Hierarchically Structured Meta-learning
Hierarchically Structured Meta-learning
Huaxiu Yao, Ying Wei, Junzhou Huang, Zhenhui Li
(Submitted on 13 May 2019)
In order to learn quickly with few samples, meta-learning utilizes prior knowledge learned from previous tasks. However, a critical challenge in meta-learning is task uncertainty and heterogeneity, which can not be handled via globally sharing knowledge among tasks. In this paper, based on gradient-based meta-learning, we propose a hierarchically structured meta-learning (HSML) algorithm that explicitly tailors the transferable knowledge to different clusters of tasks. Inspired by the way human beings organize knowledge, we resort to a hierarchical task clustering structure to cluster tasks. As a result, the proposed approach not only addresses the challenge via the knowledge customization to different clusters of tasks, but also preserves knowledge generalization among a cluster of similar tasks. To tackle the changing of task relationship, in addition, we extend the hierarchical structure to a continual learning environment. The experimental results show that our approach can achieve state-of-the-art performance in both toy-regression and few-shot image classification problems.
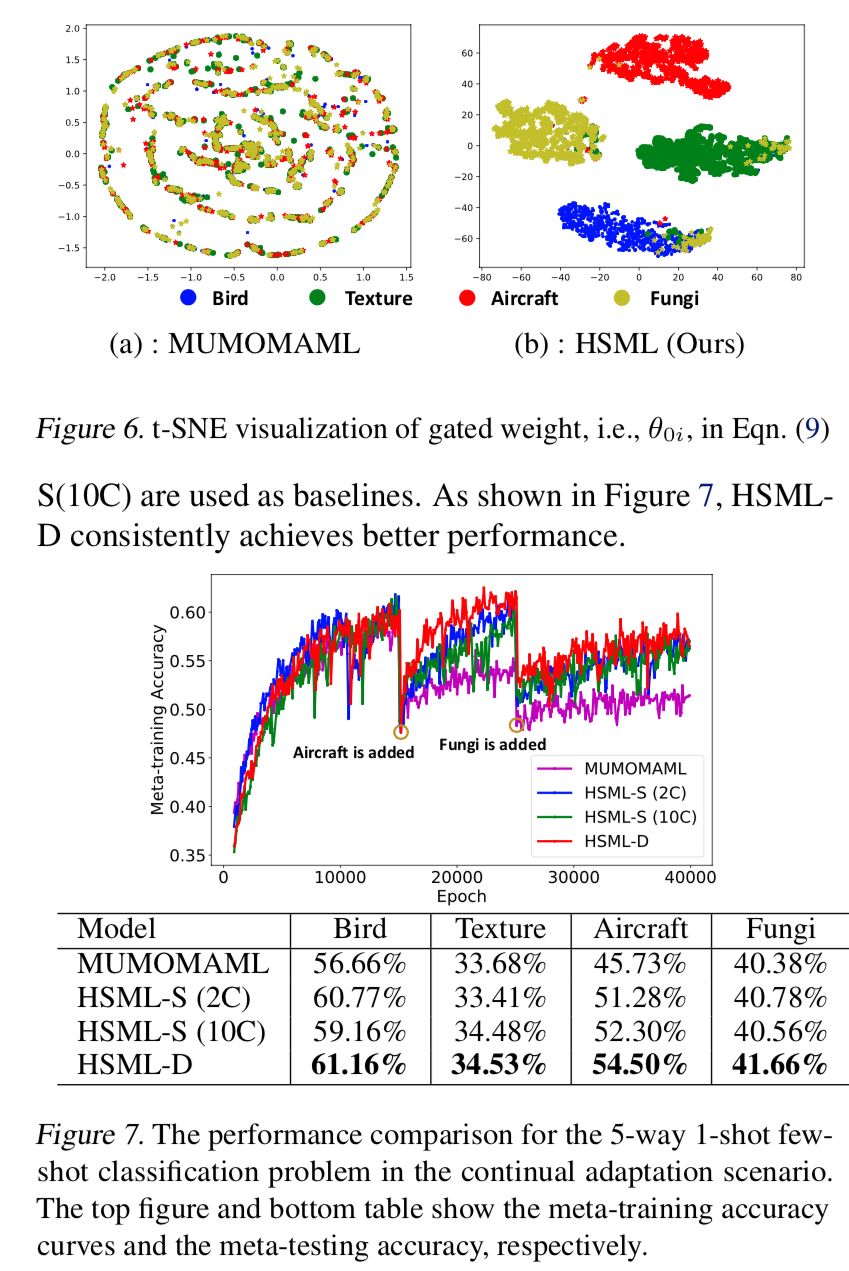
登录查看更多
相关内容

Arxiv
5+阅读 · 2020年4月2日
Arxiv
5+阅读 · 2019年8月27日



相关VIP内容
相关资讯
相关论文
Arxiv
5+阅读 · 2020年4月2日
Arxiv
5+阅读 · 2019年8月27日