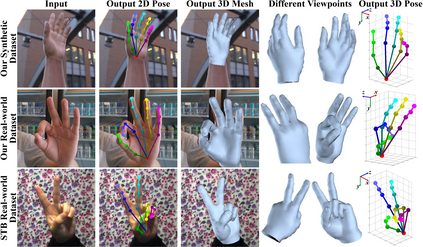
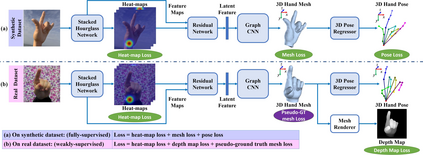
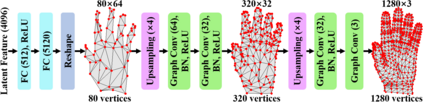
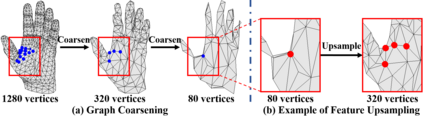
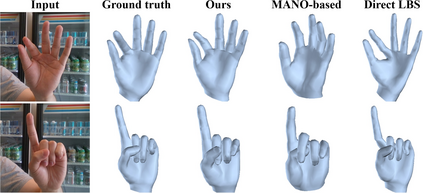
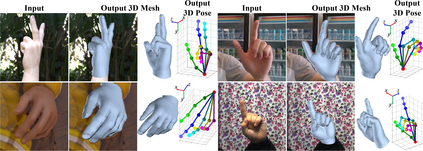
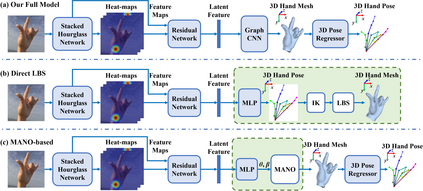
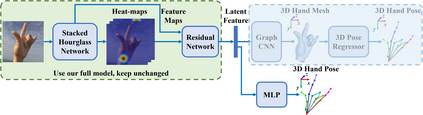
This work addresses a novel and challenging problem of estimating the full 3D hand shape and pose from a single RGB image. Most current methods in 3D hand analysis from monocular RGB images only focus on estimating the 3D locations of hand keypoints, which cannot fully express the 3D shape of hand. In contrast, we propose a Graph Convolutional Neural Network (Graph CNN) based method to reconstruct a full 3D mesh of hand surface that contains richer information of both 3D hand shape and pose. To train networks with full supervision, we create a large-scale synthetic dataset containing both ground truth 3D meshes and 3D poses. When fine-tuning the networks on real-world datasets without 3D ground truth, we propose a weakly-supervised approach by leveraging the depth map as a weak supervision in training. Through extensive evaluations on our proposed new datasets and two public datasets, we show that our proposed method can produce accurate and reasonable 3D hand mesh, and can achieve superior 3D hand pose estimation accuracy when compared with state-of-the-art methods.
翻译:这项工作解决了一个新颖而具有挑战性的问题,即估计全 3D 手形和从一个 RGB 图像中成型。目前单眼 RGB 图像中的3D 手分析方法大多侧重于估计手键点的三维位置,而手键点无法充分表达三维形状。与此相反,我们提议了一个基于图表进化神经网络(Graph CNN)的方法来重建一个完整的三维手表层,其中包括3D 手形和姿势的更丰富的信息。为了在充分监督下培训网络,我们创建了一个大型合成数据集,包括地面真相 3D 模和 3D 模具。在对真实世界数据集的网络进行微调时,我们建议采用一个弱度的超强方法,即利用深度地图作为培训中的薄弱监督手段。通过对我们拟议的新数据集和两个公共数据集进行广泛的评价,我们表明,我们提出的方法可以产生准确和合理的三维手模,并且能够实现与最新方法相比的高级三维手的准确性估算。