
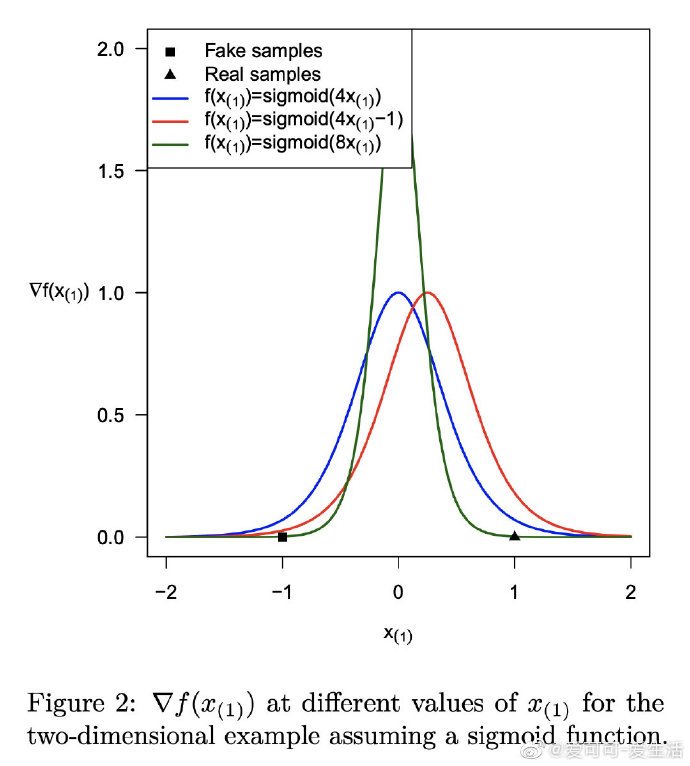
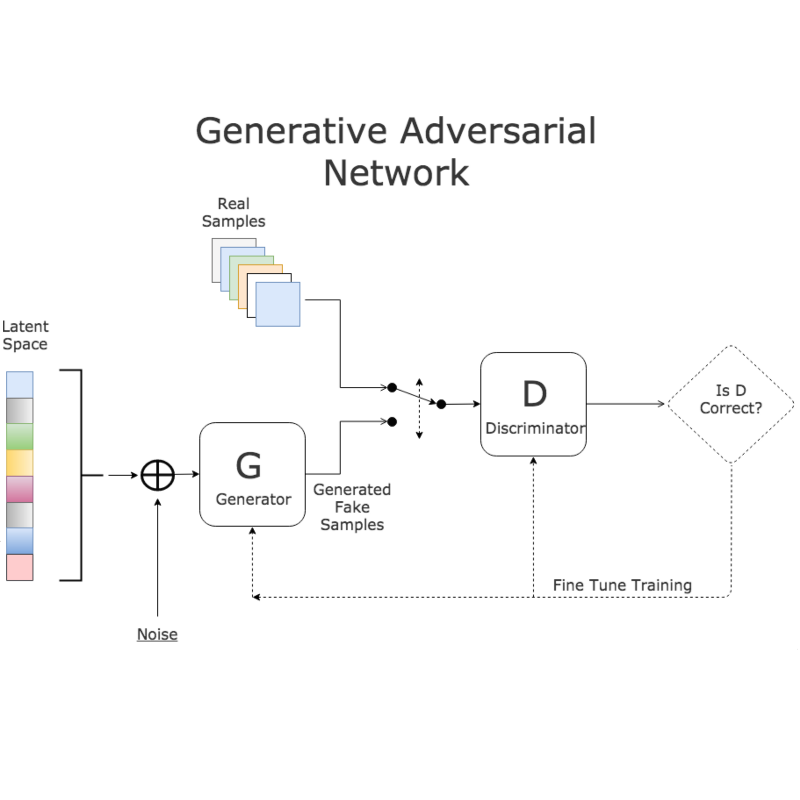
*《Connections between Support Vector Machines, Wasserstein distance and gradient-penalty GANs》A Jolicoeur-Martineau, I Mitliagkas [Mila] (2019)
成为VIP会员查看完整内容


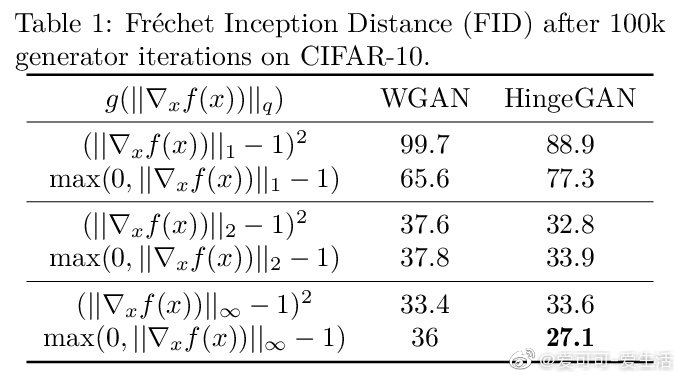
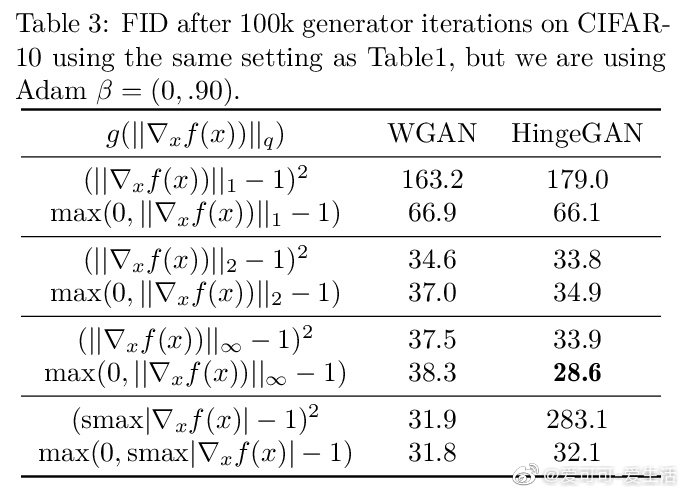

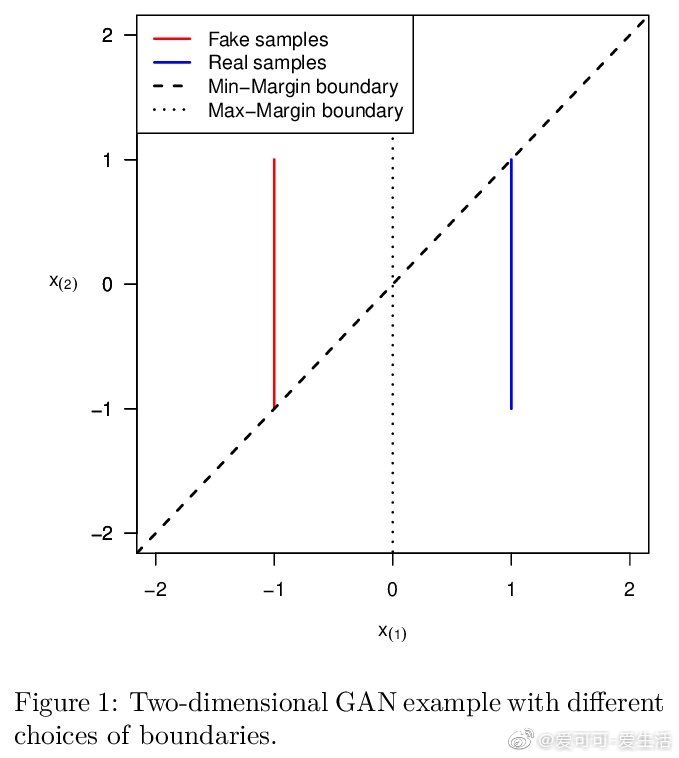
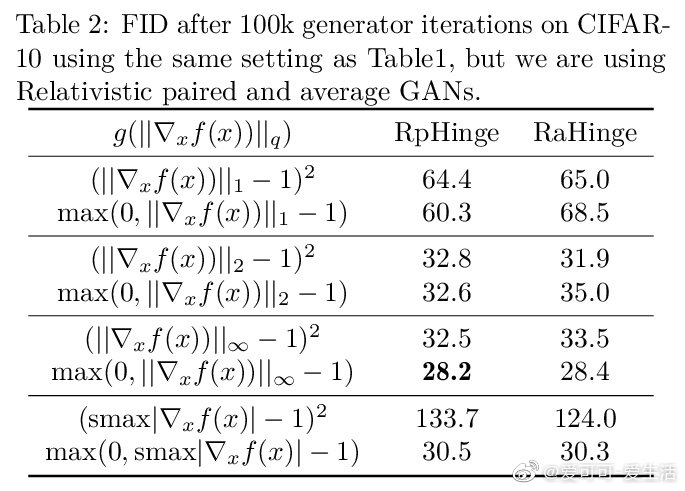
相关内容
专知会员服务
54+阅读 · 2020年3月5日
专知会员服务
32+阅读 · 2019年10月30日
Arxiv
5+阅读 · 2018年12月15日

相关VIP内容
专知会员服务
54+阅读 · 2020年3月5日
专知会员服务
32+阅读 · 2019年10月30日
相关资讯
相关论文
Arxiv
5+阅读 · 2018年12月15日