【泡泡一分钟】从三维流动中学习单目视觉里程计及三维稠密建图
每天一分钟,带你读遍机器人顶级会议文章
标题:Learning monocular visual odometry with dense 3D mapping from dense 3D flow
作者:Cheng Zhao, Li Sun, Pulak Purkait, Tom Duckett and Rustam Stolkin
来源:2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
编译:明煜航
审核:颜青松,陈世浪
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

本文介绍了一种完全依赖于深度学习的单目SLAM系统。该系统能使用一个由神经网络来学习得到的视觉里程计(L-VO)来实现定位,并同时进行三维稠密建图。使用一个子网络,该系统可以从单目图像中生成二维稠密流动以及深度图像,随后输入L-VO网络中的三维流动关联层以此来获得三维稠密流动。
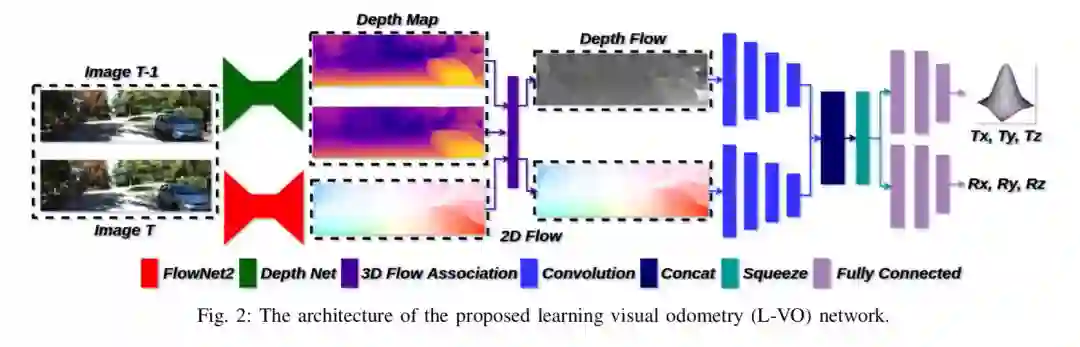
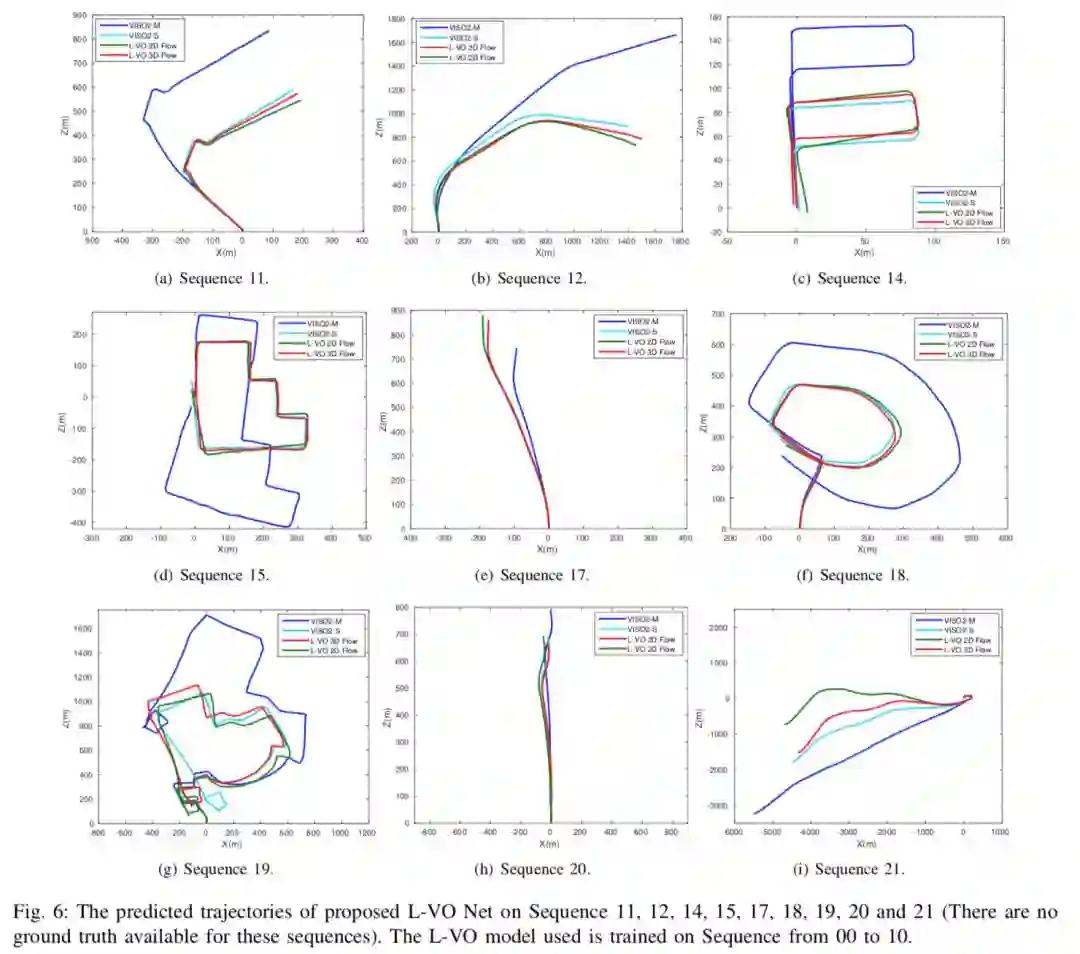
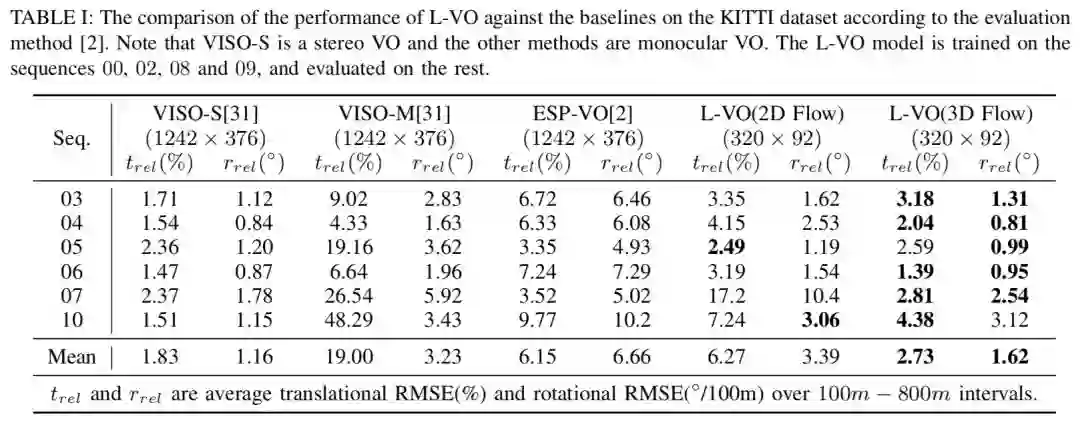
在得到三维稠密流动之后,双向的L-VO网络可以估计6DOF的相对位姿,并恢复车辆的轨迹。为了能够学到运动方向之间的相关性,作者在构建损失函数的时候采用了双变量的高斯模型。L-VO网络的在KITTI里程计基准中的总体性能能够达到2.68%的平均位移误差以及0.0143◦/m 的平均旋转误差。此外,神经网络生成的深度图被用来生成三维稠密地图。由此,这个基于学习的单目里程计以及稠密三维重建的视觉SLAM系统完成了。


Abstract
This paper introduces a fully deep learning ap- proach to monocular SLAM, which can perform simultaneous localization using a neural network for learning visual odometry (L-VO) and dense 3D mapping. Dense 2D flow and a depth image are generated from monocular images by sub-networks, which are then used by a 3D flow associated layer in the L-VO network to generate dense 3D flow. Given this 3D flow, the dual- stream L-VO network can then predict the 6DOF relative pose and furthermore reconstruct the vehicle trajectory. In order to learn the correlation between motion directions, the Bivariate Gaussian modeling is employed in the loss function. The L-VO network achieves an overall performance of 2.68% for average translational error and 0.0143◦/m for average rotational error on the KITTI odometry benchmark. Moreover, the learned depth is leveraged to generate a dense 3D map. As a result, an entire visual SLAM system, that is, learning monocular odometry combined with dense 3D mapping, is achieved.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号(paopaorobot_slam)。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com




