

**论文题目:**Unified Hallucination Detection for Multimodal Large Language Models 本文作者:陈想(浙江大学)、王晨曦(浙江大学)、薛逸达(浙江大学)、张宁豫(浙江大学)、杨晓燕(蚂蚁集团)、李强(蚂蚁集团)、申月(蚂蚁集团)、梁磊(蚂蚁集团)、顾进捷(蚂蚁集团)、陈华钧(浙江大学)
**发表会议:**ACL 2024 **论文链接:**https://arxiv.org/abs/2402.03190 ****代码链接:https://github.com/zjunlp/EasyDetect 欢迎转载,转载请注明出处

**一、**引言
在人工智能领域,多模态大语言模型(MLLMs)已经取得了突破性进展。它们展现出了在多种任务中接近人类认知和学习能力的表现,为人工通用智能(AGI)的未来带来了前所未有的可能性。然而,尽管MLLMs在处理复杂任务时表现出色,它们仍然容易产生一种被称为“幻觉”的现象。这种现象指的是模型生成的内容虽然看似可信,但实际上与输入数据或已知世界知识相矛盾。幻觉不仅妨碍了MLLMs的实际部署,还可能导致错误信息的传播,影响其可靠性和安全性。因此,开发出能够检测MLLMs响应中多模态幻觉的检测器迫在眉睫,以便向用户警示潜在风险,并推动更可靠的MLLMs的发展。然而,现有的研究工作存在诸多局限性,例如专注于单一任务、幻觉类别范围有限以及缺乏细粒度的评估,这些限制阻碍了多模态幻觉检测技术的快速发展。如图1所示,本文提出了一个关键问题:能否开发出一种统一的视角来检测MLLMs中的幻觉?为了应对这一挑战,本文提出了一个工具增强的统一多模态幻觉检测框架——UNIHD。该框架通过一系列辅助工具来验证幻觉的发生,并提出了一个新的多模态基准测试——MHaluBench,用于评估幻觉检测方法的有效性。通过详尽的评估和全面的分析,展示了UNIHD的有效性,并提供了针对不同幻觉类别应用特定工具的见解。 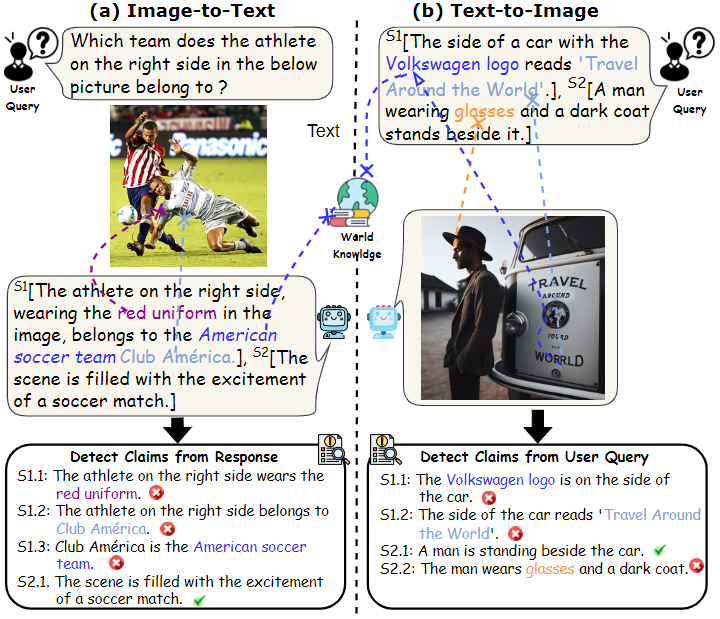
**二、**探索多模态大语言模型幻觉问题的统一视角
本文探讨了多模态大语言模型(MLLMs)中幻觉现象的统一视角,并致力于开发一个统一的检测框架。
多模态幻觉检测的统一视角
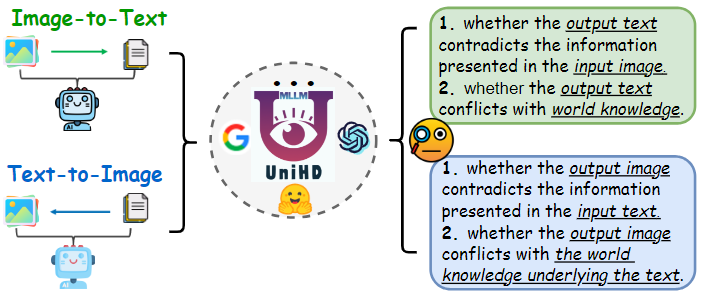
要实现统一的幻觉检测,首先需要对MLLMs中的主要幻觉类别进行一致的分类。如图2所示,本文从统一的视角对以下幻觉分类进行了初步探讨:
- 模态冲突幻觉:MLLMs有时会生成与其他模态输入冲突的输出,导致出现诸如错误的物体、属性或场景文本等问题。例如,在图1(a)中,一个MLLM错误地描述了一名运动员的制服颜色,这展示了由于MLLMs在实现细粒度文本-图像对齐能力有限而导致的属性级冲突。
- 事实冲突幻觉:MLLMs的输出可能与已建立的事实知识相矛盾。图像到文本的模型可能会生成偏离实际内容的叙述,加入无关的事实,而文本到图像的模型则可能生成与文本提示中的事实知识不符的视觉内容。这些差异突显了MLLMs在保持事实一致性方面的挑战,是该领域的一个重大难题。
统一检测问题的公式化
多模态幻觉的统一检测需要检查每一个图文对 ,其中 代表提供给MLLMs的视觉输入或其生成的视觉输出, 则表示基于 生成的文本响应或用于生成 的文本查询。在此任务中,每个 可能包含多个声明,表示为 。幻觉检测器的目标是评估 中的每个声明,以确定其是“幻觉”还是“非幻觉”,并根据提供的幻觉定义给出判断依据。在这种设置中,来自LLMs的文本幻觉检测是一种特例,其中 为空。 
多模态幻觉检测基准MHaluBench构建
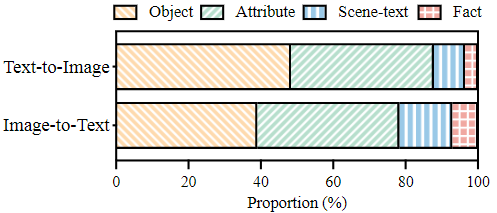
为了推动多模态幻觉检测这一领域的研究,本文引入了评估基准数据集——MHaluBench,该数据集涵盖了图像到文本以及文本到图像生成的内容,旨在严格评估多模态幻觉检测器的进展。本文的数据集经过精心设计,包含了三个关键任务的均衡实例分布,包括200个图像描述(IC)任务示例、200个视觉问答(VQA)任务示例,以及220个文本到图像生成任务示例。表1详细比较了MHaluBench与其他基准数据集的区别,统计细节见图3和图4。 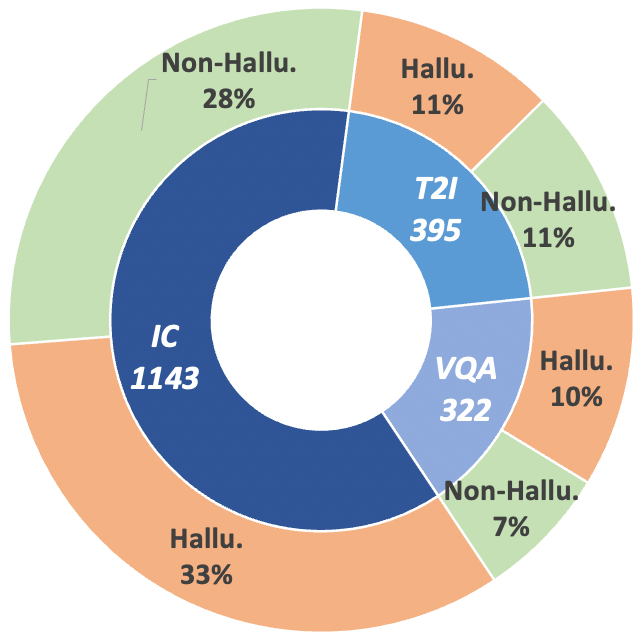
三、UNIHD:多模态幻觉检测框架
在多模态大语言模型(MLLMs)的幻觉检测领域,如图5所示,UNIHD框架凭借其先进的工具和系统化方法,实现了细粒度幻觉的高效识别。
核心声明提取
UNIHD框架的第一步是从生成的响应中提取核心声明,这是识别细粒度幻觉的前提。通过利用MLLMs的高级指令执行能力,可以高效地提取声明,避免了通常需要大量资源进行模型训练的情况。具体而言,GPT-4V和Gemini作为基础语言模型,能够高效地从图像到文本模型的输出中提取每个响应的个别声明,并将文本到图像模型中的用户指令分解为不同的声明。
针对声明的自动化工具选择
在从输入的图文对 中提取核心声明之后,幻觉检测的挑战在于如何将每个声明与合适的面向方面的工具相匹配。我们通过评估底层MLLMs是否能够为给定的一组声明 生成相关的查询,以便为特定的面向方面的工具提供必要的输入来解决这一问题。 为了实现这一目标,我们提示底层MLLMs(如GPT-4V和Gemini)自主生成有意义的查询。如图5所示,该模块为每个声明生成定制查询,如果不需要工具则返回“none”。例如,框架确定声明1需要属性导向的问题“运动员右侧的制服是什么颜色?”和对象导向的查询“[运动员', 制服']”,从而绕过了对场景文本和事实导向工具的需求。通过这种方式,UNIHD框架能够高效地匹配每个声明与适当的工具,确保幻觉检测的准确性和可靠性。 
并行工具执行
在自动生成的不同方面的问题之后,研究者并行实施这些工具,以收集广泛的知识,作为幻觉验证的基础。框架中使用的具体工具包括: 面向对象的工具:使用开放集对象检测模型Grounding DINO捕获视觉对象信息,检测对象级别的幻觉。例如,输入“['运动员', '制服']”会提示模型返回两个制服对象和两个运动员对象,以及它们的归一化位置坐标。面向属性的工具:使用底层MLLMs(如GPT-4V和Gemini)回答特定的属性级别问题,这些响应随后用于幻觉验证,类似于自我反思的方法。面向场景文本的工具:如果生成的场景文本问题不为“无”,则调用MAERec作为场景文本检测工具,识别图像中的场景文本及其对应的归一化四维坐标。面向事实的工具:利用Google Search API从Serper进行基于事实级别问题的互联网搜索,提取并分析顶级搜索结果,并从API的响应中获得各种摘要。 通过部署这套工具,UNIHD框架系统地收集知识作为证据,以可靠地验证不同模态下的幻觉。
带有理由的幻觉验证
在我们流程的最后阶段,我们对每个声明(记为 )进行二元预测,以确定其幻觉状态。声明根据证据支持的程度被分类为Hallucinatory(幻觉的)或Non-hallucinatory(非幻觉的)。为实现这一目标,我们将从工具中收集的证据与原始图像及其相应的声明列表整合成一个综合提示。值得注意的是,与声明列表对应的集合 作为一个批次输入检测器。这种操作允许检测器捕捉上下文信息,同时提高效率。随后,我们指示选择的MLLM(GPT-4V或Gemini)评估每个声明的幻觉潜力。在此过程中,MLLM还生成深入的解释,以阐明其判断背后的理由。通过这种方法,UNIHD框架不仅能够准确地检测出幻觉,还能提供详细的解释,帮助用户理解模型的决策过程。
四、实验结果与分析
实验设置与基线比较
在本研究中,提出了一个新的多模态幻觉检测框架,UNIHD,旨在通过一系列辅助工具来验证多模态大型语言模型(MLLMs)生成内容中的幻觉现象。为了评估UNIHD的有效性,研究者构建了一个元评估基准,MHaluBench,它包含了图像到文本生成(包括图像描述(IC)和视觉问答(VQA))以及文本到图像合成任务的内容。 研究者将UNIHD与两个基线模型进行比较:Self-Check(2-shot)和Self-Check(0-shot),这两个基线模型基于CoT评估底层MLLM识别幻觉的能力,而无需外部知识。在实践中,使用GPT-4V和Gemini来识别细粒度的幻觉并解释其判断背后的推理。
UNIHD在多模态幻觉检测中的表现
在MHaluBench基准测试中的实验结果充分证明了UNIHD框架的有效性。表2中的实验数据显示,UNIHD在图像到文本和文本到图像任务中均显著优于其他基线检测器。特别值得一提的是,UNIHD在图像到文本生成任务中利用GPT-4V展现了卓越的性能,其表现超越了Self-Check(2-shot)模型。这一结果突显了集成外部工具在实现更可靠幻觉检测中的重要性。 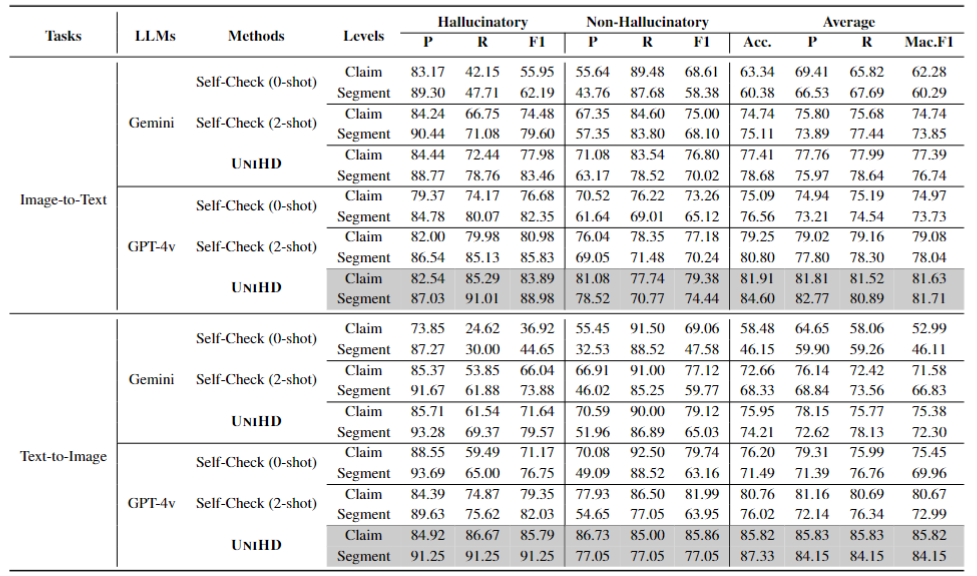
案例分析
**解释的合理性
如图6上半部分所示,UNIHD和Self-Check(2-shot)能够准确识别事实层面的幻觉(如“Fanta 源自二战期间的美国”)和对象层面的幻觉(如“三辆自行车停放在那儿”)。比较分析显示,UNIHD在综合证据方面表现卓越,能够提供更可信和更有说服力的解释。

图6. 案例分析
**失败案例分析
如图6下半部分所示,我们展示了两种UNIHD存在局限性的情况。左侧的案例表明该工具可能会生成错误的证据或无法提供有用的信息,导致多模态大语言模型(MLLM)做出错误判断。右侧的案例显示,即使MLLM收到准确的证据,它仍可能保持初始偏见,导致错误决策。 
探索UNIHD评估现代多模态大语言模型的幻觉现象
我们使用由GPT-4V驱动的UNIHD作为金标准检测器,评估包括GPT-4V和Gemini在内的多模态大语言模型(MLLMs)中的幻觉频率。图7中的研究结果表明:(1) 在大多数测试条件下,GPT-4V的声明级别幻觉率最低;(2) 这些MLLMs的幻觉排名与既有排行榜和人工评估结果基本一致。这些发现展示了UNIHD在评估幻觉现象方面的潜力。
五、总结
本文提出了一个统一的问题框架,用于检测多模态大型语言模型(MLLMs)中的幻觉现象。为推动这一具有挑战性的研究方向,我们构建了一个精细化的基准数据集——MHaluBench。此外,我们还开发了一个名为UNIHD的统一幻觉检测框架。UNIHD 能够自主选择外部工具,捕获相关知识以支持幻觉验证,并提供合理的解释。实验结果显示,UNIHD在图像到文本和文本到图像的生成任务中均表现出卓越的性能,证实了其通用性和有效性。