

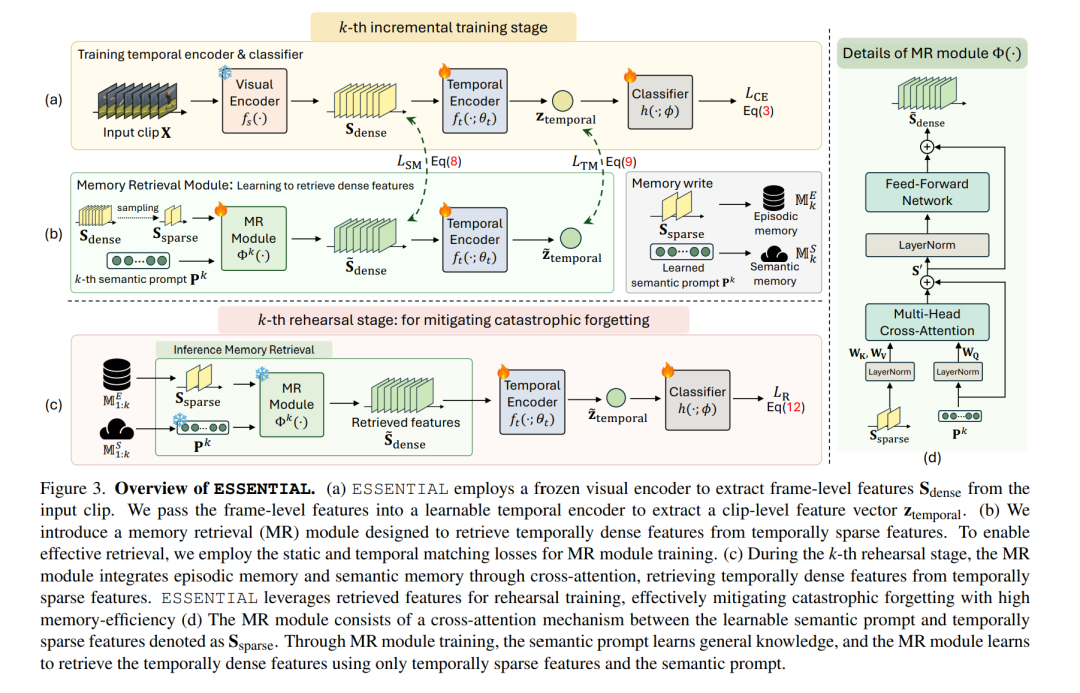
在本研究中,我们解决了视频类增量学习(Video Class-Incremental Learning, VCIL)问题。许多现有的 VCIL 方法通过在情景记忆(episodic memory)中存储少量时间密集的样本,并进行复现训练来缓解灾难性遗忘,但这在内存使用上效率低下。另一类方法则存储时间稀疏的样本,虽然节省了内存,却牺牲了关键的时间信息,从而导致性能下降。 为解决这一内存效率与性能之间的权衡,我们提出了一种新的方法——ESSENTIAL(EpiSodic and SEmaNTIc memory integrAtion for video class-incremental Learning)。ESSENTIAL 包含两部分: * 情景记忆(episodic memory):用于存储时间稀疏的特征; * 语义记忆(semantic memory):通过可学习的提示(learnable prompts)存储一般性知识。
我们进一步提出了一个新颖的记忆检索(Memory Retrieval, MR)模块,通过交叉注意力机制(cross-attention)整合情景记忆和语义提示,使得系统能够从时间稀疏特征中检索出时间密集的特征。 我们在多个数据集上对 ESSENTIAL 进行了严格验证:在 TCD 基准中使用 UCF-101、HMDB51 和 Something-Something-V2,在 vCLIMB 基准中使用 UCF-101、ActivityNet 和 Kinetics-400。值得注意的是,在显著减少内存需求的情况下,ESSENTIAL 在这些基准上依然取得了优异的性能。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
216+阅读 · 2023年4月7日
Arxiv
147+阅读 · 2023年3月29日
相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
216+阅读 · 2023年4月7日
Arxiv
147+阅读 · 2023年3月29日