【泡泡图灵智库】FlowNet3D:在三维点云中学习场景流(CVPR)
泡泡图灵智库,带你精读机器人顶级会议文章
标题:FlowNet3D: Learning Scene Flow in 3D Point Clouds
作者:Xingyu Liu, Charles R. Qi, Leonidas J. Guibas Stanford University
编译:杨宇超
审核:谭艾琳
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章是——FlowNet3D: Learning Scene Flow in 3D Point Clouds,该文章发表于CVPR 2019。
机器人和人机交互中的许多应用都可以从理解动态环境中点的三维运动中获益,这种运动被广泛称为场景流。以往的方法大多以立体图像和RGB-D图像作为输入,很少有直接从点云估计场景流的方法。在本文工作中,作者提出了一种新型的深度神经网络FlowNet3D,它以端到端的方式从点云学习场景流。该网络同时学习点云的深层层次特征和表示点运动的流嵌入,支持两个新提出的点集学习层。评估了来自FlyingThings3D的合成数据和来自KITTI的真实激光雷达扫描数据。该网络仅用合成数据的训练,便成功地将其推广到实际扫描中,性能优于各种基线,并显示出与现有技术相比具有竞争力的结果。
主要贡献
1. 提出了一种新的架构,称为FlowNet3D,它可以从一对连续的点云端到端估计场景流。
2. 在点云上引入了两个新的学习层:学习关联两个点云的流嵌入层和学习将一组点的特性传播到另一组点的上采样层。
3. 展示了如何将所提出的FlowNet3D架构应用到KITTI的实际激光雷达扫描中,并与传统方法相比,在三维场景流估计方面取得了很大的改进。
算法流程
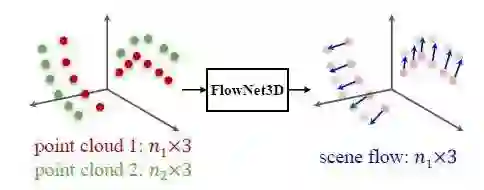
图1 本文方法示意图
如图1所示,该项目进行了点云的端到端的场景流估计,模型的输入为连续两帧的原始点云,输出为第一帧中所有点所对应的密集的场景流。
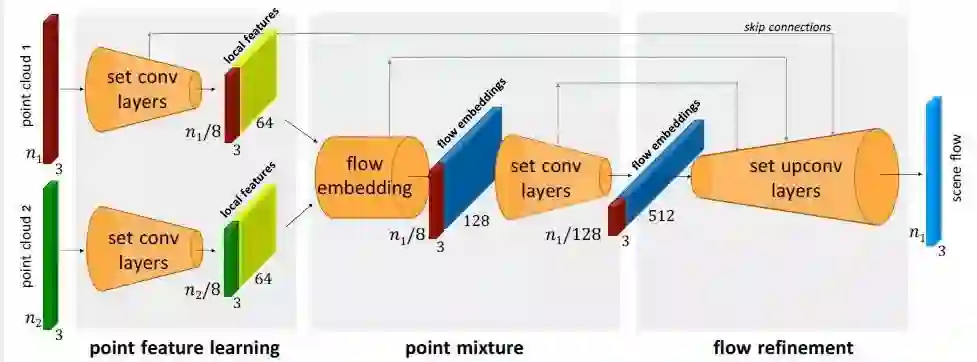
图2 FlowNet3D网络结构
1. FlowNet3D结构
图2为FlowNet3D结构,这是一种基于点云的端到端的场景流估计网络。该模型具有(1)点特征学习、(2)点混合和(3)流细化三个关键模块。在这些模块下是三个关键的深度点云处理层:set conv层、flow embedded层和set upconv层,这三个关键层的解释如图3所示。

图3 关键层理解
图3所示为点云处理的三个可训练层。左:set conv层,学习深度点云功能;中间:流嵌入层,学习两个点云之间的几何关系,推断运动;右:set upconv层,以一种可学习的方式向上采样和传播点特性。
2. 点云特征学习
由于点云是一组不规则、无序的点,传统的卷积不适合对其进行处理。因此,本文遵循最近提出的PointNet++体系结构,该结构是一个学习分层特性的平移不变网络。虽然set conv层是为3D分类和分割而设计的,但是发现它的特征学习层对于场景流的任务也是非常强大的。
3. 点混合
为了混合两个点云,本文依赖于一个新的流嵌入层(图3中间)。本文的流嵌入层学习聚合(几何)特征相似性和点的空间关系,从而生成编码点运动的嵌入。
4. 流细化
在流细化模块中,本文向上采样与中间点关联的流嵌入到原始点,并在最后一层预测所有原始点的流。向上采样的步骤是通过一个可学习的新层set upconv层来实现的,该层学会以一种明智的方式传播和细化嵌入。
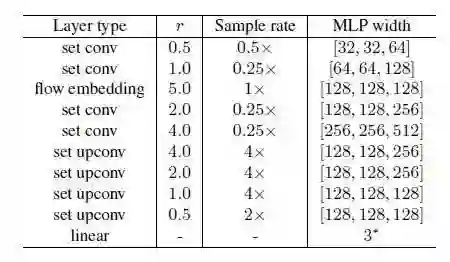
表1 网络结构
5. 具体网络结构
如表1所示,FlowNet3D架构由四个set conv层、一个流嵌入层和四个set upconv层(对应于四个set conv层)和一个输出R3预测场景流的最终线性流回归层组成。对于set upconv层,有跳跃连接来连接set conv输出特性。每个可学习层对函数h采用多层感知器,并以其线性层宽参数化若干个Linear-BatchNorm-ReLU层。
主要结果
1. 基于FlyingThings3D的评估与验证
FlyingThings3D。该数据集由立体图像和RGB-D图像组成,这些图像来自于从ShapeNet采样的多个随机移动对象的场景。共有32k幅左右的立体图像,配以地面真值视差和光流图。本文随机抽取其中20000个作为训练集,2000个作为测试集。没有使用RGB图像,而是通过弹出视差图到3D点云和光流到场景流来预处理数据。
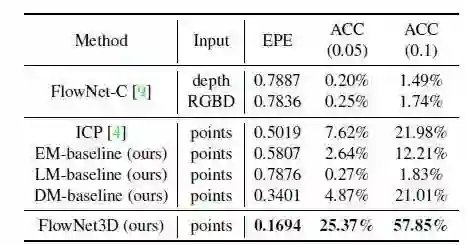
表2 FlyingThings3D上的评估结果
与表2中基线模型相比,FlowNet3D实现了更低的EPE以及更高的精度。
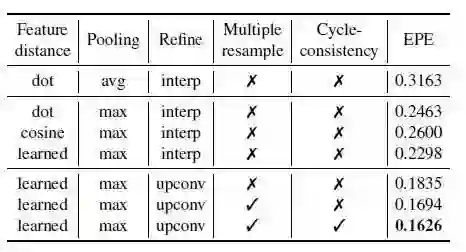
表3 Ablation实验
表3为FlyingThings3D三维数据集的消融研究。实验研究了距离函数、h中池的类型、用于流细化的层以及重采样和循环一致性正则化的影响。
2. 推广到KITTI中实际激光雷达扫描的结果
本文的模型在合成数据上进行训练,可以直接用于检测从实际激光雷达扫描的KITTI点云中的场景流。
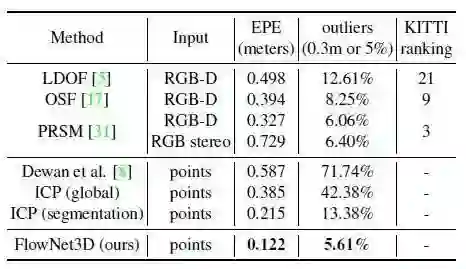
表4 推广到KITTI的激光扫描点
如表4所示,作者将FlowNet3D与现有技术进行了比较,后者针对2D光流以及点云上的两个ICP基线进行了优化。与基于二维图像的方法相比,本文方法在场景流估计方面具有很大的优势,能够显著降低三维端点误差(相对于[31]的相对误差降低63%)和三维离群比。本文方法也优于依赖全局场景刚性或分割正确性的两个ICP基线。得出结论,该模型虽然只训练合成数据,但能够推广到真正的激光雷达点云。
3. 应用
虽然场景流本身是理解运动的低阶信号,但它可以为许多更高级别的应用程序提供有用的提示,可以用于3D扫描登记,运动分割等。

Abstract
Many applications in robotics and human-computer interaction can benefit from understanding 3D motion of points in a dynamic environment, widely noted as scene flow. While most previous methods focus on stereo and RGB-D images as input, few try to estimate scene flow directly from point clouds. In this work, we propose a novel deep neural network named FlowNet3D that learns scene flow from point clouds in an end-to-end fashion. Our network simultaneously learns deep hierarchical features of point clouds and flow embeddings that represent point motions, supported by two newly proposed learning layers for point sets. We evaluate the network on both challenging synthetic data from FlyingThings3D and real Lidar scans from KITTI. Trained on synthetic data only, our network successfully generalizes to real scans, outperforming various baselines and showing competitive results to the prior art. We also demonstrate two applications of our scene flow output (scan registration and motion segmentation) to show its potential wide use cases.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
点击阅读原文,即可获取本文下载链接。提取码:rfxr
复制这段内容后打开百度网盘手机App,操作更方便哦
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/bbs/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com



