PyTorch 中使用深度学习(CNN和LSTM)的自动图像捕获

本文为 AI 研习社编译的技术博客,原标题 :How to Develop a Probabilistic Forecasting Model to Predict Air Pollution Days
翻译 | 就2 校对 | 就2 整理 | 志豪
原文链接:
https://www.analyticsvidhya.com/blog/2018/04/solving-an-image-captioning-task-using-deep-learning/
Faizan Shaikh,2018年4月2日
介绍
深度学习现在是一个非常猖獗的领域 - 有如此多的应用程序日复一日地出现。深入了解深度学习的最佳方法是动手实践。尽可能多地参与项目,并尝试自己完成。这将帮助您更深入地掌握主题,并帮助您成为更好的深度学习实践者。
在本文中,我们将看一个有趣的多模态主题,我们将结合图像和文本处理来构建一个有用的深度学习应用程序,即图像描述。图像描述是指从图像生成文本描述的过程 - 基于图像中的对象和动作。例如:

这个过程在现实生活中有很多潜在的应用。值得注意的是保存图像的标题,以便在此描述的基础上可以在稍后阶段轻松检索。
让我们继续吧!
注意:本文假设您了解深度学习的基础知识,并且之前使用过CNN处理图像处理问题。 如果您想了解这些概念,可以先阅读这些文章:
深度学习基础 - 从人工神经网络开始
卷积神经网络(CNNs)的体系结构揭秘
教程:使用Keras优化神经网络(带图像识别案例研究)
深度学习要点 - Attention的序列到序列建模(使用python)
目录
图像描述问题需要什么?
解决任务的方法论
实施演练
下一步?
图像描述问题需要什么
假设你看到这张照片 –

你想到的第一件事是什么? (PS:请在下面的评论中告诉我们!)。
以下是人们可能提出的几句话:
一个男人和一个女孩坐在地上吃。
人行道上,一个男人和一个小女孩正坐一个蓝色的袋子旁边吃东西。
一个男人穿着一件黑色的衬衫和一个穿着橙色礼服的小女孩在分享乐趣。
快速浏览一下就足以让您理解并描述图片中正在发生的事情。从人工系统自动生成此文本描述是图像描述的任务。
任务很简单 - 生成的输出应该通过单个句子描述图像中显示的内容 - 存在的对象,它们的属性,正在执行的动作以及对象之间的交互等。但是与其他图像处理问题一样,在人工系统中复制此行为是一项艰巨的任务,因此需要使用复杂和先进的技术(如深度学习)来解决这个任务。
在继续之前,我要特别感谢Andrej Kartpathy等人,他用他富有洞察力的课程帮助我理解了这个主题 - CS231n 。
解决任务的方法论
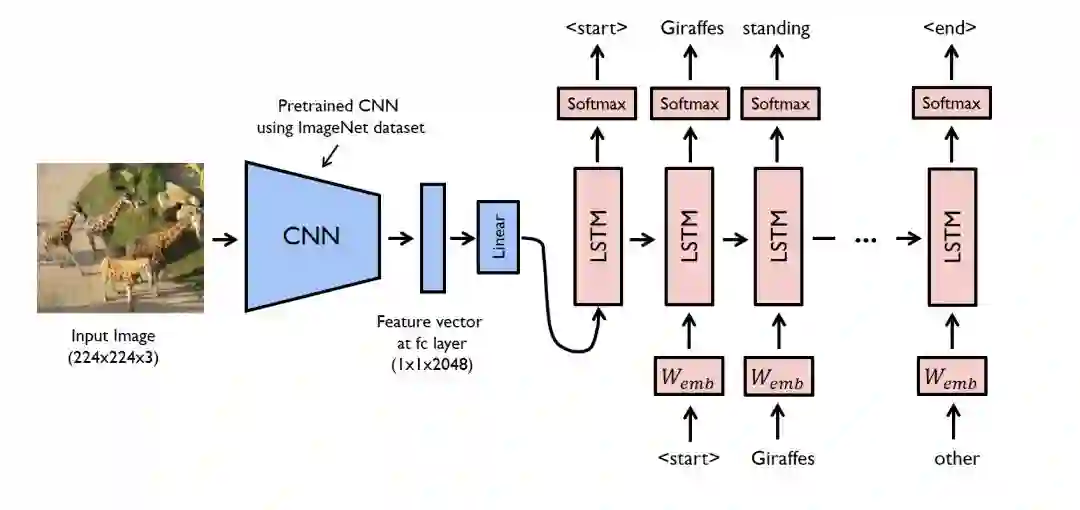
图像描述的任务在逻辑上可以分为两个模块 - 一个是基于图像的模型 - 从图像中提取特征和细微差别,另一个是基于语言的模型 - 它基于我们的图像模型通过我们给出的特征和对象翻译成自然句。
对于我们的基于图像的模型(即编码器) - 我们通常依赖于卷积神经网络模型。对于我们基于语言的模型(即解码器) - 我们依赖于循环神经网络。下图总结了上面给出的方法。

通常,预训练的CNN从输入图像中提取特征。线性变换特征向量以具有与RNN / LSTM网络的输入维度相同的维度。该网络在我们的特征向量上被训练为语言模型。
为了训练我们的LSTM模型,我们预定义了标签和目标文本。例如,如果标题是“一个男人和一个女孩坐在地上吃饭”,我们的标签和目标将如下 -
Label – [ <start>, A, man, and, a, girl, sit, on, the, ground, and, eat, . ]
Target – [ A, man, and, a, girl, sit, on, the, ground, and, eat, ., <end> ]
这样做是为了使我们的模型理解标记序列的开始和结束。

实施演练
让我们看一下Pytorch中图像描述的简单实现。我们将图像作为输入,并使用深度学习模型预测其描述。
可以在GitHub上找到此示例的代码。此代码的原作者是Yunjey Choi。为他在Pytorch中出色的例子致敬!
在本演练中,预训练的resnet-152模型用作编码器,解码器是LSTM网络。
在运行此示例中给出的代码之前,您必须先安装。确保你有一个工作的python环境,最好安装anaconda。然后运行以下命令来安装其余所需的库。
git clone https://github.com/pdollar/coco.gitcd coco/PythonAPI/
make
python setup.py build
python setup.py installcd ../../
git clone https://github.com/yunjey/pytorch-tutorial.gitcd pytorch-tutorial/tutorials/03-advanced/image_captioning/
pip install -r requirements.txt
设置好系统后,下载训练模型所需的数据集。这里我们将使用MS-COCO数据集。可以运行以下命令自动下载数据集:
chmod +x download.sh
./download.sh
现在,您可以开始模型构建过程。 首先 - 您必须处理输入:
# Search for all the possible words in the dataset and # build a vocabulary listpython build_vocab.py # resize all the images to bring them to shape 224x224python resize.py
现在,您可以通过运行以下命令开始训练模型:
python train.py --num_epochs 10 --learning_rate 0.01
只是为了窥视引擎并查看我们如何定义模型,您可以参考model.py文件中编写的代码。
import torch
import torch.nn as nn
import torchvision.models as models
from torch.nn.utils.rnn import pack_padded_sequence
from torch.autograd import Variable
class EncoderCNN(nn.Module):
def __init__(self, embed_size):
"""Load the pretrained ResNet-152 and replace top fc layer."""
super(EncoderCNN, self).__init__()
resnet = models.resnet152(pretrained=True)
modules = list(resnet.children())[:-1] # delete the last fc layer.
self.resnet = nn.Sequential(*modules)
self.linear = nn.Linear(resnet.fc.in_features, embed_size)
self.bn = nn.BatchNorm1d(embed_size, momentum=0.01)
self.init_weights()
def init_weights(self):
"""Initialize the weights."""
self.linear.weight.data.normal_(0.0, 0.02)
self.linear.bias.data.fill_(0)
def forward(self, images):
"""Extract the image feature vectors."""
features = self.resnet(images)
features = Variable(features.data)
features = features.view(features.size(0), -1)
features = self.bn(self.linear(features))
return features
class DecoderRNN(nn.Module):
def __init__(self, embed_size, hidden_size, vocab_size, num_layers):
"""Set the hyper-parameters and build the layers."""
super(DecoderRNN, self).__init__()
self.embed = nn.Embedding(vocab_size, embed_size)
self.lstm = nn.LSTM(embed_size, hidden_size, num_layers, batch_first=True)
self.linear = nn.Linear(hidden_size, vocab_size)
self.init_weights()
def init_weights(self):
"""Initialize weights."""
self.embed.weight.data.uniform_(-0.1, 0.1)
self.linear.weight.data.uniform_(-0.1, 0.1)
self.linear.bias.data.fill_(0)
def forward(self, features, captions, lengths):
"""Decode image feature vectors and generates captions."""
embeddings = self.embed(captions)
embeddings = torch.cat((features.unsqueeze(1), embeddings), 1)
packed = pack_padded_sequence(embeddings, lengths, batch_first=True)
hiddens, _ = self.lstm(packed)
outputs = self.linear(hiddens[0])
return outputs
def sample(self, features, states=None):
"""Samples captions for given image features (Greedy search)."""
sampled_ids = []
inputs = features.unsqueeze(1)
for i in range(20): # maximum sampling length
hiddens, states = self.lstm(inputs, states) # (batch_size, 1, hidden_size),
outputs = self.linear(hiddens.squeeze(1)) # (batch_size, vocab_size)
predicted = outputs.max(1)[1]
sampled_ids.append(predicted)
inputs = self.embed(predicted)
inputs = inputs.unsqueeze(1) # (batch_size, 1, embed_size)
sampled_ids = torch.cat(sampled_ids, 1) # (batch_size, 20)
return sampled_ids.squeeze()
现在我们可以使用以下方法测试我们的模型:
python sample.py --image='png/example.png'
对于我们的示例图像,我们的模型为我们提供了输出:

<start> 一群长颈鹿站在草地上。<end>
这就是为图像描述构建深度学习模型的方法!
然后去哪儿?
我们上面看到的模型只是冰山一角。关于这个主题已经做了很多研究。目前,图像描述中最先进的模型是微软的CaptionBot. 您可以在他们的官方网站上查看该系统的演示 (link : www.captionbot.ai)。
我将列出一些可用于构建更好的图像描述模型的想法。
添加更多的数据 – 当然,这是深度学习模型的通常趋向。您为模型提供的数据越多,表现就越好。您可以将此资源用于其他图像描述数据集 – http://www.cs.toronto.edu/~fidler/slides/2017/CSC2539/Kaustav_slides.pdf
使用Attention模型 – 正如我们在本文中所看到的 (深度学习要点 - 使用Attention进行序列建模),使用注意力模型可以帮助我们微调模型性能。
继续研究更大更好的技术 - 研究人员正在研究一些技术 - 例如 使用 强化学习来构建端到端深度学习系统,或者使用新颖的视觉哨兵注意模型。
结尾说明
在本文中,我介绍了Image Captioning,这是一个多模式任务,它构成了对自然语句中的图像进行解密和描述。 然后我解释了解决任务的方法,并详细介绍了它的实现。 除此之外,我还列出了可用于改善模型性能的方法列表。
我希望本文能激励您发现更多可以通过深度学习解决的任务,以便在行业中实现越来越多的突破和创新。 如果您有任何建议/反馈,请在下面的评论中告诉我们!
想要继续查看该篇文章更多代码、链接和参考文献?
戳链接:
http://www.gair.link/page/TextTranslation/944
AI研习社每日更新精彩内容,点击文末【阅读原文】即可观看更多精彩内容:
如何基于 Keras, Python,以及深度学习进行多 GPU 训练
7月最好的机器学习GitHub存储库和Reddit线程
告别选择困难症,我来带你剖析这些深度学习框架基本原理
学 AI 和机器学习的人必须关注的 6 个领域
等你来译:
CMU 答疑贴 | dim agrument for nn.LogSoftMax()
CMU L2 答疑贴 | Choosing a number of layers and neurons
CMU L2 答疑贴 | Universal Boolean Function + DNF Question
CMU L1 答疑贴 | NOT Y boolean example with X,Y boolean input
为什么现在人工智能掀起热潮?
基于机器学习算法的室内运动时间序列分类





