ICCV 2019 | 马里兰&UC 伯克利共同提出:适应不断变化环境进行语义分割
本文为读者投稿,投稿方式见文末。
作者 | BBuf
编辑 | 唐里

1. 研究背景
2. 相关工作
2.1 无监督的域自适应
2.2图像合成
使用生成对抗网络(GAN)来进行图像合成越来越火,这种图像合成方式被认为是生成器和鉴别器之间的极大极小博弈。为了控制生成过程,加入了许多额外的信息如标签,文本,属性和图像等等。GAN还用于图像到图像转换的上下文中,其使用循环一致性或映射到共享特征空间将图像的样式转换为参考图像的样式。在不知道域的联合分布的情况下,这些方法试图从每个域中学习边际条件分布。然而,利用GAN生成高分辨率图像仍然困难且是密集计算型的。相比之下,神经网络风格迁移方法通常避免了生成模型的困难,简单地匹配特征统计Gram矩阵或执行通道独立的均值和方差对齐。ACE就在风格迁移的基础上,以当前任务的图像风格合成新的图像,同时保留原图像的语义信息。
3. 方法
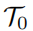 表示原始任务,
表示原始任务,
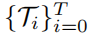 表示顺序给定的
表示顺序给定的
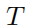 个目标任务。
进一步,使用
个目标任务。
进一步,使用
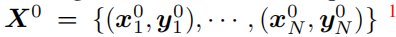 代表原任务N个图片以及对应的标签。
对于图片中的每个像素
代表原任务N个图片以及对应的标签。
对于图片中的每个像素
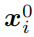 ,标签
,标签
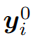 代表一个one-hot编码的向量。
我们把第i张图片表示为
代表一个one-hot编码的向量。
我们把第i张图片表示为
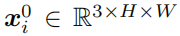 ,标签图表示为
,标签图表示为
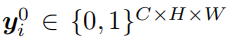 ,其中H和W代表图像长宽,C代表语义分割的分类数。
再定义
,其中H和W代表图像长宽,C代表语义分割的分类数。
再定义
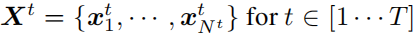 代表第t个顺序出现的任务,其中包含和原始图像相同分辨率的
代表第t个顺序出现的任务,其中包含和原始图像相同分辨率的
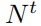 张图片。
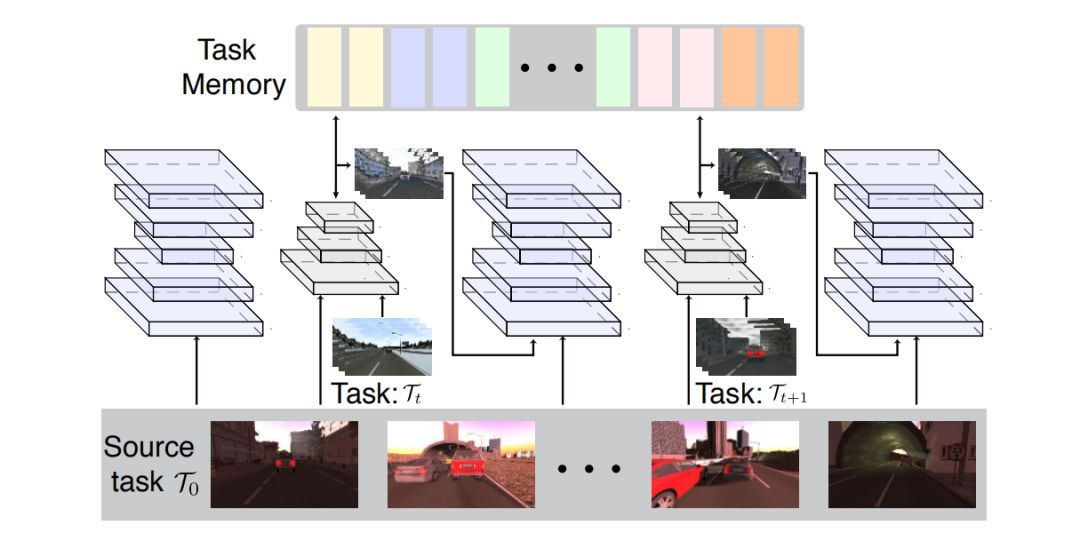
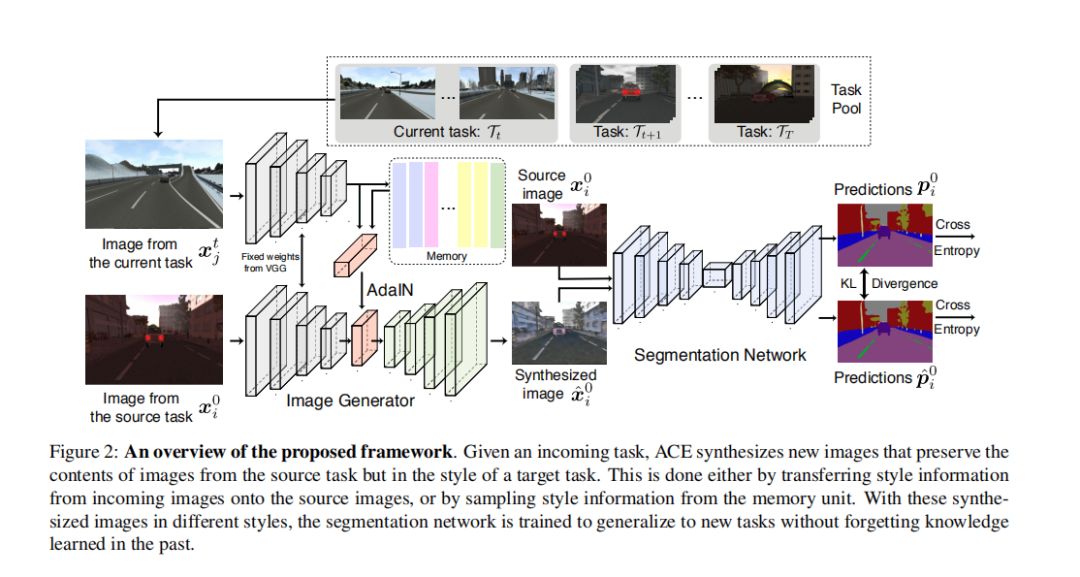
ACE包含4个关键组成部分:
一个编码器,一个生成器,一个记忆单元,和一个语义分割网络。
编码器网络将原始图片
张图片。
ACE包含4个关键组成部分:
一个编码器,一个生成器,一个记忆单元,和一个语义分割网络。
编码器网络将原始图片
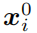 转换为一个特征图表示
转换为一个特征图表示
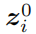 ,在这里是512个特征图。
生成器网络将特征图z转换为图像。
目标图像的风格就用在生成器之前的特征向量的均值和方差来描述。
记忆单元记住每一种风格图像的特征数据(1024值,就是512个特征图的均值和方差)。
通过从记忆单元中检索相关数据风格的特征,将原图像的特征图重新规范化以具有相应的数据特征,然后将特征传给生成器创建图像,可以将源图像风格化为任何先前遇到的域中的图像。
,在这里是512个特征图。
生成器网络将特征图z转换为图像。
目标图像的风格就用在生成器之前的特征向量的均值和方差来描述。
记忆单元记住每一种风格图像的特征数据(1024值,就是512个特征图的均值和方差)。
通过从记忆单元中检索相关数据风格的特征,将原图像的特征图重新规范化以具有相应的数据特征,然后将特征传给生成器创建图像,可以将源图像风格化为任何先前遇到的域中的图像。
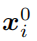 和
和
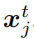 训练提取固定特征表示
训练提取固定特征表示
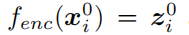 和
和
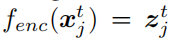 时被冻结。
图像生成器
时被冻结。
图像生成器
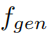 ,权重参数用
,权重参数用
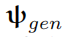 表示,将特征图反卷积为图像。
输出图像的风格信息可以用AdaIN从目标图像中借鉴过来,即是重新规整化原始图片的特征图
表示,将特征图反卷积为图像。
输出图像的风格信息可以用AdaIN从目标图像中借鉴过来,即是重新规整化原始图片的特征图
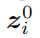 使得它和选定的目标图像特征图
使得它和选定的目标图像特征图
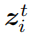 有相同的均值和方差。
如公式1所示:
有相同的均值和方差。
如公式1所示:
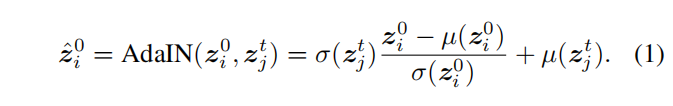
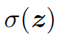 和
和
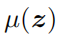 代表特征图z每个通道的均值和方差。
归整化的特征图
代表特征图z每个通道的均值和方差。
归整化的特征图
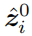 可以放进生成器产生一个新图片
可以放进生成器产生一个新图片
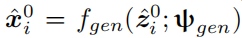 。
如果参数
。
如果参数
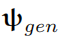 适当,结果图像就可以在
适当,结果图像就可以在
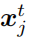 的风格下拥有
的风格下拥有
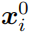 的语义信息。
的语义信息。
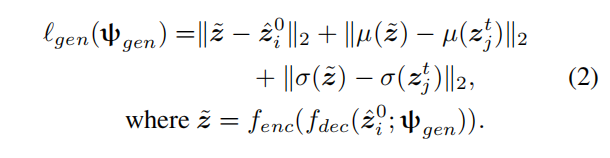
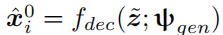 被分割网络
被分割网络
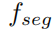 来处理,参数用
来处理,参数用
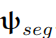 表示。
网络产生一个标签图
表示。
网络产生一个标签图
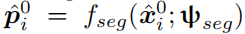 然后使用逐像素的多分类交叉熵损失来训练。
另外,由于合成图像可能会丢失原始图像的某些细节降低分割网络的性能,我们进一步约束合成图像
然后使用逐像素的多分类交叉熵损失来训练。
另外,由于合成图像可能会丢失原始图像的某些细节降低分割网络的性能,我们进一步约束合成图像
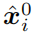 通过网络产生的分割结果
通过网络产生的分割结果
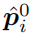 和原始图像
和原始图像
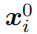 的分割结果
的分割结果
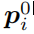 越接近越好。
这个是通过测量这两个输出的KL散度来得到,语义分割的损失函数最终表示如下:
越接近越好。
这个是通过测量这两个输出的KL散度来得到,语义分割的损失函数最终表示如下:
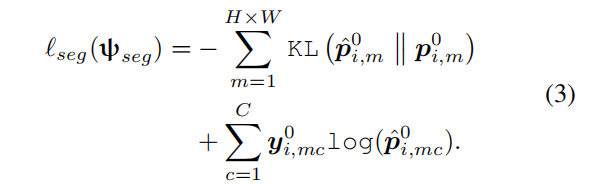
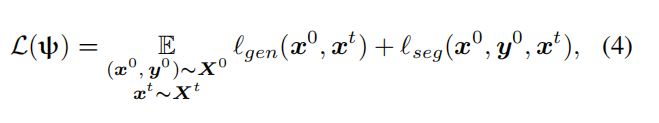
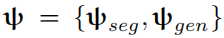 代表网络的参数。
注意,分割网络的参数隐式依赖于生成器的参数,因为分割网络是在生成器的结果上进行优化的。
代表网络的参数。
注意,分割网络的参数隐式依赖于生成器的参数,因为分割网络是在生成器的结果上进行优化的。
 每个通道上的均值和方差。
所以,我们只需要将特征数据保存在内存
每个通道上的均值和方差。
所以,我们只需要将特征数据保存在内存
 中就可以完成有效的重放。
当我们学习第t个任务
中就可以完成有效的重放。
当我们学习第t个任务
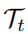 时,我们选择一个测试集图像并存储它们的1024维度的特征。
当处理第
时,我们选择一个测试集图像并存储它们的1024维度的特征。
当处理第
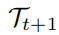 个任务时,我们随机挑选
中的图像来对当前让任务的图像风格化,使得其具有
个任务时,我们随机挑选
中的图像来对当前让任务的图像风格化,使得其具有
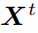 的风格。
的风格。
 ,这是
,这是
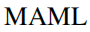 方法的近似。
首先随机选择一个任务,然后执行SGD来微调该任务。然后在微调参数的方向上采取“元梯度”步骤。下一轮继续执行不其他任务,以产生针对大多数任务的最佳参数只有微小扰动的模型。
的元梯度
方法的近似。
首先随机选择一个任务,然后执行SGD来微调该任务。然后在微调参数的方向上采取“元梯度”步骤。下一轮继续执行不其他任务,以产生针对大多数任务的最佳参数只有微小扰动的模型。
的元梯度
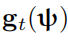 被如下定义:
被如下定义:
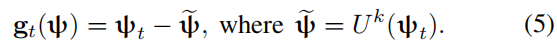
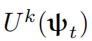 代表随机选择一个任务执行k次随机梯度下降。为了实现快速适应,我们从当前任务以及内存中采样以使用来自整个历史任务的元梯度来执行元更新。然后对当前任务微调元梯度以提升性能。这个过程可以用算法1来展示:
代表随机选择一个任务执行k次随机梯度下降。为了实现快速适应,我们从当前任务以及内存中采样以使用来自整个历史任务的元梯度来执行元更新。然后对当前任务微调元梯度以提升性能。这个过程可以用算法1来展示:

4. 结果
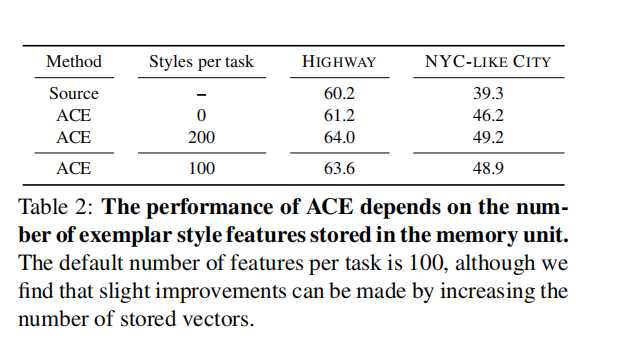
5. 结论
 和
和
邮箱:jiawei@leiphone.com
微信:jiawei1066

张钹院士:人工智能的魅力就是它永远在路上 | CCAI 2019
Facebook 自然语言处理新突破:新模型能力赶超人类 & 超难 NLP 新基准

登录查看更多
相关内容
Arxiv
5+阅读 · 2019年2月27日
Arxiv
4+阅读 · 2019年1月17日
Arxiv
5+阅读 · 2018年7月21日
Arxiv
8+阅读 · 2018年6月28日
Arxiv
5+阅读 · 2018年3月23日




相关VIP内容
相关资讯
相关论文
Arxiv
5+阅读 · 2019年2月27日
Arxiv
4+阅读 · 2019年1月17日
Arxiv
5+阅读 · 2018年7月21日
Arxiv
8+阅读 · 2018年6月28日
Arxiv
5+阅读 · 2018年3月23日