深度学习
·

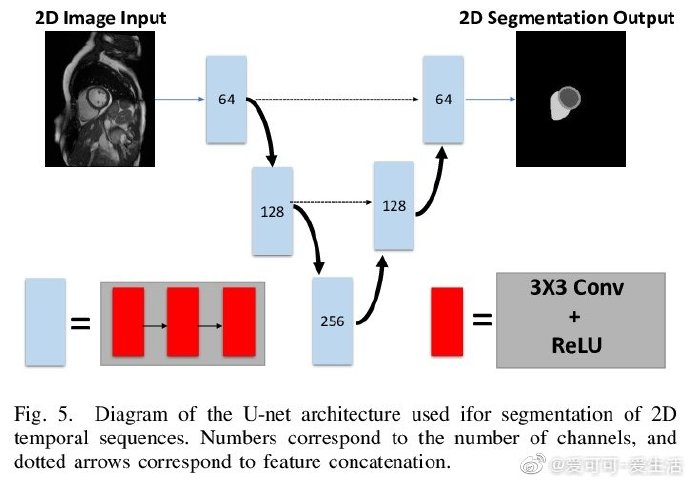
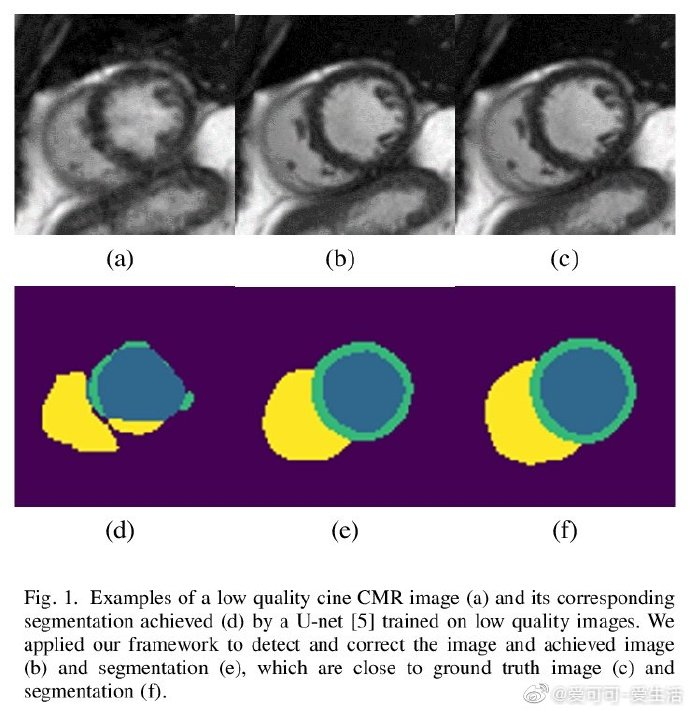
《Deep Learning Based Detection and Correction of Cardiac MR Motion Artefacts During Reconstruction for High-Quality Segmentation》I Oksuz, J R. Clough, B Ruijsink, E P Anton, A Bustin, G Cruz, C Prieto, A P. King, J A. Schnabel [King’s College London] (2019)
成为VIP会员查看完整内容
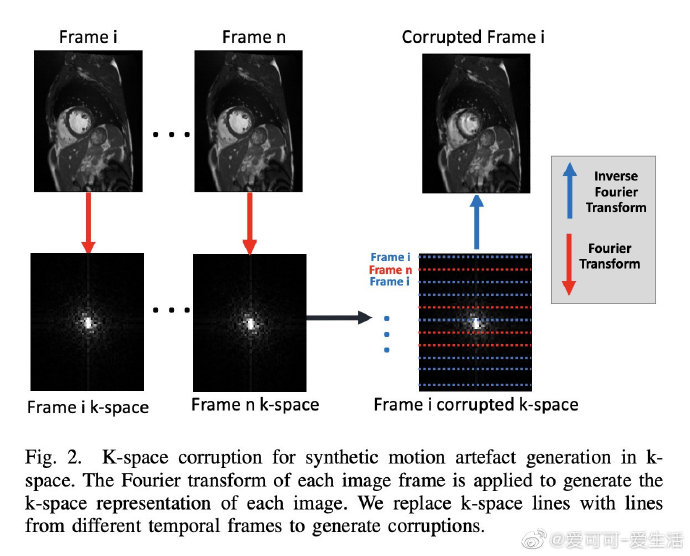


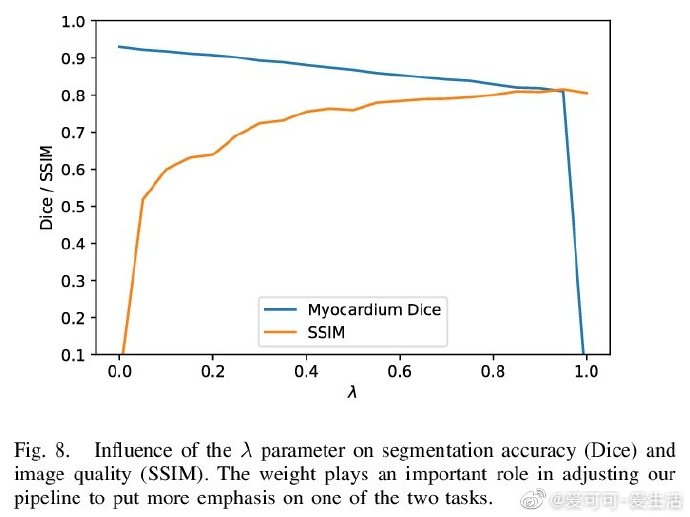
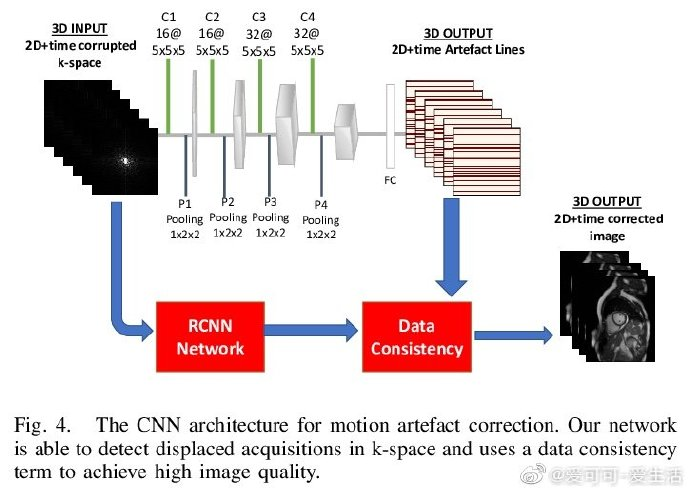
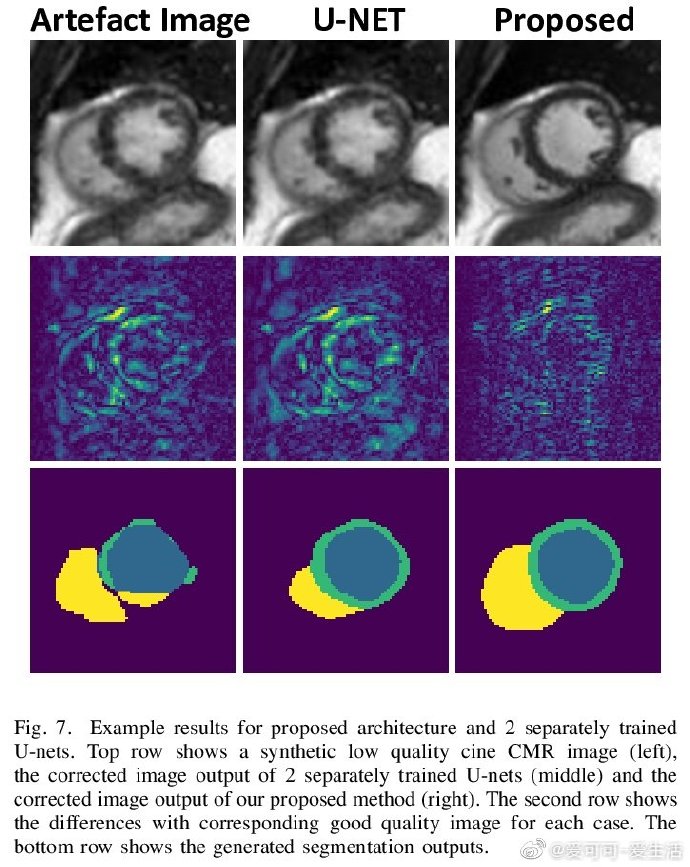
相关内容
专知会员服务
28+阅读 · 2020年6月13日
【图像分割| 2019最新综述】理解图像分割的深度学习技术,附58页PDF(Understanding Deep Learning Techniques for Image Segmentation)
专知会员服务
59+阅读 · 2019年11月16日
Arxiv
3+阅读 · 2018年9月17日
相关主题

相关VIP内容
专知会员服务
28+阅读 · 2020年6月13日
【图像分割| 2019最新综述】理解图像分割的深度学习技术,附58页PDF(Understanding Deep Learning Techniques for Image Segmentation)
专知会员服务
59+阅读 · 2019年11月16日
相关资讯
相关论文
Arxiv
3+阅读 · 2018年9月17日