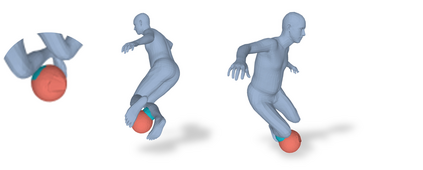
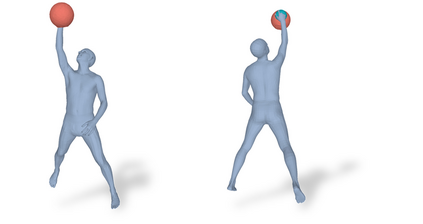
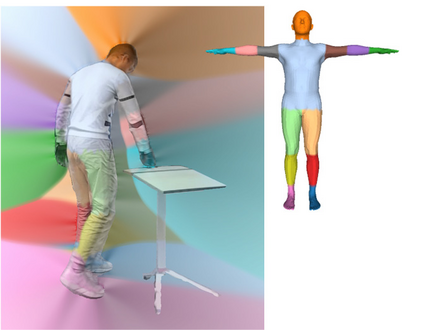
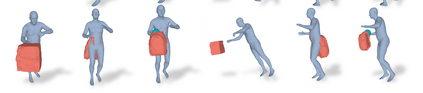
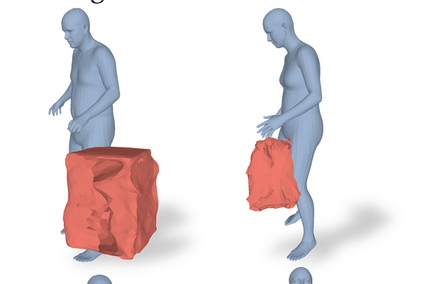
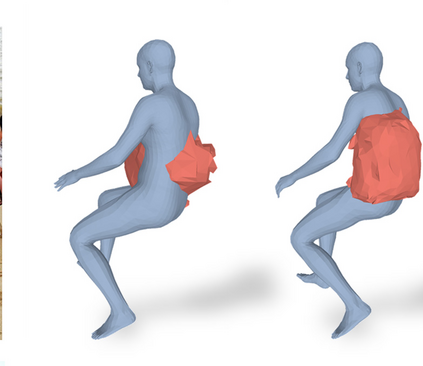
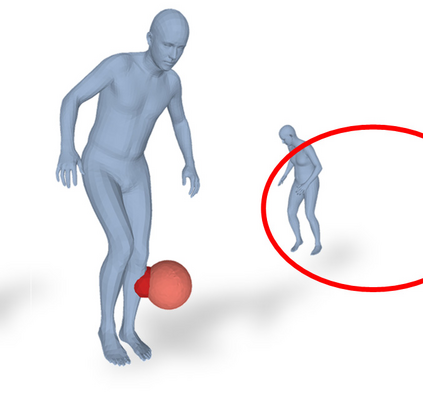
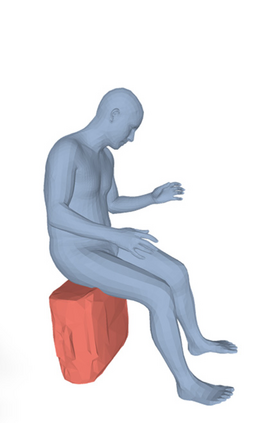
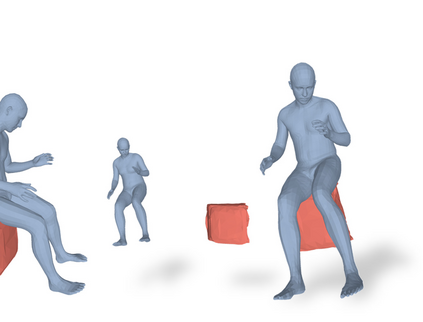
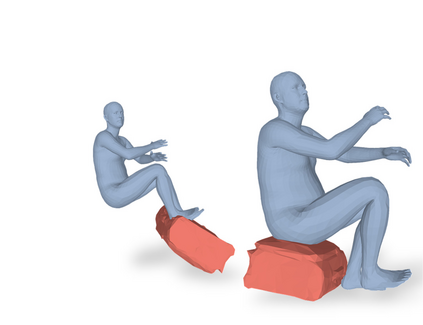
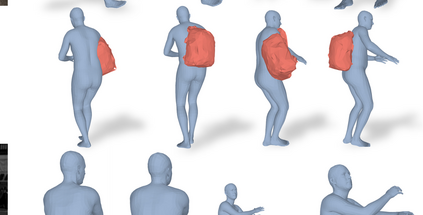
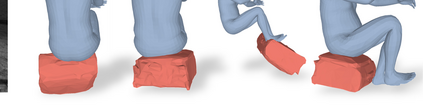
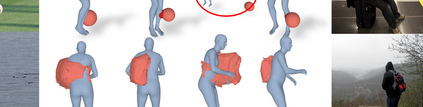
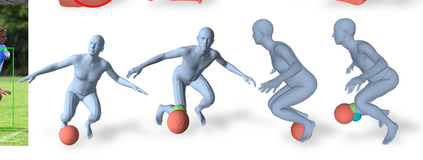
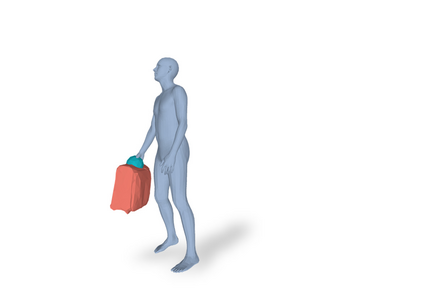
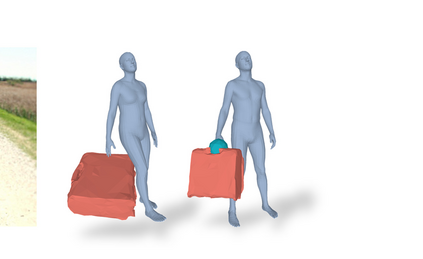
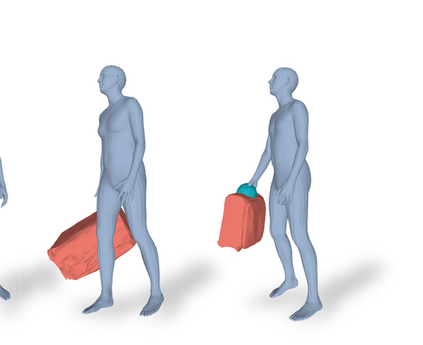
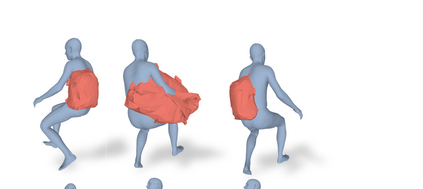
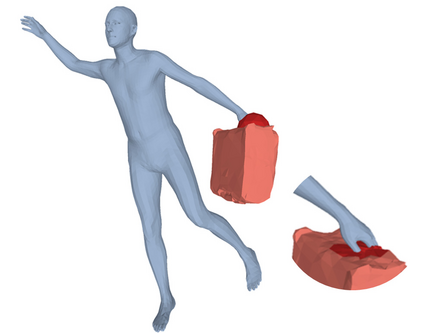
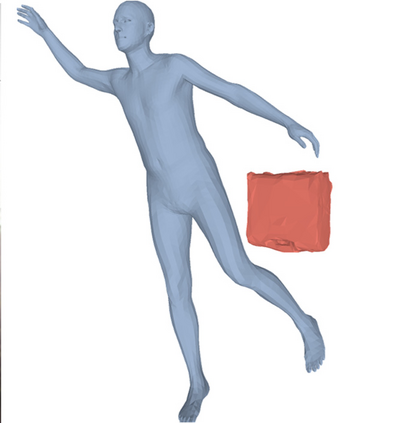
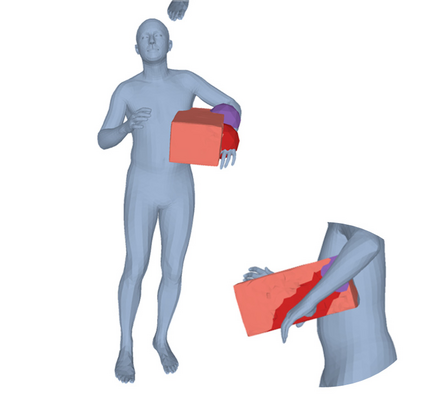
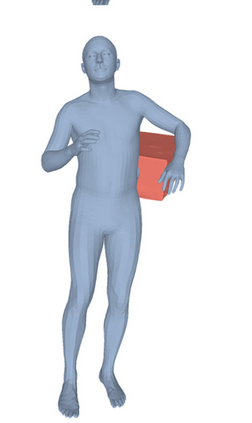
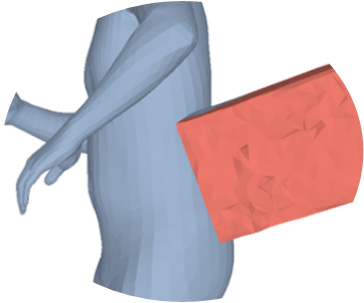
Most prior works in perceiving 3D humans from images reason human in isolation without their surroundings. However, humans are constantly interacting with the surrounding objects, thus calling for models that can reason about not only the human but also the object and their interaction. The problem is extremely challenging due to heavy occlusions between humans and objects, diverse interaction types and depth ambiguity. In this paper, we introduce CHORE, a novel method that learns to jointly reconstruct the human and the object from a single RGB image. CHORE takes inspiration from recent advances in implicit surface learning and classical model-based fitting. We compute a neural reconstruction of human and object represented implicitly with two unsigned distance fields, a correspondence field to a parametric body and an object pose field. This allows us to robustly fit a parametric body model and a 3D object template, while reasoning about interactions. Furthermore, prior pixel-aligned implicit learning methods use synthetic data and make assumptions that are not met in the real data. We propose a elegant depth-aware scaling that allows more efficient shape learning on real data. Experiments show that our joint reconstruction learned with the proposed strategy significantly outperforms the SOTA. Our code and models are available at https://virtualhumans.mpi-inf.mpg.de/chore
翻译:多数先前的工作都是从图像中将3D人从人类与世隔绝而没有周围环境的图像中看待。 然而, 人类不断与周围物体互动, 从而要求使用不仅能解释人类, 也能解释物体及其相互作用的模型。 这个问题由于人与物体之间的严重隔绝、 不同的互动类型和深度模糊性而具有极大的挑战性。 在本文中, 我们引入了CHORE, 这是一种新颖的方法, 学会从单一的 RGB 图像中共同重建人类和对象。 CHORE 吸收了最近隐含的表面学习和经典模型装配的进展的灵感。 我们用两个未指派的距离字段来计算人类和对象的神经重建。 我们的实验显示, 我们共同重建了两个未指派的距离字段, 一个对准体和对象构成的字段。 这使我们能够在解释互动的同时, 强健美的体形体模型和一个3D对象模板。 此外, 先前的隐含学习方法使用合成数据, 并作出在真实数据中无法满足的假设。 我们提议了一个优等深度的深度测量尺度缩缩缩缩缩,, 以便在真实数据上进行更高效的形状的形状的形状学习。 实验显示我们共同的模型是可用的战略。 我们的SOfrpormapormas exformas