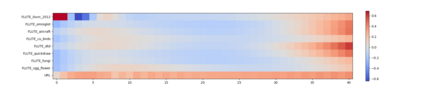
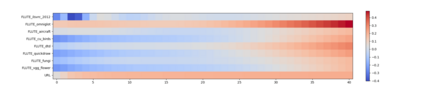
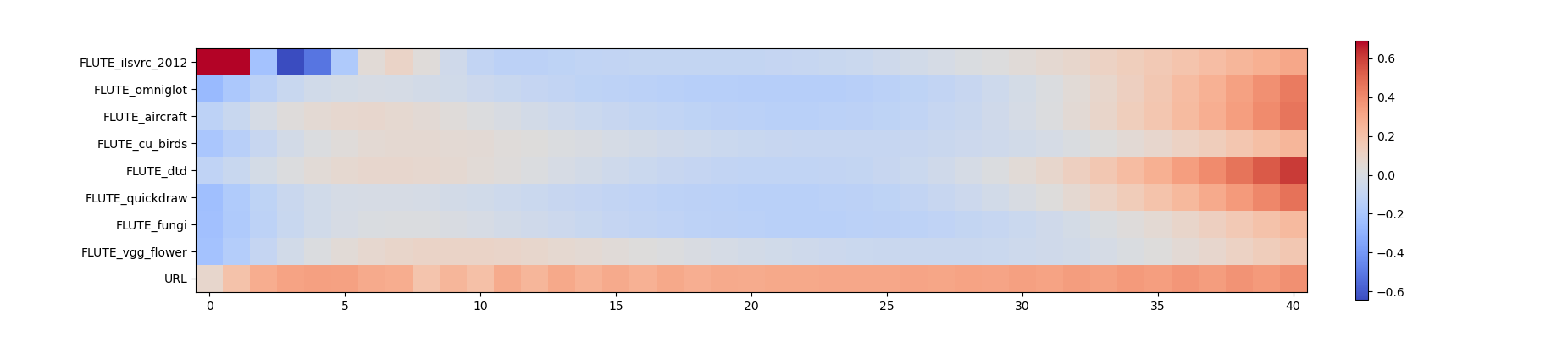
Cross-domain few-shot meta-learning (CDFSML) addresses learning problems where knowledge needs to be transferred from several source domains into an instance-scarce target domain with an explicitly different input distribution. Recently published CDFSML methods generally construct a "universal model" that combines knowledge of multiple source domains into one backbone feature extractor. This enables efficient inference but necessitates re-computation of the backbone whenever a new source domain is added. Moreover, state-of-the-art methods derive their universal model from a collection of backbones -- normally one for each source domain -- and the backbones may be constrained to have the same architecture as the universal model. We propose a CDFSML method that is inspired by the classic stacking approach to meta learning. It imposes no constraints on the backbones' architecture or feature shape and does not incur the computational overhead of (re-)computing a universal model. Given a target-domain task, it fine-tunes each backbone independently, uses cross-validation to extract meta training data from the task's instance-scarce support set, and learns a simple linear meta classifier from this data. We evaluate our stacking approach on the well-known Meta-Dataset benchmark, targeting image classification with convolutional neural networks, and show that it often yields substantially higher accuracy than competing methods.
翻译:横跨多部元学习(CDFSML) 解决了学习问题,即知识需要从几个源域转移到一个试封目标域,其输入分布明显不同。最近公布的 CDFSML 方法通常会构建一个“通用模型”,将多个源域的知识综合到一个主干特征提取器中。这样可以进行有效的推断,但一旦添加一个新的源域,就必须对主干进行重新计算。此外,最先进的方法从一个主干网库 -- -- 通常是每个源域的一个主干网 -- -- 中得出其通用模型,而主干网可能受限制,无法与通用模型具有相同的结构。我们建议一种由典型的元学习叠叠法启发的 CDFSML 方法。它不会对主干网结构或特征形状施加任何限制,而且不会产生(再)连接一个通用模型的计算间接费用。此外,它每个主干网都独立地进行微调,使用交叉验证来从任务主干网中提取元培训数据,而不能与通用模型支持这一通用模型集一样。 我们用一个简单的直径直径的直径直线化的模型来评估,我们用来显示这个标准的模型。