【泡泡图灵智库】ContextDesc:用跨模态上下文增强的局部描述子
泡泡图灵智库,带你精读机器人顶级会议文章
标题:ContextDesc: Local Descriptor Augmentation with Cross-Modality Context
作者:Zixin Luo,Tianwei Shen,Lei Zhou,Jiahui Zhang,
Yao Yao,Shiwei Li,Tian Fang,Long Quan
来源:arXiv2019
提取码:k2ii
编译:尹双双
审核:李永飞
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——ContextDesc: Local Descriptor Augmentation with Cross-Modality Context,该文章发表在arXiv 2019.4.8.
现有关于局部特征学习的研究大多集中于对单个关键点的基于patch的描述,而忽略了从关键点位置建立的空间关系。在本文中,我们通过引入上下文感知来扩展现有的局部特征描述符,从而超越了局部细节表示。具体来说,我们提出了一个统一的学习框架,该框架利用和聚合了跨模态上下文信息,
包括(i)来自高层图像表示的视觉上下文,(ii)来自二维关键点分布的几何上下文。此外,我们提出了一个有效的n对损失,避免了经验的参数搜索,提高了收敛性。与原始的局部特征描述相比,本文提出的增强方法是轻量级的,同时在多个场景多样化的大规模基准测试上有了显著的改进,在几何匹配应用中具有很强的实用性和泛化能力。
主要贡献
本文的主要贡献为:
1. 提出了一种新的视觉上下文编码器,常用于图像检索技术,集成了区域图像表示的高级视觉理解。
2. 提出了一种新的几何上下文编码器,它使用无序点,利用二维关键点分布的几何线索,同时对复杂的变化具有鲁棒性。
3 . 提出了一种新的N对损失,不需要人工超参数搜索,具有更好的收敛性。
算法流程
如图一所示,该框架由两个主要模块组成:准备(左)和增强(右)。准备模块以不同的方式提供输入信号(原始局部特征、高级视觉特征和关键点定位),然后将这些输入信号反馈给增强模块,并将其聚合为紧凑的特征描述。在测试时,每幅图像需要进行一次增强,得到K个特征向量对应K个关键点。
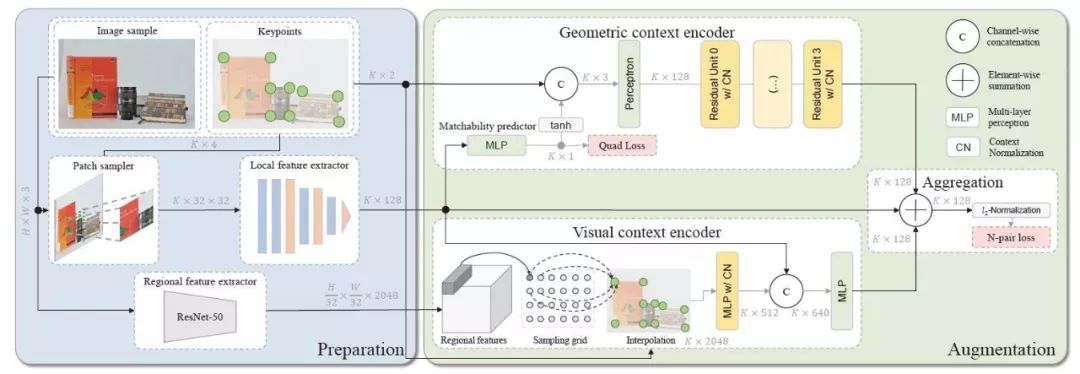
图一,提出的增强框架以单幅图像为输入,提取二维关键点、局部和区域特征,并将其编码为几何和视觉上下文,改进了原始局部特征描述。
1. 准备
Patch sampler
该模块以影像和它们的关键点作为输入,然后生成32*32的图像块。图像块用空间变换器采样,其参数由SIFT特征的关键点属性(坐标、方向和尺度)得到。所以,采样块具有与SIFT描述子相同的支持区域大小。
Local feature extractor
该模块以影像块作为输入,生成128维的特征描述子作为输出。本文采用一个轻量的7层卷积网络。
Regional feature extractor
在图像检索任务中,我们固定了块的采样尺度,并通过对区域表示方法的深入研究来挖掘上下文线索。在不损失通用性的前提下,我们重用了从现有的ResNet-50深度图像检索模型得到的特征。从最后一个瓶颈块中提取特征图,每个响应作为一个区域特征向量,有效地对应于图像中的特定区域。所以,我们可以得到H/32*W/32*2048个区域特征。
2. 几何上下文编码器
该模块以K个无序点为输入,输出128维对应的特征向量。每个输入点都表示为2D关键点坐标,并可与其他属性相关联。
2D point processing
在PointNet中加入上下文归一化(CN)和匹配中用潜在匹配(4维坐标对)剔除外点的基础上,进一步改善CN在单张影像上模型化2维点的能力。通过引入残差构架,让每个残差单元都由感知器构建,然后是上下文和批处理归一化。
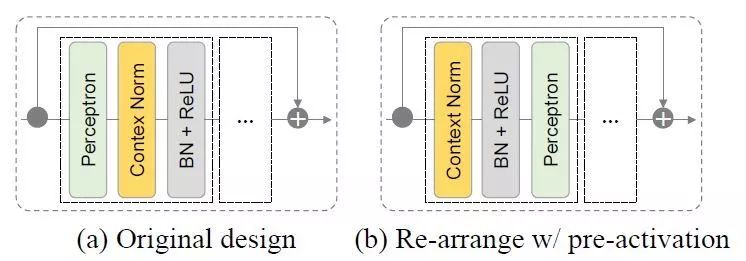
图二,不同设计的残差单元与上下文归一化,其中通过预激活重新安排比其对应的方法有了较大幅度改善。
Matchability predictor
匹配性预测,目标是在匹配阶段之前确定关键字描述符是否匹配。在实际应用中,为了改进不变性,匹配作为一种学习衰减,使关键点多样化,这样特征编码器就可以隐式地聚焦于更健壮匹配的的点。在本文中,我们使用深度学习技术代替随机森林来进行匹配性预测,并限定预测结果在图像之间一致。
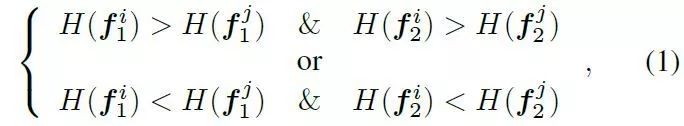
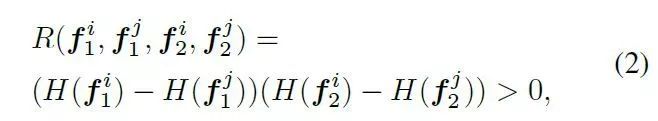
上式目的是保持每个关键点的排序,从而提高预测的可重复性。最终目标可以通过一个合页损失函数得到:
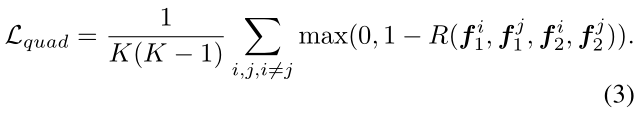
除了(3),来自最终增强特征的梯度将流经匹配性预测器,从而允许对整个编码器进行联合优化。

图三,整张影像的匹配性可视化
3.视觉上下文编码器
该模块需要H/32*W/32*2048的区域特征,K个局部特征和他们的位置,以及K个增强特征。本文用区域表示,所以关键是处理不同数目的区域特征和关键点(H/32*W/32和K)。通过把区域特征与一个影像上规则采样网格相关,然后在K个关键点位置上插入H/32*W/32网格。对于插值,本文使用基于k个最近邻的反向距离加权平均值。
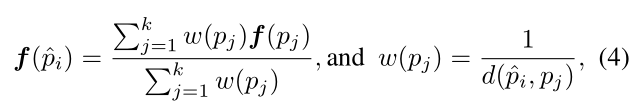
如果交并比超过0.5,那么继续计算两个区域的深度投影误差:区域中每个像素的深度投影误差之和/区域的像素数。若深度似然高于阈值,则将匹配区域的物体ID赋予当前区域,否则赋予当前区域一个新的物体ID。
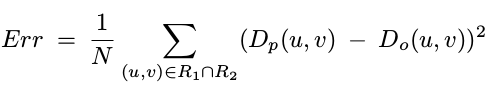
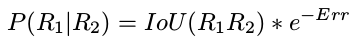
4.与原始局部特征集和
为了聚合上述两种上下文特征,类似CS结构,一种方法是把他们整合到一起构成一个384维(128*3)的特征。但这样会增加匹配时计算量,我们提出通过元素级求和与L2正则化将不同特征流连结到一个矢量里。
5. 带softmax temperature的N对损失
目的是将相似的样本从不同的样本中推到描述子空间的某个空白处,但是较难设置合适的边界值。
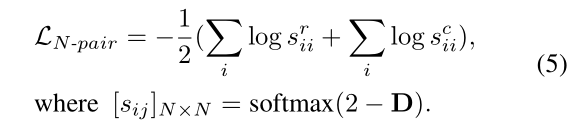
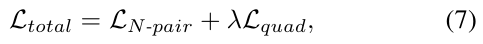
主要结果

表一,在HPSequence上比较不同设计的视觉和几何上下文编码器,以及整个增强方法的表现。‘i/v'表示分别表示illumination和viewpoint序列的评估。Recall=正确匹配/匹配。
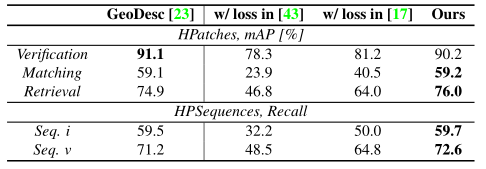
表二,在1)HPatches的3个互补任务:补丁确认,匹配和检索;2)HPSequence的两个序列分割上评估结果。

表三,在大数据集上的评估结果:室内SUN3D和室外YFCC100M.
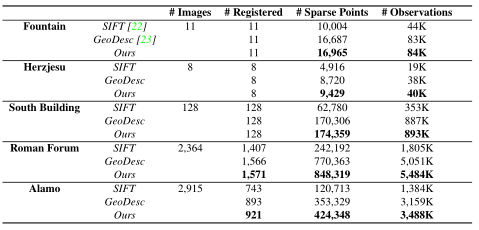
表四,在SFM数据集上的评估结果。

图四,不同较难场景下,RANSAC之后的匹配结果。从上到下:SIFT,GeoDesc和本文方法。增强特征有助于我们找到更多的内点匹配,从而可以更准确地恢复相机几何。
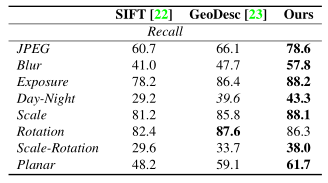
表五,基于Heinly基准数据集上的不同变换的评估结果。

表六,用NVIDIA GTX 1080 GPU,在896*896影像上的10K个关键点上评估提出框架的计算量。

Abstract
Most existing studies on learning local features focus on the patch-based descriptions of individual keypoints,whereas neglecting the spatial relations established fromtheir keypoint locations. In this paper, we go beyond the local detail representation by introducing context awareness to augment off-the-shelf local feature descriptors. Specifically, we propose a unified learning framework that leverages and aggregates the cross-modality contextual information, including (i) visual context from high-level image representation, and (ii) geometric context from 2D keypoint distribution. Moreover, we propose an effective N-pair loss that eschews the empirical hyper-parameter search and improves the convergence. The proposed augmentation scheme is lightweight compared with the raw local feature description, meanwhile improves remarkably on several large-scale benchmarks with diversified scenes, which demonstrates both strong practicality and generalization ability in geometric matching applications.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com

