无监督元学习表示学习
Learning Unsupervised Learning Rules
https://github.com/tensorflow/models/tree/master/research/learning_unsupervised_learning
Abstract
A major goal of unsupervised learning is to discover data representations that are useful for subsequent tasks, without access to supervised labels during training. Typically, this goal is approached by minimizing a surrogate objective, such as the negative log likelihood of a generative model, with the hope that representations useful for subsequent tasks will arise incidentally. In this work, we propose instead to directly target a later desired task by meta-learning an unsupervised learning rule, which leads to representations useful for that task. Here, our desired task (meta-objective) is the performance of the representation on semi-supervised classification, and we meta-learn an algorithm – an unsupervised weight update rule – that produces representations that perform well under this meta-objective. Additionally, we constrain our unsupervised update rule to a be a biologically- motivated, neuron-local function, which enables it to generalize to novel neural network architectures. We show that the meta-learned update rule produces useful features and sometimes outperforms existing unsupervised learning techniques. We further show that the meta-learned unsupervised update rule generalizes to train networks with different widths, depths, and nonlinearities. It also generalizes to train on data with randomly permuted input dimensions and even generalizes from image datasets to a text task.
1
One explanation for this failure is that unsupervised representation learning algorithms are typically mismatched to the target task. Ideally, learned representations should linearly expose high level attributes of data (e.g. object identity) and perform well in semi-supervised settings. Many current unsupervised objectives, however, optimize for objectives such as log-likelihood of a generative model or reconstruction error and produce useful representations only as a side effect.
Unsupervised representation learning seems uniquely suited for meta-learning [1, 2]. Unlike most tasks where meta-learning is applied, unsupervised learning does not define an explicit objective, which makes it impossible to phrase the task as a standard optimization problem. It is possible, however, to directly express a meta-objective that captures the quality of representations produced by an unsupervised update rule by evaluating the usefulness of the representation for candidate tasks, e.g. semi-supervised classification. In this work, we propose to meta-learn an unsupervised update rule by meta-training on a meta-objective that directly optimizes the utility of the unsupervised representation.Unlike hand-designed unsupervised learning rules, this meta-objective directly targets the usefulness of a representation generated from unlabeled data for later supervised tasks.
By recasting unsupervised representation learning as meta-learning, we treat the creation of the unsupervised update rule as a transfer learning problem. Instead of learning transferable features, we learn a transferable learning rule which does not require access to labels and generalizes across both data domains and neural network architectures.
2.1
In contrast to our work, each method imposes a manually defined training algorithm or loss function to optimize whereas we learn the algorithm that creates useful representations as determined by a meta-objective.
To our knowledge, we are the first meta-learning approach to tackle the problem of unsupervised representation learning
we are the first representation meta-learning approach to generalize across input data modalities as well as datasets, the first to generalize across permutation of the input dimensions, and the first to generalize across neural network architectures (e.g. layer width, network depth, activation function).
3
We wish for our update rule to generalize across architectures with different widths, depths, or even network topologies. To achieve this, we design our update rule to be neuron-local, so that updates are a function of pre- and post- synaptic neurons in the base model, and are defined for any base model architecture. This has the added benefit that it makes the weight updates more similar to synaptic updates in biological neurons, which depend almost exclusively on the pre- and post-synaptic neurons for each synapse [48].
4
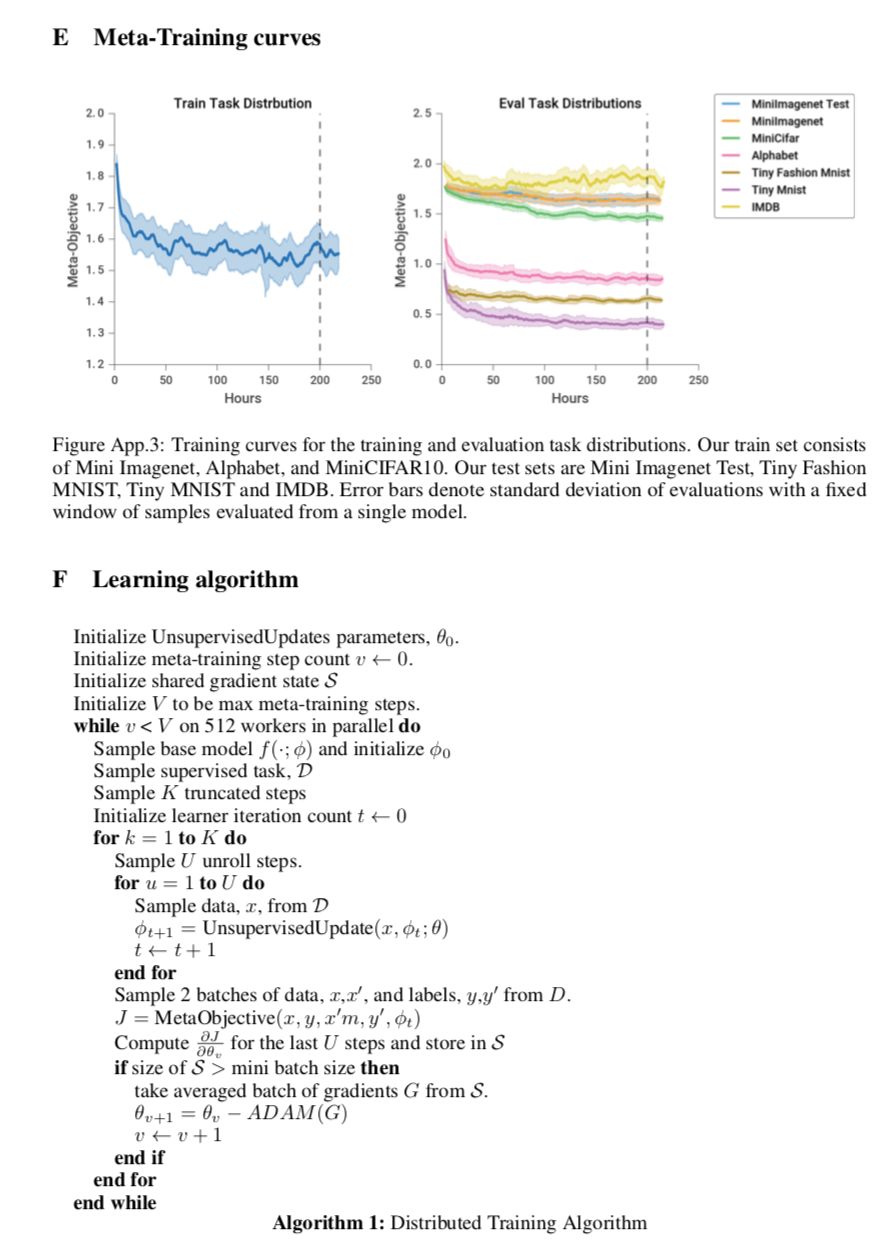
We implement the above models in distributed Tensorflow [55]. Training uses 512 workers, each of which performs a sequence of partial unrolls of the inner loop UnsupervisedUpdate, and computes gradients of the meta-objective asynchronously. Training takes ∼8 days, and consists of ∼200 thousand updates to θ with minibatch size 256. Additional details can be found in Appendix C.
但是第一天下降很快的。






感觉论文有些难。



