

**论文题目:**Knowledge-aware Reinforced Language Models for Protein Directed Evolution **本文作者:**王钰皓(浙江大学)、张强(浙江大学)、秦铭(浙江大学)、庄祥(浙江大学)、李晓彤(浙江大学)、宫志晨(浙江大学)、王泽元(浙江大学)、赵宇(腾讯)、姚建华(腾讯)、丁科炎(浙江大学)、陈华钧(浙江大学)
**发表会议:**ICML 2024
论文链接:https://openreview.net/forum?id=MikandLqtW
代码链接:https://github.com/HICAI-ZJU/KnowRLM 欢迎转载,转载请注明出处

一、引言
定向进化是蛋白质优化的基石,是利用自然突变过程来增强蛋白质功能。现有的机器学习辅助定向进化(MLDE)方法通常依赖于数据驱动的策略,经常忽略生化领域的深刻领域知识。在本文中,我们为 MLDE 引入了一种新的知识感知强化语言模型 (KnowRLM)。构建氨基酸知识图(AAKG)来表示氨基酸之间复杂的生化关系。我们进一步提出了一种基于蛋白质语言模型 (PLM) 的策略网络,该网络通过使用动态滑动窗口机制在 AAKG 上优先随机游走迭代地对突变体进行采样。对新的突变体进行主动采样,以微调适应度预测器作为奖励模型,为知识感知策略提供反馈。最后,我们以主动学习方法优化整个系统,该方法模拟实践中的生物设置。KnowRLM 的优势在于它能够利用来自知识图谱的上下文氨基酸信息,从而从蛋白质序列的统计模式和氨基酸的生化特性中获得优势。大量实验表明,与现有方法相比,KnowRLM 在更有效地识别高适应度突变体方面的优越性能。
二、方法
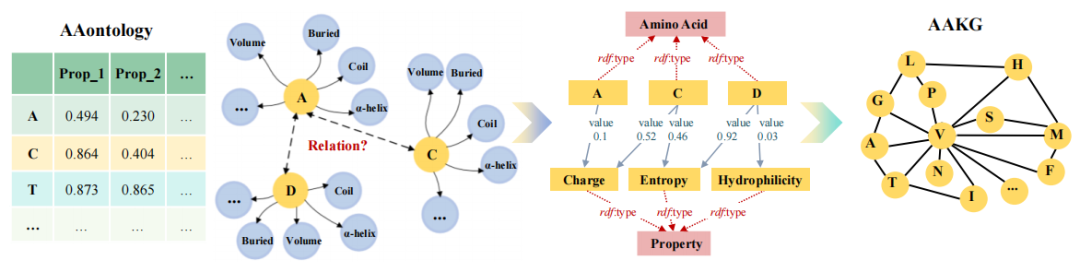
首先,我们根据氨基酸的性质构建了氨基酸的知识图,捕获了氨基酸之间复杂和相互关联的关系。在此基础上,我们提出了一种知识感知策略,通过AAKG上的优先随机游走来预测突变位点和类型。最后,奖励模型(即突变体的适应度预测器)提供了对 KAP 的反馈。我们以主动学习的方式优化 KnowRLM,识别的突变体由预言机注释并用于微调适应度预测器。 现有的知识源要么不包含氨基酸级别的信息,要么缺乏结构化关系。为了填补这一空白,我们构建了一个以氨基酸为中心的知识图谱(AAKG)。具体来说,基于 AAontology,我们确定了每个氨基酸的各种属性来构建 AAKG,包括两个级别:实例和类,分别为黄色和红色。在类级别,我们描述了氨基酸类。为了伪造氨基内酸连接,我们选择在类级别对属性进行建模。在实例级,20个氨基酸被实例化为氨基酸类的实体,而氨基酸的各种物理化学性质,如极性和体积,被实例化为属性类的实体。不同的氨基酸实体可以通过属性实体建立间接关系。实体通过 rdf :type 分配给它们各自的类,用红色虚线箭头表示。此外,如蓝色箭头所示,我们通过对象属性建立实体间关系,表示与氨基酸性质相关的特定数值。图 1 说明了 AAKG 的构建过程。
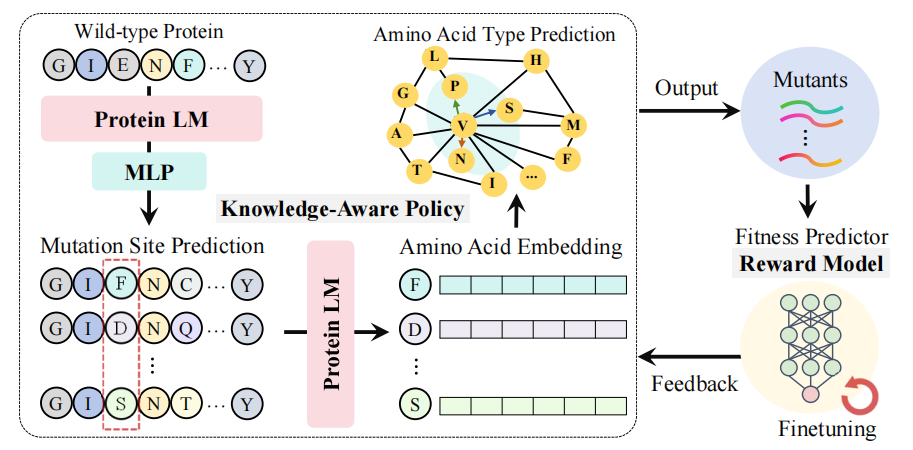
知识感知策略旨在对适应度最高的最优突变体进行采样,这是通过使用 PLM 和 AAKG 预测突变位点和突变氨基酸类型来实现的,如图 2 所示。在突变位点预测模块,给定一个类似于 EvoPlay 的野生型蛋白质序列,在每个时间步 t,我们进行单点突变。我们首先使用 PLM 和多层感知 (MLP) 来预测 n 个候选位点最可能的突变位点。在氨基酸类型预测模块,在确定突变位点 后,我们考虑适当的氨基酸突变体。氨基酸突变的过程被概念化为在AAKG上从一个氨基酸节点导航到另一个氨基酸节点,为了将PLM中的统计规律与AAKG中的理化性质对齐,我们利用PLM中的位置敏感氨基酸嵌入作为AAKG中的节点嵌入。识别氨基酸的突变类型是通过在AAKG中从一个氨基酸节点导航到另一个氨基酸节点来实现的。传统的能够寻路随机游走算法忽略了先验知识信息。因此,我们引入了一种优先随机游走策略。为了测量从一个节点到相邻节点的转移概率,我们使用两个节点之间的嵌入之间的余弦相似度。我们的策略是在AAKG指定的氨基酸的邻域中找到新的替换。
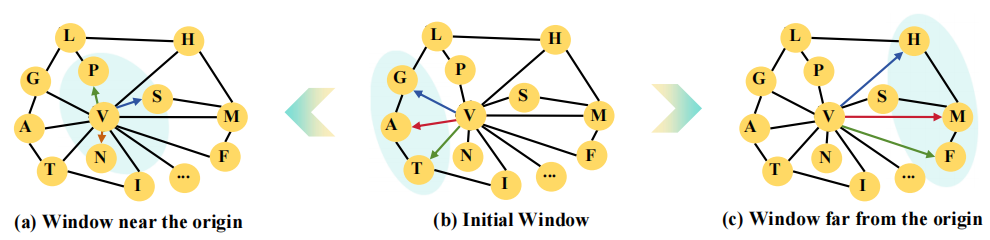
在突变过程的背景下,倾向于对具有相似性质的氨基酸进行突变,这可能导致收敛到局部最优。为了抵消这一点并鼓励 RL 探索,我们在优先随机游走策略中引入了动态滑动窗口机制,如图 3 所示。该算法作为优先随机游走的细微补充,便于更广泛地研究蛋白质空间。初始窗口位于 (b) 中,节点 V 是最初的氨基酸。当突变导致适应度增加时,窗口会滑动到原点,如 (a) 所示,从而能够探索具有相似属性的氨基酸。然而,如果连续的突变不能增加适应度,窗口将从原点滑动,如 (c) 所示。这允许策略网络探索具有不同属性的氨基酸,从而增强发现全局最优解的潜力。
策略优化过程涉及迭代地调整策略网络参数以最大化累积奖励。值得注意的是,奖励函数由适应度预测器实现,该预测器提供了对突变体适应度的伪评估。这个过程在将模型的输出与有向进化任务的特定目标对齐中起着至关重要的作用,确保每个连续迭代产生一个更符合所需特征的蛋白质序列。奖励函数(即适应度预测器 F)在主动学习框架内进行了微调。这种方法通过策略网络迭代地对蛋白质序列进行采样,然后通过预言机注释这些样本的适应度。每一轮采样和注释都有助于用于训练适应度预测器的累积数据集。因此,它的特点是采样、注释和训练的连续循环,允许模型逐步细化其预测能力。
三、实验
我们的研究使用了两个广泛认可的公共数据集 GB1和 PhoQ,以评估所提出的 KnowRLM 方法的有效性。GB1 数据集代表了蛋白质 G 的域 B1,这是众多生物过程的关键组成部分。它包括一个包含149,361个注释突变体的综合阵列,来源于一个可能的160,000个组合,集中在四个关键的突变位点:V39、D40、G41和V54。与 GB1 互补,PhoQ 数据集专注于不同的蛋白质,在四个突变位点具有 160,000 个潜在突变体中的 140,517 个带注释的数据点:A284、V285、S288 和 T289。该数据集中的适应度值表明各种 PhoQ 突变体的磷酸酶或激酶活性。
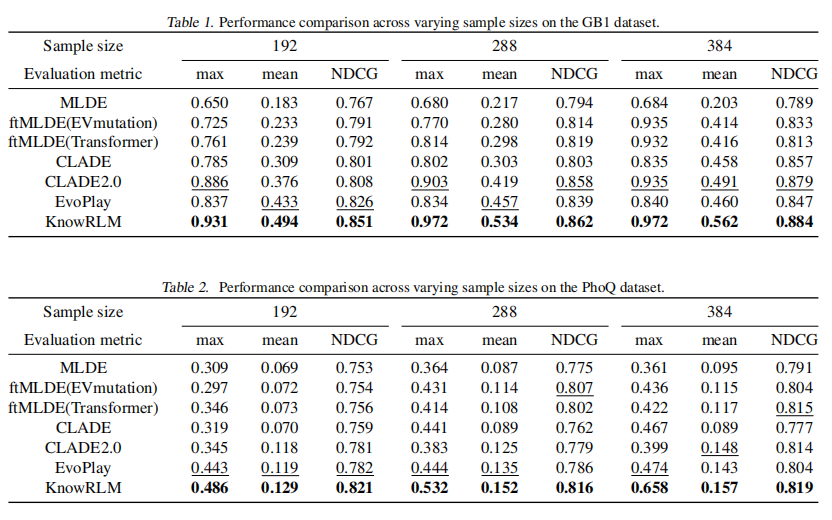
本研究对 MLDE 方法的评估采用多方面的方法来确保对模型性能进行全面评估。归一化折扣累积增益 (NDCG)由于其在排名相关问题中的相关性而成为主要指标,NDCG 评估突变体的预测和实际适应度值之间的相关性。除了 NDCG 之外,评估模型的有效性涉及分析组合集的均值和最大适应度值,其中包括采样过程生成的样本和预测阶段识别的排名靠前的突变体。这些指标共同提供了对模型能力的全面看法,不仅包括它能够识别最高适应度突变体(最大值),还包括考虑的整个突变体集的整体适应度水平(平均值)。我们对我们的方法相对于五种复杂的基线方法进行了广泛的比较分析,包括 MLDE、ftMLDE、CLADE、CLADE2.0和 EvoPlay。
