

论文题目**:**Continual Multimodal Knowledge Graph Construction **本文作者:**陈想(浙江大学)、张锦添(浙江大学)、王潇寒(浙江大学)、张宁豫(浙江大学)、吴桐桐(蒙纳士大学)、王宇翔(杭州电子科技大学)、王永恒(之江实验室)、陈华钧(浙江大学)
**发表会议:**IJCAI 2024 论文链接:https://arxiv.org/abs/2305.08698 代码链接:https://github.com/zjunlp/ContinueMKGC
欢迎转载,转载请注明出处****
一、引言
多模态知识图谱构建(MKGC)利用多模态数据作为额外的信息源以增强图谱的构建过程,具体包含多模态命名实体识别(MNER)和多模态关系抽取(MRE)等任务。然而,现有的MKGC架构主要关注“静态”知识图谱,其中实体类别和关系在整个学习过程中保持不变。当面对新的实体类别和关系时,这些模型缺乏适应性。为了应对实体类别和关系不断涌现的动态数据流,目前很多工作聚焦于持续知识图谱补全方法,试图在整合新的实体类别和关系(可塑性)与保留已建立的知识(稳定性)之间取得平衡。
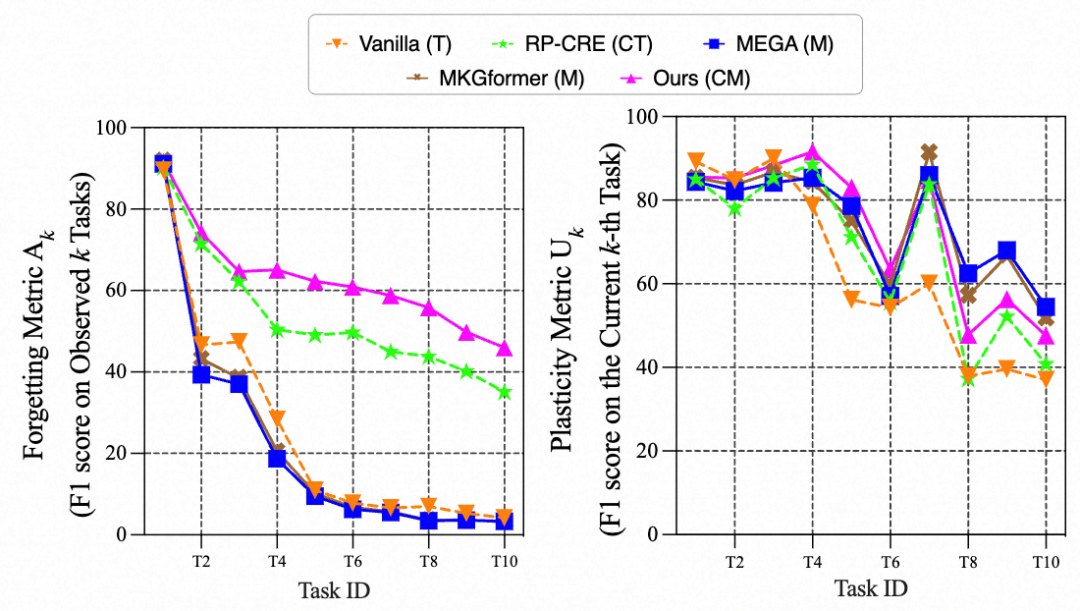
尽管当前的持续知识图谱构建策略主要以文本为中心,忽略了MKGC的需求,但后者处理多模态数据的能力可以提供比纯文本模型更丰富的线索。然而,当直接将MKGC模型转移到持续学习环境中时,上图中的初步实验结果揭示MKGC模型在持续学习过程中不仅在先前任务中不如单模态模型,而且在当前任务测试集上的效果也弱于单模态模型。本文认为,MKGC模型在持续学习中的表现下降可能源于不同模态之间差异较大的收敛速率,从而导致了持续MKGC任务面临两个主要挑战:(1)如何缓解跨模态的不平衡学习动态以增强可塑性?(2)如何有效利用多模态信号来实现跨任务的知识保留,从而提高稳定性? 针对持续MKGC中的挑战,本研究首先引入了持续多模态知识图谱构建的相关基准,旨在推动该领域的发展。本文进一步提出多模态稳定-可塑Transformer(MSPT)框架,具体包含用于平衡学习的梯度调节和具有注意力蒸馏的多模态交互这两个关键模块。本文的研究结果证实了MSPT在演变的知识环境下的优异表现,展示了其在稳定性和可塑性之间实现平衡的能力。
二、方法
针对持续MKGC中的挑战,我们提出了多模态稳定-可塑Transformer(MSPT)。如图2所示,MSPT由两个关键模块组成,分别是基于梯度调节以平衡多模态学习动力和基于注意力蒸馏的多模态交互。 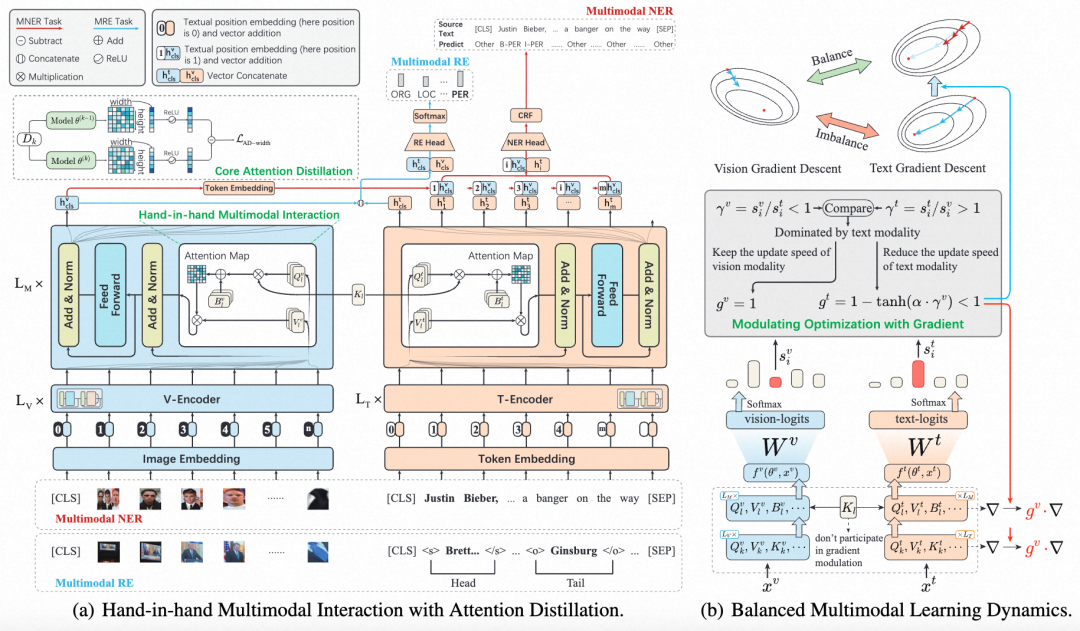
基于梯度调节优化以平衡多模态学习动力
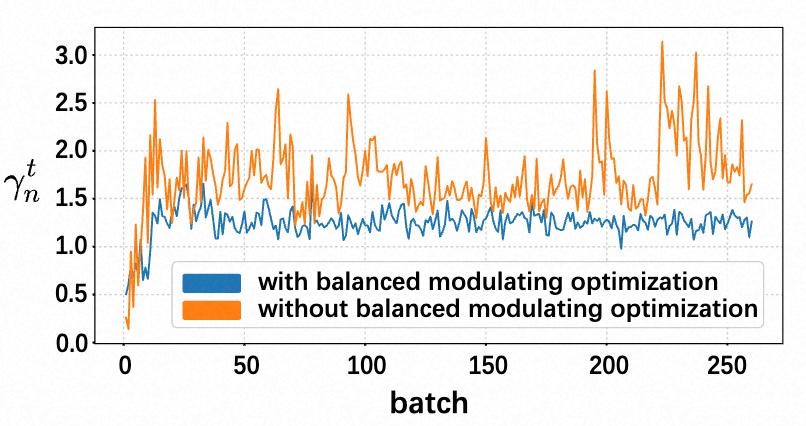
为了应对多模态学习动力的不平衡问题,本文引入一种针对视觉和文本模态的自适应梯度调节机制。如图(b)所示,该机制基于量化每个模态对学习目标的贡献率 来实现: 为了动态评估文本模态和视觉模态之间的贡献率 ,本文引入一个调节系数 来自适应地调节梯度,其定义如下: 其中,是一个超参数,用于调节调制的影响程度。 是在任务 训练后得到的模型的平均调制系数。本文进一步提出通过将系数 整合到任务的第次迭代的SGD优化过程来平衡多模态学习节奏: 通过在任务1中进行梯度调制,并使用前个任务的平均系数来影响当前第个任务的训练,实现了在跨任务的平衡的多模态学习中实现更平稳的过渡。
基于注意力蒸馏的多模态交互
受到"携手并进,不让任何人掉队"这一协同进步理念的启发,本文提出一种通过将双流Transformer与注意力蒸馏相结合,建立持续学习的一致性框架。如图2(a)所示,本文提出的多模态交互引入了一种独特的注意力生成过程,使用共享的可学习键()和相应的自查询,以增强知识的巩固和保留。具体而言,本文引入了一个共享的外部键,取代了原始的Self-Key,为两种模态生成更新的注意力图。对于第个任务,利用ViT和BERT模型将第层的预缩放注意力矩阵表示为,softmax激活之前的SAM输出表示为。 其中表示编码器的总层数,和分别作为视觉和文本注意力图的偏置项。请注意,外部键不受当前特征输入的限制,允许进行端到端优化和整合先前的知识。 此外,本文提出的注意力蒸馏框架引通过利用可学习的共享键的蒸馏函数来稳定注意力图,以减缓在获取新任务期间信息退化。考虑到连续步骤和之间视觉侧 的注意力图,量化了宽度维度上的蒸馏损失:, 其中和表示注意力图的高度和宽度。表示沿或维度的注意力图和之间的总距离。常见的对称距离往往同等地惩罚来自新旧任务的注意力转移,当保留先前任务的注意力时,可能会增加损失从而阻碍学习。虽然保留过去任务的知识可以减轻遗忘,但过度惩罚可能会无意中抑制新获得的见解。为此本文提出了,一种非对称距离度量,在保留先前知识的同时维持模型的适应性: 本文采用非对称距离函数,并在后续实验中将ReLU集成为,注意力蒸馏损失为:
这种设置允许在第个任务期间开发新的注意力模式而不受惩罚,而当前任务中缺失但在第个任务中存在的注意力会受到惩罚,从而促进有针对性的知识保留。
三、实验结果
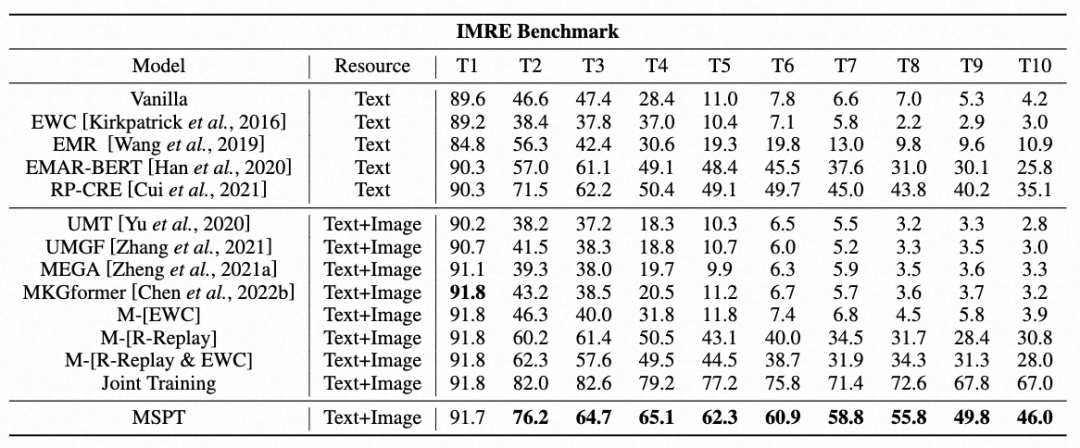
基于IMRE基准测试的实验结果表明:(1) 使用新样本微调单模态BERT(Vanilla方法)会导致性能下降,而多模态模型本应优于Vanilla却产生了较差的结果,这凸显了在持续多模态学习中进行研究的必要性。(2)虽然其他持续学习方法利用记忆模块和采样策略来减少遗忘,但MSPT仍然优于现有的MKGC模型和持续学习方法,突显MSPT在有效利用多模态交互方面的优势。
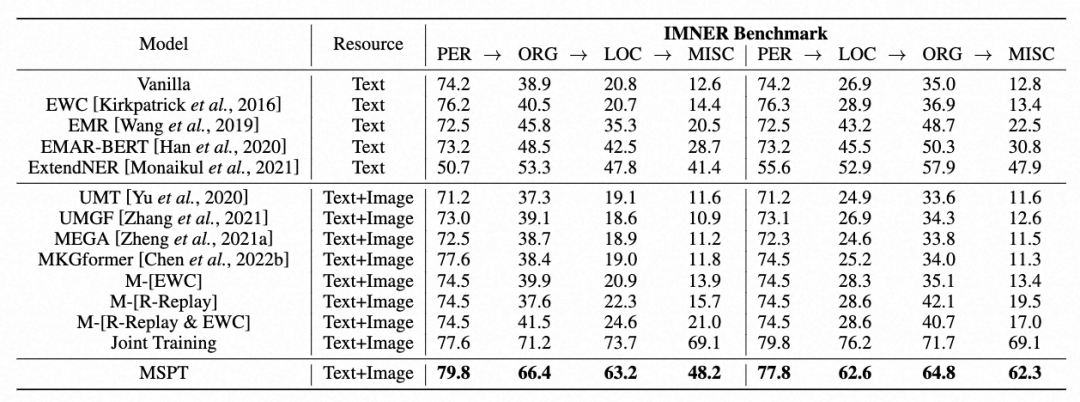
针对持续多模态实体识别,本文在两个任务顺序下全面比较了MSPT与基线方法。如上所示:(1)MSPT在IMNER基准测试中显著优于基线方法,展现出其稳健性和克服先前MKGC方法在连续设置下局限性的能力。(1)为测试MSPT的稳健性和顺序无关性,本文在两种实体类型排列上对其进行评估。结果表明MSPT在不同排列中始终优于基线,显示其不受特定顺序的限制,能够有效地泛化。
四、分析
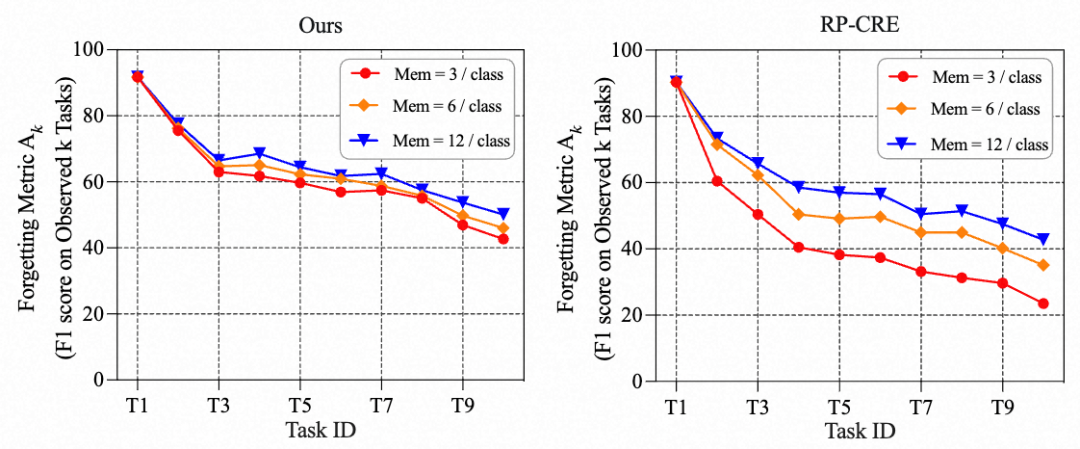

五、结论与展望
本文针对持续多模态知识图谱构建中的挑战,提出了一种多模态稳定-可塑Transformer(MSPT)结构。MSPT通过结合了梯度调节和注意力蒸馏约束的多模态交互机制,在可塑性和稳定性之间取得了较好的平衡。在两个公共基准数据集的持续学习设定上的实验表明,MSPT在持续MKGC任务上优于最新方法。未来,本文将继续探索基于大模型的的持续多模态知识图谱构建。大模型凭借其海量的参数量和强大的表征能力,为多模态知识图谱构建带来了新的机遇和挑战,例如:探索如何利用大模型的预训练机制,更好地捕捉多模态数据之间的内在联系,并将其迁移至持续学习设置;探索大模型在推理阶段的知识蒸馏和模型压缩技术,以实现高效的多模态知识图谱构建和应用等等。
