并将了解它们如何影响研究人员探索新领域。
我们将讨论以下目标检测的关键算法:
R-CNN
SPP
Fast R-CNN
Faster R-CNN
Feature Pyramid networks
RetinaNet (Focal loss)
Yolo Framework — Yolo1, Yolo2, Yolo3
SSD
目标检测技术的发展
传统的目标检测是使用简单的模板匹配技术来实现的。在这些方法中,目标对象通常是被裁剪的,并且使用诸如hog和sift之类的特定描述器来生成相同的特性。该方法随后在图像上使用了一个滑动窗口,并将每个位置与对象特征向量数据库进行了比较。增强算法使用了分类器,如经过训练的SVM分类器来取代这些数据库的使用。由于物体大小不同,人们使用不同的窗口大小和图像大小(图像金字塔)。这些复杂的管道模式解决了部分目标检测问题,但也存在许多缺点。管道的计算耗时,而使用诸如hog和sift等算法进行手工设计的功能不太准确。
随着在机器视觉中使用深度学习,以及这些算法在2012年针对图像分类挑战取得的惊人结果的出现,研究人员开始寻找深度学习解决方案来解决目标检测问题。R-CNN(与CNN结合的区域候选)是解决深度学习的目标检测的第一个重要算法。
R-CNN
这是第一篇证明CNN可以显著提高目标检测性能的论文。在VOC 2007数据集上获得了58.5 mAP。
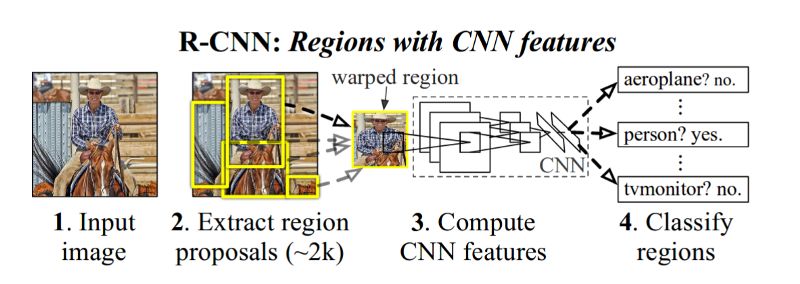
R-CNN框架
为了建立一个R-CNN目标检测管道,可以使用以下方法
1.该方法从一个标准的网络开始,比如在image net上预先训练的vgg或resnet。该网络将充当图像的特征提取器。该方法去除了特定于分类的分类层,并使用bottleneck层从图像中提取特征。在R-CNN中,该方法使用了VGG网络,我们为每个图像候选区域获得一个4096维的向量。

RCNN的目标
2.确保特征提取准确,它们使用这些扭曲的图像训练网络。在训练VOC数据集时,他们将20+1(n_类+背景)层放在末尾并训练网络。每批大小包含32个正窗口数据和96个背景窗口数据。如果一个候选区域的IOU大于等于0.5,且带有标签框的真值框,则该候选区域被认为是正确的。通常从2个图像(批量大小)中获取这128(32+96)个候选。由于每幅图像都会有大约2千个候选,因此我们分别对正图像和负图像(背景)图像进行采样。我们使用选择性搜索生成这些候选。
3.在对网络进行微调后,我们将通过网络发送候选,并获得一个4096维的向量。本文作者在IOU上进行了网格搜索,选取了正样本,IOU为0.3,效果良好。
4.对于每个目标类,训练一个SVM(一个对其他)分类器。您可以使用难分样本挖掘(hard negative mining)提高分类精度。
5.我们还训练了一个边界盒回归器来改进定位误差。一旦特定的SVM分类器对对象进行分类,就可以将其应用于候选上。
算法测试
为了进行测试,R-CNN从输入图像上生成了约2000个独立类别的候选区域,使用CNN(VGG网络)为每个候选区提取一个固定长度的特征向量,然后用特定类别的线性SVM分类器对每个候选区域进行分类。这为每个候选区提供了特定类别的“目标性”分数,然后对这些分数采用非极大值抑制算法。
每张图像的测试时间在GPU上是13秒而在CPU上是53秒。
该方法的主要问题是:
向神经网络发送至多2000个候选区,因此导致GPU上的测试时间高达13秒
用于训练和推理的复杂管道。没有端到端的训练管道。神经网络单独训练,SVM分类器单独训练(这些问题在SPP网络中稍有改善)
SPP网络
R-CNN的主要问题在于将大约2000个候选区单独地传递给网络以分别计算特征向量。同时,当将图像传递给VGG网络时我们需要一个固定尺寸的图像(224*224),为此我们将扭曲或是裁剪图像。而SPP通过使用空间金字塔池化层移除了这一限制。在这部分我们将研究这两个方面。
空间金字塔池化层
这并不是针对目标检测的特定方法,而是通常有助于训练任何神经网络。每个CNN都采用固定大小的图像,因为末端的FC层需要同等大小的输入。我们可以通过下面的例子来理解。
例如,对于一个大小为224的输入图像,卷积层5(最后一层卷积层)具有13*13的特征图,而大小为180的输入图像其卷积层5的特征图大小现在为10*10。如果应用2*2大小的简单池化,那么大小为224与180的输入图像将分别对应7*7和5*5大小的输出。这种转变将对网络进行转换并将在最终给出49*256(256个特征图)和25*256大小的层。附加在FC层的权重矩阵无法发挥作用,因为它需要的是固定的特征向量。因此,我们通过SPP层解决该问题,使用一个单层的金字塔池化层。
假设特征图的大小为a*a而金字塔层大小为n*n。步幅为a/n向下取整的值而窗口大小为a/n向上取整的值。对于一个三层的金字塔,我们将拥有3x3,2x2,1x1大小的bins。下图展示了进一步的计算。
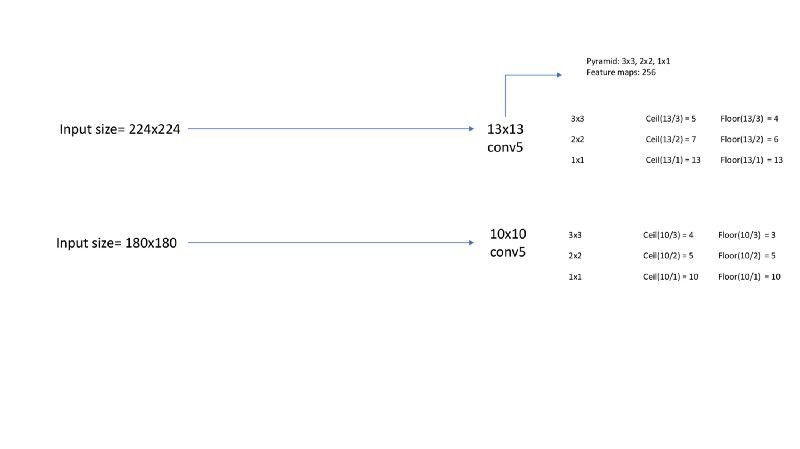
空间金字塔池化
出于计算考虑,他们只在每完成一回合迭代后改变大小。尽管SPP很好,但现在已经过时了,被全局平均池化层所取代。
用于目标检测的SPP网络
由于在测试中特征提取是主要的时间瓶颈,因此作者在SPP网络中将CNN网络应用于整个图像并提取出特征图(卷积层5),对于一个大小为416x416的输入而言(实际上在训练网络时他们使用了5种尺度),其在卷积层5的特征图大小是26*26(子采样率为16)。
接着,我们将通过使用选择性搜索生成大约2000个候选区。在每个候选区里我们需要从特征图中提取出一个固定长度的特征向量。应用方法如下。
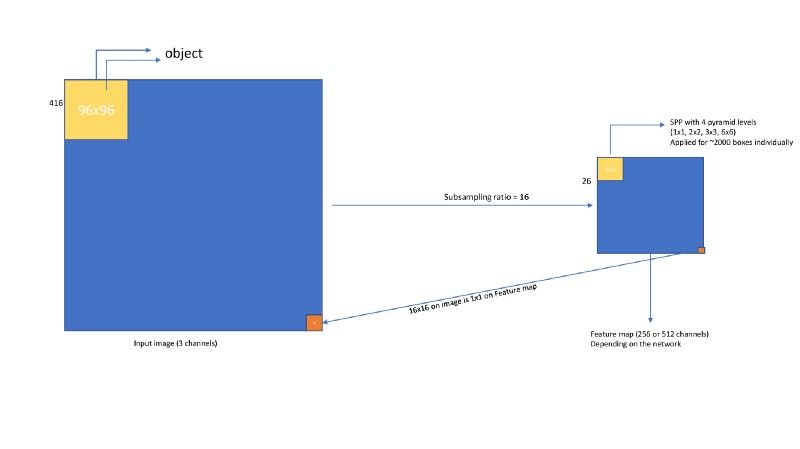
空间金字塔池化网络
现在,在每个候选区都获得了一个固定长度的特征向量后,我们可以利用在R-CNN中使用的相同方法去训练SVM分类器了。
结果
使用结合SPP的ZF网络最终在VOC数据集上达到了59.2%mAP。而使用多层网络时则达到了63.1%mAP。
在单层使用SPP网络需要0.053秒的推理时间,而R-CNN需要14.73秒。使用5层SPP网络时,推理过程需要0.29秒,这仍然快了49倍。
Fast R-CNN
本文提供了突破性的结果,并为后续工作制定了标准。
快速R-CNN与SPP网络的主要差异为
移除了SVM分类器,并为网络增加一个回归分类层。于是该网络成为一个单阶段的训练与推理网络。
移除了SPP池化层并将其与ROI池化层连接。
将VGG网络作为后端,而不用结合ZF网络的SPP网络。
建立了对异常值不太敏感的新损失函数。
Fast R-CNN网络工作方式如下
网络对整个图像进行处理以生成卷积特征图。接着,ROI池化层对每个潜在目标提取固定长度的特征向量,最终将其传递给后续的FC层。
FC层形成两个兄弟输出层的分支,其中一个在K+1个目标类上估计softmax概率,而另一个用于产生优化后的边框位置。
特殊图像的2000个候选区并不会像在R-CNN中那样通过网络传递,相反地,该图像只会传递一次,并且计算后的特征将会在大约2000个候选区中共享,就像在SPP网络中一样。
此外,ROI池化层在每个大小约为h/H X w/W的子窗口中进行最大池化操作。其中,H和W是超参数。这是仅具有一层金字塔的SPP层的特例。
两个兄弟输出层的输出用于计算每个已标记的ROI的多任务损失,以联合训练分类和边框回归。
他们使用了L1损失进行边框损失回归,而在R-CNN与SPP网络中使用的是L2损失,后者对异常值更敏感。

Fast R-CNN网络
RoI池化
又称作感兴趣区域池化,由于它在Faster R-CNN和Mask R-CNN中均被使用,因此理解它很重要。
问题:由于目标大小的不同,池化层被应用于不同大小的特征图上。假设在上图中在图像上位于[64, 64, 192, 192]的目标对应在特征图的位置是[4, 4, 12, 12]。位于[ 128, 128, 384, 400]的目标在特征图上位于[8, 8, 24, 25]。现在两个池化层都应该被用于[4, 4, 12, 12]和[4, 4, 16, 18]并提取出固定长度的特征向量。
此时就是RoI池化层能发挥作用的地方了。下图展示了它的工作方法

RoI池化
损失函数
之前提到,fast R-CNN网络有两个兄弟网络,分类层输出离散概率分数,而回归层输出目标在x,y,w,h上的偏移量。对于分类可以使用交叉熵损失,而对于回归使用的是平滑的L1损失。
训练
当训练fast R-CNN网络时使用大小为2的批量。由于批量大小为2意味着我们拥有至多2000x2=4000个桶,而它们当中大多数不包含目标,因此在训练网络时会出现极端的类别失衡情况。为此,我们从至多4000个桶中随机采集64个正向桶和64个负向桶并只计算这些桶的损失。如果正向桶较少,我们会用负向桶进行填充。总体而言,每次迭代将有128个桶。该方法也用于Faster R-CNN。
编码器
如果一个候选区中任何边框的交并比都大于0.5则称其为前景,我们将相应地为候选区分配类别。而交并比在[0.1, 0.5)的候选区作为负的结果。余下的所有候选区将被忽略。
结果
训练比R-CNN快9倍。而推断时fast R-CNN比R-CNN快213倍。同样地使用VGG16,fast R-CNN比SPP网络在训练时快3倍而在推断时快10倍。
在VOC-2007-12数据集上的平均精度均值(mAP)达到71.8%。在COCO Pascal-style上的平均精度均值(mAP)是35.9.。新的coco-style平均精度均值(mAP),其平均超过交并比阈值,在coco数据集上为19.7%
Faster R-CNN
这个方法取得了难以置信的结果,目前仍然是大多数研究人员的最佳选择。算法在精度和速度上都超越了以前的结果。Faster R-CNN也提出了新技术,这些技术会成为即将推出框架的金标准。让我们来深入研究这些方法。
Fast R-CNN的变化
去除选择搜索,添加一个深度神经网络用于生成proposals(RPN网络)
引入anchor boxes
这是Faster R-CNN带来的两个重要变化。对所有框架,anchor boxes变得十分普遍。对于Fast R-CNN网络,RPN网络能够用作于单个目标检测器或者生成proposals。有一点是确定的,我们已经完全去除了传统的计算机视觉技术,并且制定了从端到端训练的深度神经网络。
RPN如何工作?
将大小为800x800的图像输入到网络中。对于VGG网络,经过降采样率为16的降采样后,输出图像的大小会是[512, 50, 50]。在这个特征图上应用RPN网络,这会得到(50*50*9)boxes回归和分类分数。所以回归输出是50*50*9*4(x,y,w,h),分类输出是50*50*9*2(存在或不存在目标)。在这里,9指的是每个位置上anchor boxes的数量。下面是如何在图像上生成 anchor boxes的过程。(注:稍作修改,这是anchor boxes 应用于所有大多数框架的方式。)
Anchor boxes
在每个位置上,我们有9个anchor boxes,它们具有不同尺寸和方向比率。定义如下
anchors_boxes_per_location = 9
scales = [8, 16, 32]
ratios = [0.5, 1, 2]
ctr_x, ctr_y = 16/2, 16/2 [at (1,1) location)
位于(1,1)的特征图映射到中心位置为(8,8)图像上的[0,0,16,16]box。现在我们需要使用上述的尺寸和比率描绘9个anchor boxes。看下图像上的所有中心

具有anchor中心的图像
这是一位位置点,现在我们需要实现所有的anchor的中心。因为有50*50个anchor中心,每个中心有9个anchor。总共有22500个anchor。
fe_size = 50
anchors = np.zeros((fe_size * fe_size * 9), 4)
index = 0
for c in ctr:
ctr_y, ctr_x = c
for i in range(len(ratios)):
for j in range(len(anchor_scales)):
h = sub_sample * anchor_scales[j] * np.sqrt(ratios[i])
w = sub_sample * anchor_scales[j] * np.sqrt(1./ ratios[i])
anchors[index, 0] = ctr_y - h / 2.
anchors[index, 1] = ctr_x - w / 2.
anchors[index, 2] = ctr_y + h / 2.
anchors[index, 3] = ctr_x + w / 2.
index += 1
print(anchors.shape)
#Out: [22500, 4]
来看一下在图像中(400,400)位置的anchors:

在 (400, 400)中心位置的Anchor
1.因此,RPN生成推荐目标wrt,并将其与得分一起写入每个anchor。如果anchor的最大IOU与金标准对象,或者与金标准对象的IOU大于0.7,则将anchor指定为正。如果一个anchor的IOU小于0.4,则该anchor被指定为负。忽略所有IOU为[0.4,0.7]的anchor。位于图像之外的anchor也将被忽略。
2.同样,由于绝大多数样本都是负性样本,我们将使用相同的快速R-CNN策略来抽取128正样本和128负样本(总共256个),批量为2个进行训练。
3.平滑的L1损失和交叉熵损失可用于回归和分类。回归输出使用以下公式计算anchor位置偏移
t_{x} = (x - x_{a})/w_{a}
t_{y} = (y - y_{a})/h_{a}
t_{w} = log(w/ w_a)
t_{h} = log(h/ h_a)
x,y,w,h是金标准框(标签)的中心坐标、宽度和高度。x_a、y_a、h_a和w_a为anchor的中心坐标、宽度和高度。
4.一旦生成了RPN输出,我们需要在发送到ROI池化层(即快速R-CNN网络)之前对其进行处理。faster R-cnn认为,RPN生成的速度越快,相互之间的重叠程度就越高。为了减少冗余度,我们根据推荐区域的CLS分数对其采用非最大抑制(NMS)。我们将NMS的IOU阈值定为0.7,这样每幅图像留给我们大约2000个推荐区域。经过腐蚀研究,作者表明NMS不会损害最终检测精度,但大大减少了推荐数量。在NMS之后,我们使用排名前N的建议区域进行检测。接下来,我们使用2000个RPN推荐来训练快速R-CNN。在测试过程中,他们只评估了300个推荐,用不同的数字对其进行了测试,并获得了这一结果。
nms_thresh = 0.7
n_train_pre_nms = 12000
n_train_post_nms = 2000
n_test_pre_nms = 6000
n_test_post_nms = 300
min_size = 16
5.生成~2000个建议后,将使用以下公式对其进行转换
x = (w_{a} * ctr_x_{p}) + ctr_x_{a}
y = (h_{a} * ctr_x_{p}) + ctr_x_{a}
h = np.exp(h_{p}) * h_{a}
w = np.exp(w_{p}) * w_{a}
and later convert to y1, x1, y2, x2 format
现在,这2000个推荐类似于快速R-CNN中的选择性搜索生成的推荐。所以剩下的过程类似于Faster R-CNN。
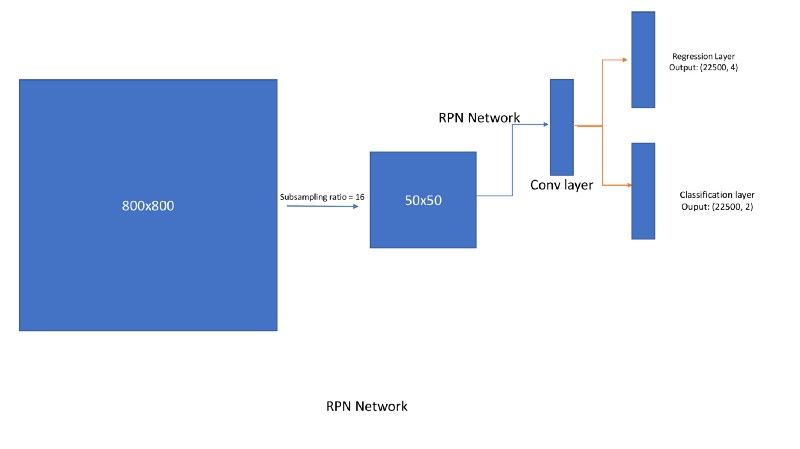
区域生成网络(RPN)
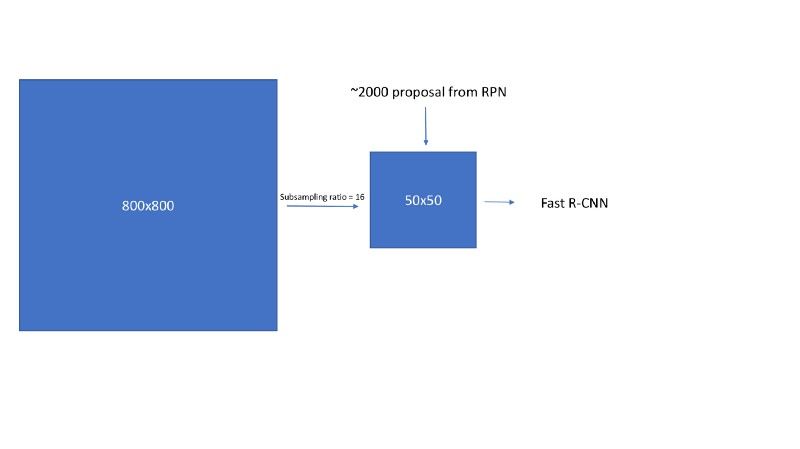
Fast RCNN 在 Faster RCNN中的运行流程
结果
GPU上5 fps的预测
使用VGG后端,在Imagenet和Coco上进行预训练,在VOC上Faster RCNN实现了73.2%mAP。
在COCO数据集上,Faster R-CNN获得21.9mAP(COCO类型)。
特征金字塔网络
研究学者观察到Faster RCNN存在两个不足,首先它无法检测到尺寸小的目标,其次未合理地关注类别不平衡(随机采取256个样本,然后计算损失,这不是一个恰当的方式)。所以,研究学者引入了两个新概念
特征金字塔网络(Feature Pyramid networks, FPN)
焦点损失(Focal Loss对于类别极不平衡的问题)
在这里,我们会简要地讨论这两个概念。
特征金字塔网络
如果你观察Faster RCNN,会发现它几乎无法捕获到图像中尺寸小的目标。在COCO和ILSVRC竞赛中,大多数获奖团队都使用图像金字塔,在很大程度上解决了这一问题。下面给出了一个简单的图像金字塔结构,你可以把缩放到不同尺寸的图像输入到网络中,每个尺寸的图像一旦被检测器检测到,再使用不同的方式结合所有预测到的结果。尽管这种方法有效,但Inference是一个代价高昂的过程,因为需要独立地计算每幅不同尺寸的图像。
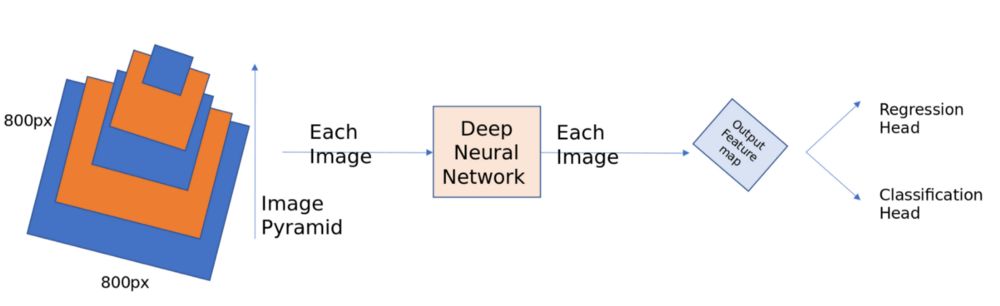
图像金字塔
深层ConvNet逐层地计算一个特征结构,对于降采样层,特征结构具有固定的多尺度,金字塔形状。这种在网络内的特征结构能够生成不同空间分辨率的特征图。首先,我们看下FPN是如何工作的,然后从直觉上看下其效果。
首先采用一个标准的resnet架构(Ex ResNet50)。正如上述讨论的,在Faster RCNN中,我们使用了降采样率为16的特征图来计算区域proposals,然后将RPN的输出结果传递到Fast RCNN中。在这里,以下面的方式完成,
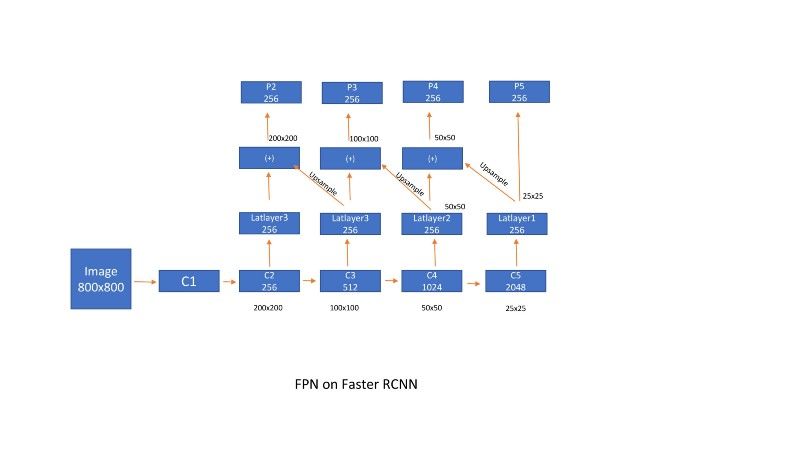
FPN on Faster RCNN
过度降采样将会导致定位性能不佳。如果我们想要使用来自靠前面网络层(比如子样本8)的特征,则无法获得十分清晰的目标语义。所以,我们必须充分利用所有特征。首先基于Faster RNN,设计特征金字塔网络(FPN)。latlayers减少了通道维数(特征图的个数),上采样并加入到前面层的输出中。因为使用双线性插值进行上采样,添加另一个卷积层,用于消除上采样的混叠效应。考虑到计算复杂性,我们忽略了p1(每个特征图p1生成400*400*3 = 480k个proposals)。
在每个特征图上分别设计anchor boxes。因为FPN对图像进行了缩放,我们在每个位置采用3个方向比率为[1:2, 2:1, 1:1]的anchors。在特征图的每个位置上,一共获得了9个anchors。
RPN的FPN
1.在更快的RCNN中,3x3 conv层在特征图上滑动并提取特征,这些特征由两个兄弟网络进一步评估,一个用于回归(1x1 conv),另一个用于分类(1x1 conv)。现在,在实现FPN(feature pyramid networks特征金字塔)的同时,我们构建了相同的网络,但是在这里,我们在每个特征图上移动网络。

Fast R-CNN的FPN
与RPN类似,ROI池化层被附加到每个特征图比例上。子网络分别为每个比例图预测边界框和类别。这个子网络在不同的尺度上共享参数,就像在RPN中一样。
结果:
一些消融研究表明,使用FPN,平均精度(AR^(1K))比单尺度的RPN提高了8.0点。它还将大范围的性能提高了12.9个百分点。
侧向连接将AP提高了10点。
COCO的 AP为33.9,VOC 的AP@5为56.9。在小型物体上,Coco风格的AP从9.6%提高到17.8%。
以resnet-101为后端,VOC AP处于59.1%,COCO风格地图处于36.2%。
当使用resnet101作为后端时,对每个图像的推断需要176毫秒。
RetinaNet(局部损失和FPN结合)
我们所看到的所有目标检测技术都是两阶段的,RPN生成目标推荐,然后在这些预测的目标推荐之上,进行Fast RCNN分类和回归。一个相关的问题是我们能建造单阶段的识别器吗?
第二,在Fast RCNN(FPN)网络中,当评估1⁰⁴到1⁰⁵ 锚箱时,大多数锚箱不包含物体,导致极端的类别不平衡。为了应对类别不平衡,我们从每个小批量(128+ve和128 ve)中抽取256个推荐。然而,这不是一种稳定的方法,本文作者提出了一种称为局部损失的损失函数,试图有效地解决类别不平衡问题。
单级探测器
如下图所示,p3、p4、p5、p6、p7是后端网络的输出。由于计算原因,我们没有使用p1和p2。
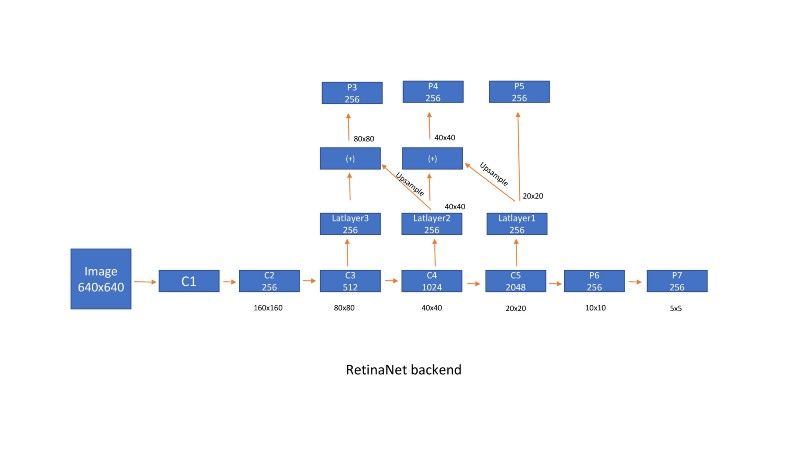
retinanet后端
然后将每个输出传递到一个回归层和一个分类层,该层是一组conv层以及输出层。所有conv层都有256个输入通道和256个输出通道,并应用3x3滑动窗口。RELU位于所有层之间。回归层输出有一个线性层,分类层最终有一个sigmoid(作为输出的类数)或softmax(num classes+1)激活函数。
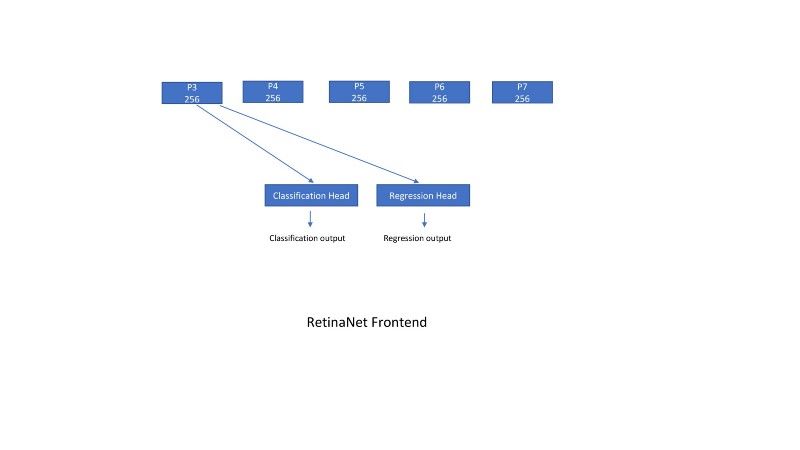
retinanet前端
锚箱的设计方法与FPN章节中所述的方法相同,并做了一些修改。步幅分别为[p3,p4,p5,p6,p7]的[8,16,32,64,128]。虽然FPN处理尺度,但是本文在每个特征图上使用不同尺度的锚框来获得更好的结果。因此,我们在特征图的每个位置都有9个锚,在所有尺度上总共有45个锚。他们使用的锚箱尺寸为[2⁰,2^(1/3),2^(2/3)],长宽比为[0.5,1,2]。sudo代码如下:
aspect_ratios = [0.5, 1, 2]
kmin, kmax = 3, 7 #feature scales
scales_per_fe = 3
anchor_scale = 4
num_aspect_ratios = len(aspect_ratios)
num=0
for lvl in range(k_min, k_max+1):
stride = 2. ** lvl
for fe in range(scales_per_fe):
fe_scale = 2**(fe/float(scales_per_fe))
for idx in range(num_aspect_ratios):
anchor_sizes = (stride* fe_scale * anchor_scale,)
anchor_aspect_ratios=(aspect_ratios[idx],)
num+1=1
print(anchor_sizes, anchor_aspect_ratios)
#out
1 (32.0,) (0.5,)
2 (32.0,) (1,)
3 (32.0,) (2,)
4 (40.317,) (0.5,)
5 (40.317,) (1,)
6 (40.317,) (2,)
---
43 (812.75,) (0.5,)
44 (812.75,) (1,)
45 (812.75,) (2,)
编码类似于faster-RCNN,如果锚箱与标签框的IOU大于0.5,则为+ve,<0.4,则为-ve,其余均忽略。每个锚最多分配一个锚。
对于640x640的输入大小,我们得到8525((80*80)+(40*40)+(20*20)+(10*10)+(5*5))位置。由于每个位置有9个锚,我们总共获得76725(8525x9)个锚。
损失函数
回归使用平滑的L1损失,其对异常值不太敏感。这是迄今为止所有框架中一直延续使用的相同损失。

L1平滑损失
分类损失称为焦点损失,它是交叉熵损失的一种变形形式,本文对此进行了大量的讨论。
焦点损失是交叉熵损失的重塑,使其向下加权分配给分类良好的例子的损失。这种新颖的焦点损失集中训练在一组稀疏的困难例子上,并防止训练期间大量简易的负类样本压倒识别器。
让我们看看这种焦点损失是如何设计的。我们将首先研究单目标分类的二进制交叉熵损失。
交叉熵损失:
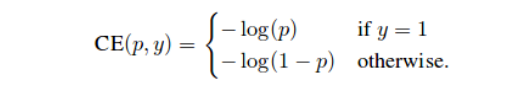
焦点损失:
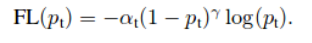
此处的P_{t}取值为,如果y=1,则为p,否则为1-p。让清洗的理解这个损失函数等式。这里的α叫做平衡参数和γ叫聚焦参数。
平衡参数通常是特定类实例数的倒数。它为具有更多样本的类提供了较少的权重。
聚焦参数的不轻adds两阱分类实例和更多的轻硬/小姐分类实例。让我们检查技术是实现使用4的情景。有explained。这在我的博客和其他的学院完备的缘故
聚焦参数增加了分类良好的示例的权重,增加了困难/遗漏的分类示例的权重。让我们用4个场景来检查这是如何实现的。为了完整起见,我已经在我的另一个博客中对此进行了解释。
场景1:容易正确分类的示例
假设我们有一个容易分类的前景目标,p=0.9。对于这个例子,通常的交叉熵损失是
CE(前景)=-log(0.9)=0.1053
现在,考虑一下p=0.1的容易分类的背景目标。对于这个例子,通常的交叉熵损失也是一样的。
CE(背景)=-log(1–0.1)=0.1053
现在,考虑上述两种情况的焦点损失。我们将使用alpha=0.25和gamma=2
FL(前景)=-1 x 0.25 x(1–0.9)**2log(0.9)=0.00026
FL(背景)=-1 x 0.25 x(1–(1–0.1))**2log(1–0.1)=0.00026。
场景2:错误分类示例
假设我们有一个错误分类的前景目标,p=0.1。对于这个例子,通常的交叉熵损失是
CE(前景)=-log(0.1)=2.3025
现在,考虑P=0.9的错误分类背景目标。对于这个例子,通常的交叉熵损失也是一样的。
CE(背景)=-log(1–0.9)=2.3025
现在,考虑上述两种情况的焦点损失。我们将使用alpha=0.25和gamma=2
FL(前景)=-1 x 0.25 x(1–0.1)**2log(0.1)=0.4667
FL(背景)=-1 x 0.25 x(1–(1–0.9))**2log(1–0.9)=0.4667
场景3:非常容易分类的示例
假设我们有一个容易分类的前景对象,p=0.99。对于这个例子,通常的交叉熵损失是
CE(前景)=-log(0.99)=0.01
现在,考虑一下p=0.01的容易分类的背景对象。对于这个例子,通常的交叉熵损失也是一样的。
CE(背景)=-log(1–0.01)=0.1053
现在,考虑上述两种情况的焦点损失。我们将使用alpha=0.25和gamma=2
FL(前景)=-1 x 0.25 x(1–0.99)**2log(0.99)=2.5*10^(-7)
FL(背景)=-1 x 0.25 x(1–(1–0.01))**2log(1–0.01)=2.5*10^(-7)
结论:
场景1: 0.1/0.00026=384倍 较小的数字
场景2: 2.3/0.4667=小5倍
场景3: 0.01/0.00000025=40000倍较小的数字。
这三种情况清楚地表明,焦点损失对分类良好的示例增加的权重非常小,而对分类或难分类的示例则增加了较大的权重。
RetinaNet的推论
这是设计焦距损失背后的基本直觉。作者测试了α和γ的不同值,并确定了上述的最终值。
在阈值检测器置信度为0.05后,从每个特征尺度中获得了1000个推荐。合并所有级别的顶部预测,并应用阈值为0.5的非最大抑制,以产生最终检测。
注意:使用随机权重初始化网络时请小心。作者建议使用
(-1)x math.log((1–0.01)/0.01)
作为最后一层偏差。如果不这样做,我们会在第一次迭代中得到一个巨大的损失值,并且梯度溢出,这最终会导致NANs。
结果
在COCO数据集上,Retinanet实现了40.8mAP的coco类型图和61.1的VOC样图。小物体上的coco样式ap为24.1,中等物体为44.2,大物体为51.2。
使用600x600的输入大小和resnet101作为后端,推断每个图像需要122ms。
YOLO
YOLO是一个重要的目标检测框架,它有着较高的准确率和检测速度。Yolo的提出者经过长期研究,到目前位置已经发表了3篇论文。尽管yolo的大部分思想和上述检测框架相似,但是yolo还是在性能上有巨大提升,尤其是在检测时间上有较大的提高。
yolo到目前为止,一共有3篇论文,分别是yolo1,yolo2,yolo3,这几篇论文展示了yolo在准确率方面的提升。
yolo是个人研究者发表的,而且据我所知是第一篇讨论单级检测的论文,RetinaNet也借鉴了Yolo和SSD在这方面的思想。
网格胞元:
如下图所示,我们把图片划分成以下网格单元。大小是7*7. 在每个网格单元中有对象中心的ground truth对象就是+ve单元 ,即在下面的类概率图中,显示了每个网格单元的颜色,可以看到狗、自行车、汽车的部分有对应不同的颜色,最后的预测是结合类概率图和bbox与置信度等信息做出的。
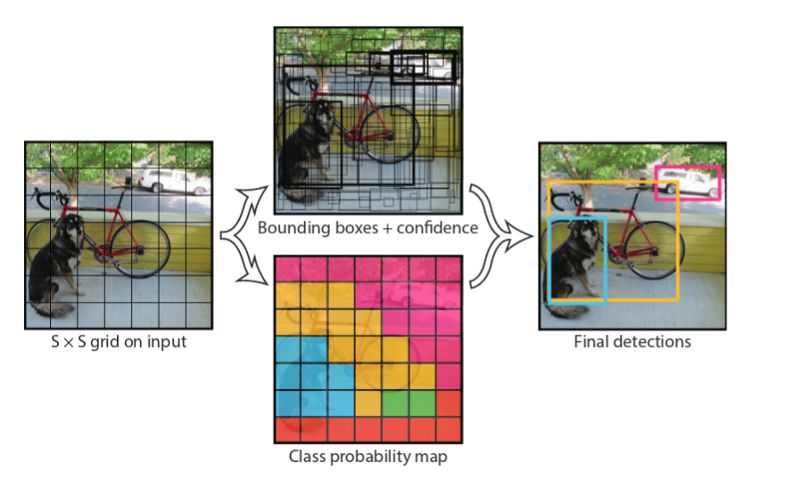
每个网格单元预测两个bounding box,并且每个bbox由五个指标组成,五个指标分别是x,y,w,h和confidence。其中 bbox 的(x,y)坐标代表的中心是相对网格单元。w,h分别代表bbox的宽度和高度。这里面的的宽度和高度是相对于整个图片的宽度和高度而言的。最终,所预测的置信度是由预测框和任意实际框的iou值。因此对于有着20个类别的VOC数据集来说,每个网格单元的输出将会是((4+1)*2+20)=30.如果网格大小是7*7的话,我们将得到7*7*30大小的的输出
def normal_to_yolo_format(bbox, anchor, img_size, grid_size):
y, x, h, w = bbox #bounding box参数
y1, x1, y2, x2 = anchor # supporting cell
size_h = img_size[0]/ grid_size[0] # 每个网格单元的高
size_w = img_size[1]/grid_size[1] # 每个网格单元的宽
new_x = (x - x1)/size_w # 网格单元内中心的x坐标
new_y = (y - y1)/size_h #网格单元内中心的y坐标
new_h = h/img_size[0] # 使用图片高度归一化后的目标高度
new_w = w/img_size[1] # 使用图片高度归一化后的目标宽度
return [new_y, new_x, new_h, new_w
对bbox编码:
对每个网格单元,
For each ground_truth_bbox:
检查网格单元是否含有bbox,
如果有:
分别用不同的bbox值,标签值和代表是否存在目标的二进制编码[在本例中是1】给box赋值,
编码存在的问题
如果每个网格单元包含两个目标中心将会出现什么情况?可以随机选择一个目标,或者增大网格的尺寸例如增大到16*16.这部分的问题在yolov2的时候得到了较好的解决,我们将在下部分讨论。
网络
Yolo使用了另一种称为DarkNet的网络,这是作者自己开发的,与其他采用标准的、性能良好的ImageNet架构的框架不同

Yolo网络
损失函数
Yolo包含了三个损失函数:
1. 协调误差
2. 客体性的分数
3. 分类误差Yolo损失函数
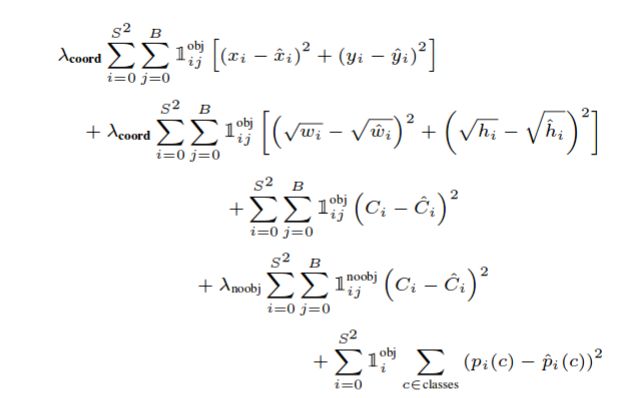
客体性分数用1^obj表示,只有当客体性分数>0.5时,协调误差和分类误差才会进行评估。损失是为每个网格单元单独计算的,稍后将对所有网格进行求和。w和h有平方根来解决下面的问题
预测错误的小对象应该比预测错误的大对象得到更多的权重
\lambda_coord和\lambda_noobj分别为5和0.5。
根据我的经验,为我自己的数据集正确地获得这个损失函数成了一场噩梦。这些损失函数可能被调优为适用于此数据集,也可能适用于分布类似的数据集。在处理其他数据集时,它可能会严重失败。我将在另一篇博文中讨论从头构建对象检测管道时所面临的问题。
训练
首先在Imagenet上对DarkNet进行预处理以进行分类。排名前5的准确率为88%。由于检测需要细粒度的信息,他们使用了448x448图像而不是224x224。他们发现,在最初的几个epoch里,误差很大,并认为这可能是由于图像大小的变化。因此,对于最初的几个epoch,他们再次使用448x448在imagenet上对网络进行了训练,后来又转向voc数据集。
该网络随后在vocs -2007和2012数据集上进行了135个时代的训练。在整个训练过程中,他们使用了64个batch_size, 0.9的动量和0.0005的衰减。学习速率的时间表如下,第一时期他们慢慢地从10 ^-3到10 ^-2提高了学习速率。用10 ^-2持续训练75个epoch,然后用10 ^-3 训练30个epoch,最后用10 ^ -4训练30个epoch。
为了避免过拟合,他们使用了drop和广泛的数据扩充。在本例中,我们还使用了批处理规范化。
为了增加数据,他们使用了随机缩放和平移高达20%的原始图像大小。他们还在HSV颜色空间中随机调整图像的曝光和饱和度,最高可达1.5倍。
结果
YOLO非常快。它以每秒45帧的速度运行
Yolo使用DarkNet以每秒45帧的速度获得63.4帧的mAP。与使用vgg-16(73.2)的faster r-cnn相比,mAP要少得多; 但faster r-cnn的速度是每秒7帧。fast R-CNN框架以0.5fps(每秒帧数)的速度实现了71.8%的FPS。
由于每个网格单元只预测两个框,并且只能有一个类,因此Yolo对边界框预测施加了强大的空间约束。这个空间约束限制了模型可以预测的附近目标的数量。例如,YOLO很难预测一群动物(鸟类)。
由于该模型根据数据预测边界框,因此很难将其归纳为具有新的或不常见的纵横比和配置的对象。
当YOLO观察整个图像以预测单个细胞上的目标时,它更擅长于减少定位误差。因此,Yolo捕捉并考虑了整个图像的全局特征,以预测单个细胞,这与faster R-CNN不同。一项关于这些错误的调查发现,与Yolo相比,Fast R-CNN几乎产生3倍的背景错误。所以对于fast R-CNN预测的每一个边界框,它都会被Yolo重新评估。这将快速R-CNN的mAP提高了3.2%到75%。
YOLVO2
我们将在本文中重点介绍他们对Yolo所做的修改。
在67 fps时,yolov2在VOC 2007上得到76.8mAP。在40fps时,yolov2获得了78.6mAP,比最先进的方法更好,比如faster-r-cnn和resnet和ssd,同时运行速度也明显更快。
Yolo在每个网格单元使用锚框。这将允许我们对同一网格单元中的多个框进行编码。
锚框边界框的尺度和纵横比根据数据集设置。(我将写一篇单独的关于此的文章,因为它也可以在所有其他框架中使用)。设定更好的先验和理解数据集是最重要的,首次讨论是在Yolov2的论文中。
网格大小从7x7增加到13x13。这也应该来自数据集。如果您有非常小的物体,我们可以根据需要将其增加到32x32或50x50。在考虑网格大小时,我们需要做的一个预先检查是,任何锚箱都不应超过一个标签框的大小。
对网络进行了批量规范化。与网络中的网络类似,它们使用全局平均池化和1x1卷积。
x,y,w,h的编码方式如下所示。这也是YOLOv3中使用的相同方程式。这样做是因为直接预测图像上的目标位置会导致模型不稳定,而且它们也不受约束。
多尺度训练。为不限制输入图像的大小,我们每隔几次迭代就更改一次网络工作。每10批我们的网络随机选择一个新的图像尺寸大小。由于我们的模型下采样率为32,我们从以下32的倍数中提取:320,352,…,608。因此最小的选择是320×320,最大的选择是608×608。我们将网络调整到那个维度,然后继续训练。
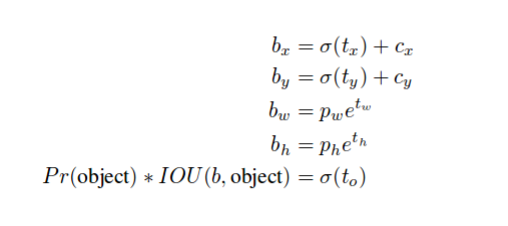
YOLOV3
Yolov3论文是一个有趣的阅读,我们将在这里重点介绍最重要的事情。
Yolov3达到33.4 IOU@0.5:0.95mAP和57.9 IOU@0.5mAP。作者深入探讨了为什么我们转换了度量标准并支持iou@0.5(voc风格)。使用VOC mAP,yolov3非常文档鲁棒
yolov3用darknet53替换darknet19并引入残差块。它还介绍了FPN。网络如下所示
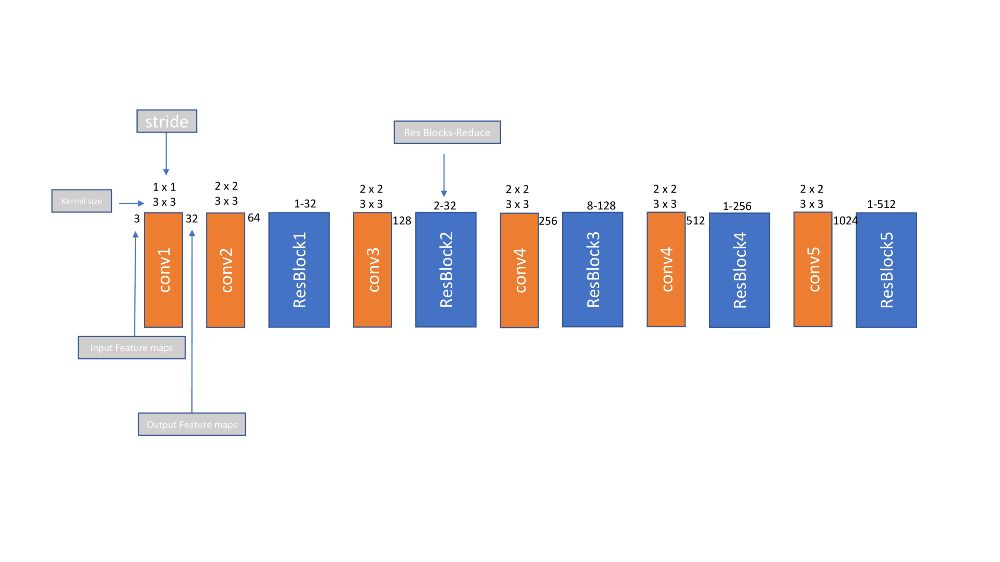
Darknet53
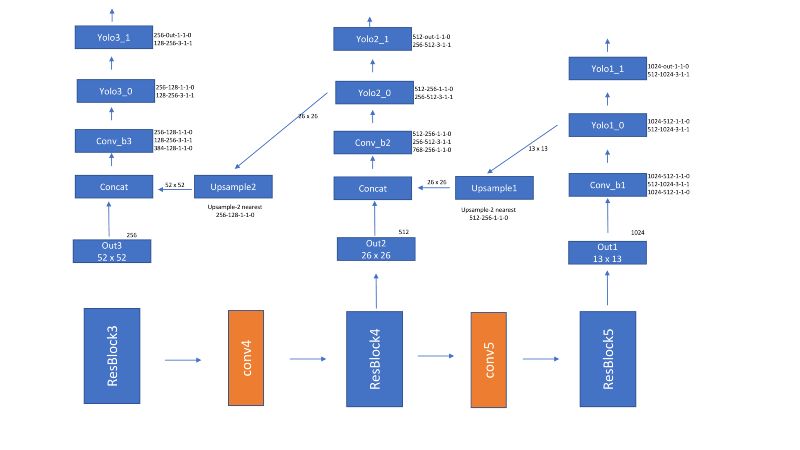
Yolov3 网络
损失函数与yolov2和yolov1相似,只是它使用了二进制交叉熵。在我的实验中,这不起作用,我使用了MSE损失除以正边界框的数量。
编码是按以下方式完成的。一个GT箱连接到锚上,其有最大IOU。锚只考虑包含GT箱中心的单元锚。
因为Yolov3使用3个尺度,52x52、26x26和13x13。边界框在每个比例上单独编码。每层损失单独计算,然后求和。
SSD-Single shot detector
这是我们将在本博客文章中讨论的最后一个框架,本文中几乎所有的想法都已经在上面讨论过了。
在Yolo和更快的RCNN发布后,本文以59fps的速度对300x300张输入尺寸的图像实现了74.3mAP,我们称这个网络为SSD300。同样,ssd512实现了76.9%mAP,超过了更快的r-cnn结果。
网络:

SSD
论文本身将其网络与Yolo进行了比较。它使用了一个vgg后端,并从多个尺度提取特性。注意,它没有使用任何侧向连接,比如Yolov3是FPN。
Anchor box 设计:
由于不同层的特征图已经捕获了尺度,所以SSD每层只使用一个尺度,但是尺度是使用公式sk=smin+(smax-smin)/(m-1)*(k-1)确定的,其中smin为0.2,smax为0.9。
使用[1、2、3、1/2、1/3]的纵横比。每个盒子的w和h由sk*a^(1/2)和sk/a^(1/2)决定。他们还增加了一个锚箱(sk*sk+1)^(1/2),每个位置总共6个锚箱。
如图,conv4_3(38x38)、conv7(fc7)(19x19)、conv8_2(10x10)、conv9_2(5x5)、conv10_2(3x3)和conv11_2(1x1)所示。作者建议在每个特征尺度上使用[4,6,6,6,4,4]锚。锚总数=(38x38x4)+(19x19x6)+(10x10x6)+(5x5x6)+(3x3x4)+(1x1x4)=(8732个锚)
编码:
SSD使用JacCard重叠,所有重叠大于0.5的锚定箱均视为+ve。
损失函数:

SSD损失
对于置信度,使用交叉熵损失。对于loc,使用平滑的L1损失。与更快的R-CNN不同,为了解决类别不平衡,他们不只是随机抽取+ve和-ve盒子。他们对阴性样本按降序排列了“反对”分数,并取了最上面的框。这样他们得到了一个3:1的-ve到+ve采样率,这导致更快的收敛。
就是这样。我们已经讨论了几乎所有关于物体检测的最新论文。还有很多其他的论文在提升mAP(例如groupnorm而不是batchnorm),训练更快(例如使用sgdr)来讨论。
但现在我们必须停止于此。
参考文献:
[1406.4729] Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
Abstract: Existing deep convolutional neural networks (CNNs) require a fixed-size (e.g., 224x224) input image. This…arxiv.org
[1512.02325] SSD: Single Shot MultiBox Detector
Abstract: We present a method for detecting objects in images using a single deep neural network. Our approach, named…arxiv.org
[1701.06659] DSSD : Deconvolutional Single Shot Detector
Abstract: The main contribution of this paper is an approach for introducing additional context into state-of-the-art…arxiv.org
[1504.08083] Fast R-CNN
Abstract: This paper proposes a Fast Region-based Convolutional Network method (Fast R-CNN) for object detection. Fast…arxiv.org
[1311.2524] Rich feature hierarchies for accurate object detection and semantic segmentation
Abstract: Object detection performance, as measured on the canonical PASCAL VOC dataset, has plateaued in the last few…arxiv.org
[1506.01497] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Abstract: State-of-the-art object detection networks depend on region proposal algorithms to hypothesize object…arxiv.org
[1612.03144] Feature Pyramid Networks for Object Detection
Abstract: Feature pyramids are a basic component in recognition systems for detecting objects at different scales. But…arxiv.org
[1708.02002] Focal Loss for Dense Object Detection
Abstract: The highest accuracy object detectors to date are based on a two-stage approach popularized by R-CNN, where a…arxiv.org
[1506.02640] You Only Look Once: Unified, Real-Time Object Detection
Abstract: We present YOLO, a new approach to object detection. Prior work on object detection repurposes classifiers to…arxiv.org
[1612.08242] YOLO9000: Better, Faster, Stronger
Abstract: We introduce YOLO9000, a state-of-the-art, real-time object detection system that can detect over 9000 object…arxiv.org
[1804.02767] YOLOv3: An Incremental Improvement
Abstract: We present some updates to YOLO! We made a bunch of little design changes to make it better. We also trained…arxiv.org
[1803.08494] Group Normalization
Abstract: Batch Normalization (BN) is a milestone technique in the development of deep learning, enabling various…arxiv.org
想要继续查看该篇文章相关链接和参考文献?
长按链接点击打开或点击底部【阅读原文】:
https://ai.yanxishe.com/page/TextTranslation/1426
AI研习社每日更新精彩内容,观看更多精彩内容:
盘点图像分类的窍门
深度学习目标检测算法综述
生成模型:基于单张图片找到物体位置
AutoML :无人驾驶机器学习模型设计自动化
等你来译:
如何在神经NLP处理中引用语义结构
你睡着了吗?不如起来给你的睡眠分个类吧!
高级DQNs:利用深度强化学习玩吃豆人游戏
深度强化学习新趋势:谷歌如何把好奇心引入强化学习智能体
【AI求职百题斩 - 每日一题】
【预告】明天开始,百题斩每日一题栏目将推出春节特别版,敬请关注!

想知道正确答案?
点击公众号菜单栏【每日一题】→【每日一题】或在公众号回复“0201”即可答题获取!
点击阅读原文,查看本文更多内容



