Unsupervised Learning via Meta-Learning
Unsupervised Learning via Meta-Learning
https://sites.google.com/view/unsupervised-via-meta
Kyle Hsu, Sergey Levine, Chelsea Finn
arXiv preprint
Abstract
A central goal of unsupervised learning is to acquire representations from unlabeled data or experience that can be used for more effective learning of downstream tasks from modest amounts of labeled data. Many prior unsupervised learning works aim to do so by developing proxy objectives based on reconstruction, disentanglement, prediction, and other metrics. Instead, we develop an unsupervised learning method that explicitly optimizes for the ability to learn a variety of tasks from small amounts of data. To do so, we construct tasks from unlabeled data in an automatic way and run meta-learning over the constructed tasks. Surprisingly, we find that, when integrated with meta-learning, relatively simple mechanisms for task design, such as clustering unsupervised representations, lead to good performance on a variety of downstream tasks. Our experiments across four image datasets indicate that our unsupervised meta-learning approach acquires a learning algorithm without any labeled data that is applicable to a wide range of downstream classification tasks, improving upon the representation learned by four prior unsupervised learning methods.
Algorithm
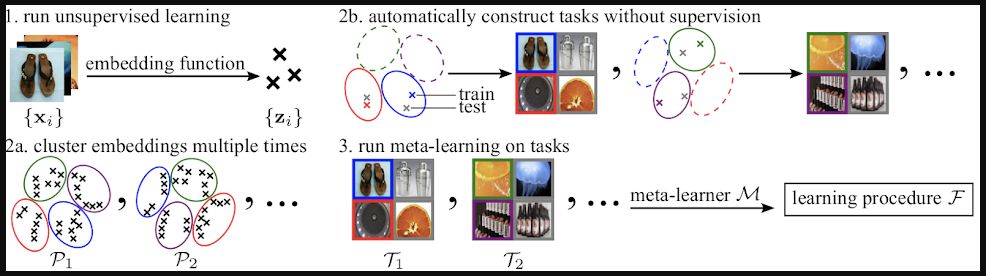
Input: a dataset consisting only of unlabeled images. Output: a learning procedure.
1. We run an out-of-the-box unsupervised learning algorithm to learn an embedding function. We pass each image through this function to obtain its embedding, which can be thought of as a summary of the image.
2. We consider image classification tasks. Each such task consists of some classes, and some examples for each class. We first create multiple sets of pseudo-labels for the images via clustering their embeddings. To construct a task, we sample a set of labels, sample a few clusters, and sample a few embedding points from each cluster. We select the images whose embeddings were sampled. Some of a task's image examples are designated as training examples (colored border), and the rest are treated as testing examples (gray border).
3. The automatically generated tasks are fed into a meta-learning algorithm. For each task, the meta-learning algorithm applies the current form of its eventual output, a learning procedure, to the task's training examples. This results in a classifier that is tailored to the current task. The meta-learning algorithm then assesses its learning procedure by testing how well the classifier does on the task's testing examples. Based on this, it updates its learning procedure.
We call our method Clustering to Automatically Construct Tasks for Unsupervised meta-learning (CACTUs). The key insight which CACTUs relies on is that while the embeddings may not be directly suitable for learning downstream tasks, they can still be leveraged to create structured yet diverse training tasks. We assess performance by deploying the meta-learned learning procedure to new human-specified tasks based on unseen images and classes.Code
For CACTUs code that uses model-agnostic meta-learning (MAML), please see this GitHub repo.
For CACTUs code that uses prototypical networks (ProtoNets), please see this GitHub repo.
Credits
The results in this project leveraged six open-source codebases from six prior works.
We used four unsupervised learning methods for step 1:
"Adversarial Feature Learning": paper, code
"Deep Clustering for Unsupervised Learning of Visual Features": paper, code
"InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets": paper, code
"Understanding and Improving Interpolation in Autoencoders via an Adversarial Regularizer": paper, code
We used two meta-learning methods for step 3:
"Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks": paper, code
"Prototypical Networks for Few-Shot Learning": paper, code




