

论文题目:DePLM: Denoising Protein Language Models for Property Optimizations
本文作者:王泽元(浙江大学)、张强(浙江大学)、丁科炎(浙江大学)、秦铭(浙江大学)、李晓彤(浙江大学)、庄祥(浙江大学)、Yu Zhao(腾讯)、Jianhua Yao (腾讯)、陈华钧(浙江大学)****
发表会议:NeurIPS 2024****
论文链接:https://neurips.cc/virtual/2024/poster/95517****
代码链接:https://github.com/HICAI-ZJU/DePLM
欢迎转载,转载请注明出处****

一、动机
蛋白质优化是一项基础的生物学任务,旨在通过修改蛋白质序列来增强其性能。在自然界中,蛋白质经过数十亿年的进化,形成了多样化的结构和功能。这种进化的多样性为药物发现和材料科学等领域的进步提供了重要机遇。然而,现有蛋白质的固有属性,如热稳定性,往往不能满足各种实际场景的需求。因此,研究人员致力于优化蛋白质以增强其感兴趣的属性。传统的深度突变扫描(DMS)和定向进化(DE)依赖于昂贵的湿实验。近年来,计算方法通过准确模拟蛋白质与其属性适应度之间的关系,即所谓的“适应度景观”,在高效蛋白质优化中变得至关重要。
二、贡献
本文介绍了一种新颖的方法——去噪蛋白质语言模型(DePLM),用于改进蛋白质适应度预测。DePLM的核心思想是将蛋白质语言模型(PLMs)捕获的进化信息(EI)视为包含属性相关和不相关信息的混合体,其中不相关信息对于目标属性的优化任务类似于“噪声”,需要被消除。DePLM通过在属性值的排序空间中进行扩散过程来去噪EI,从而增强模型的泛化能力,并确保与数据集无关的学习。通过广泛的实验结果,证明了DePLM不仅在突变效应预测方面超越了最新技术,而且对新蛋白质展现出强大的泛化能力。 三、方法
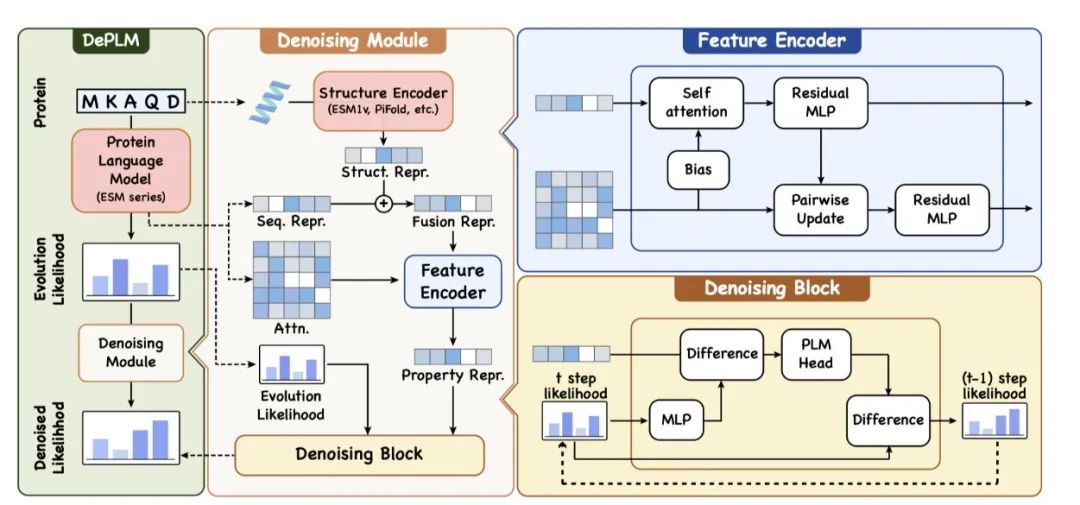
DePLM的设计目标是从PLMs产生的嘈杂进化似然中过滤掉不相关信息。给定一个野生型蛋白质,PLM产生的进化似然可以表示为,其中表示在位置发生20种氨基酸的概率。这个似然可以分解为目标属性似然和由不相关属性引入的噪声似然,使得。DePLM接受嘈杂的似然作为输入,并通过基于排序的去噪扩散过程来提炼它,以隔离期望的似然。DePLM的框架包括两个主要过程:正向扩散过程和学习的逆向去噪过程。正向过程中,逐渐向真实情况添加少量噪声。逆向去噪过程然后学习通过逐步消除累积的噪声来恢复真实情况。DePLM提出了一种基于排序的去噪扩散过程,专注于最大化排序相关性。给定真实似然的目标属性排序和噪声进化似然的排序,沿着这个过程序列生成中间排序变量。DePLM首先学习蛋白质表示(特征编码器),然后使用它来指导识别和消除噪声的过程(去噪块)。特征编码器从序列和结构中编码特征,因为它们互补地描述了突变的影响。结构信息通过训练有素的结构编码器(如ESM-IF)获得,处理蛋白质主链以产生结构表示hs。然后将这两组表示使用多层感知机(MLPs)合并,得到统一的表示。去噪块给定t步的中间似然变量,使用去噪块来实现方程。核心前提是应该只包含特定于属性的蛋白质信息。通过从噪声的隐藏表示中减去,隔离噪声的隐藏表示。然后,这个隐藏表示被转换为似然空间。
四、实验
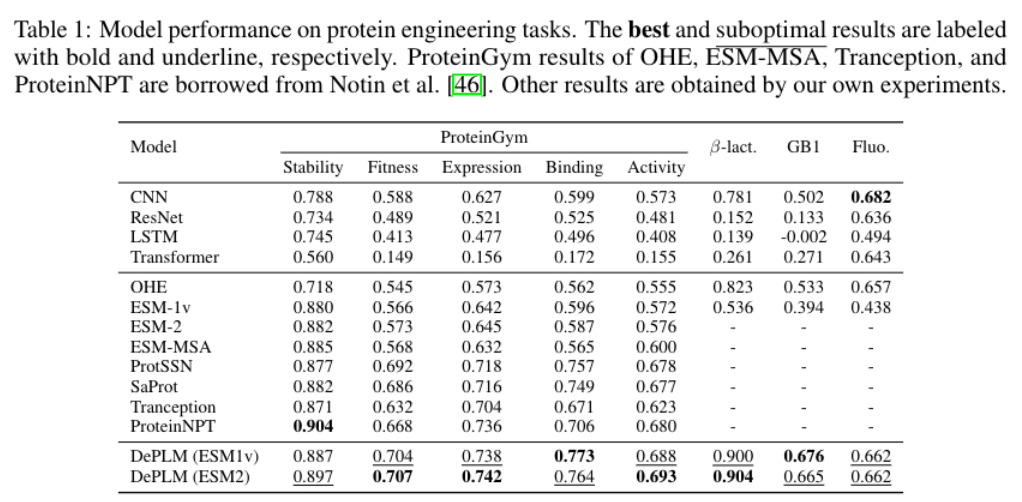
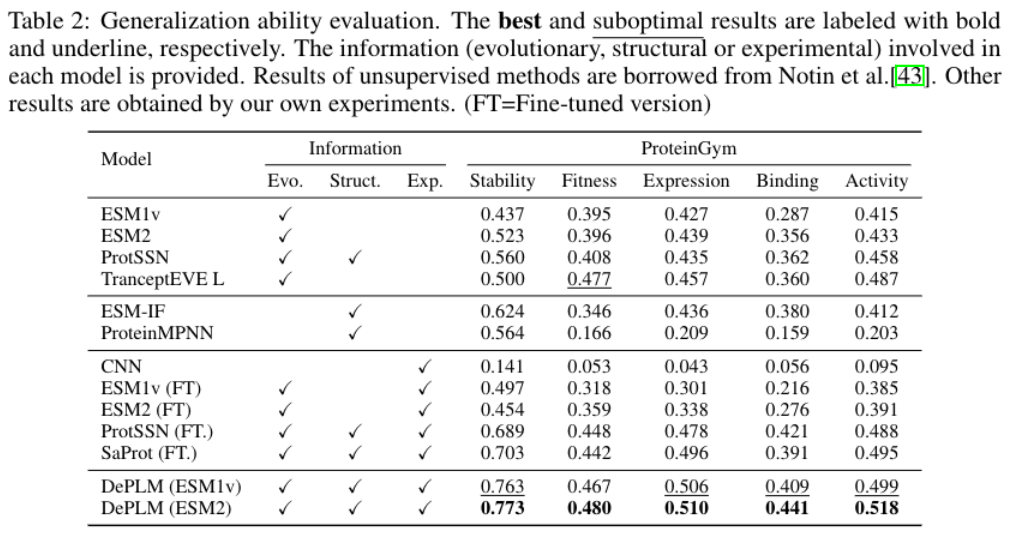
在实验部分,作者在多个数据集上广泛评估了DePLM,并证明了其卓越的性能和强大的泛化能力。实验旨在回答以下关键问题:1. 性能比较(Q1):DePLM能否在蛋白质适应度预测任务上击败最新技术?通过在ProteinGym、β-Lactamase(β-乳酸酶)和Fluorescence(荧光)等四个基准测试中的实验,DePLM与九个基线模型进行了比较,包括CNN、ResNet、LSTM和Transformer等。结果显示,DePLM在性能上优于这些基线,证实了将进化信息与实验数据集成在蛋白质工程任务中的优势。
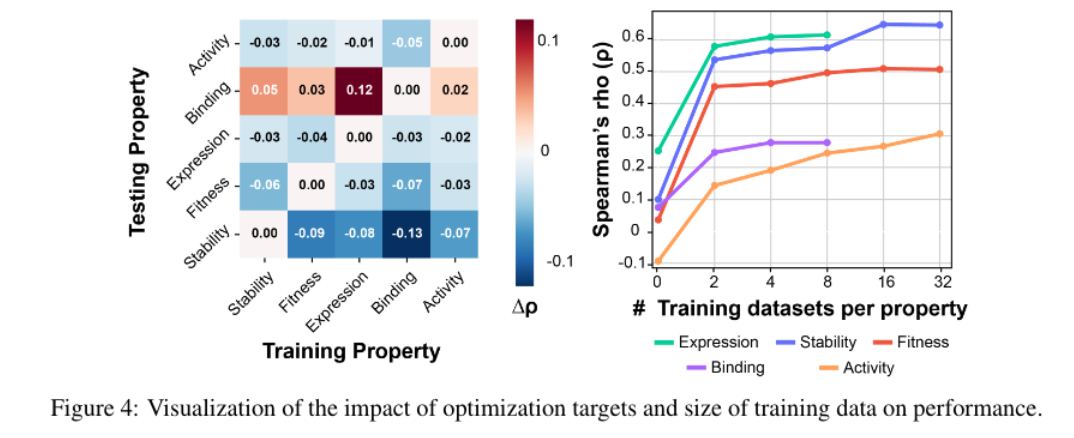
五、总结
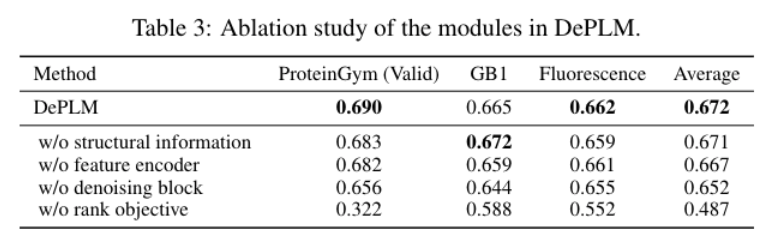
本文提出的DePLM方法,通过利用特征编码器获得表达性蛋白质表示,并使用它们从嘈杂的进化似然中提取特定于属性的似然,用于突变效应预测。实验表明,DePLM不仅超越了最新技术的基线,还显示出卓越的泛化能力。此外,分析证实了使用足够大的数据集或结合其他相关属性的数据可以显著提高性能。尽管由于资源限制,实验是使用野生型边缘概率进行的,这种方法预测所有突变的影响,在单一前向传递中,通过累加个体突变的影响来估计多重突变的后果。然而,这种方法并不理想,因为它忽略了突变之间的复杂相互作用。DePLM有潜力通过利用更有效的预测技术,如掩蔽边缘概率,来实现更好的性能,以预测多重突变的影响。
