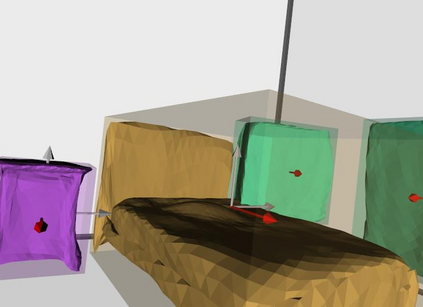
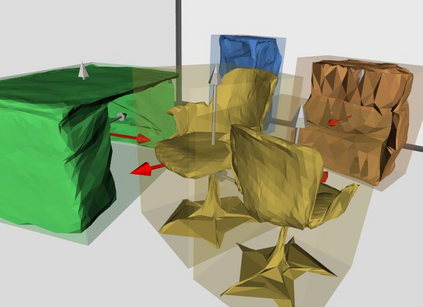
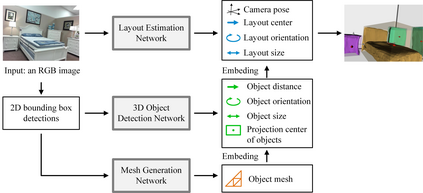
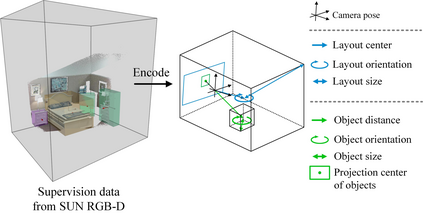
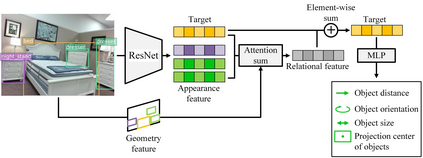
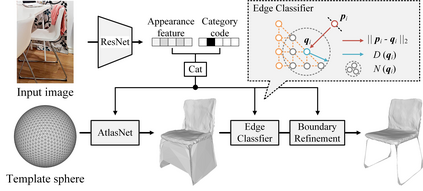
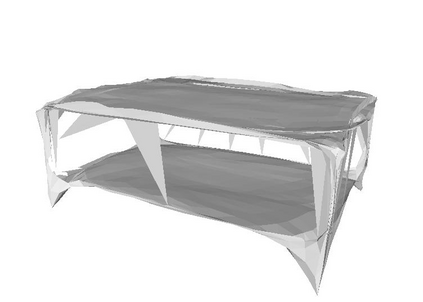
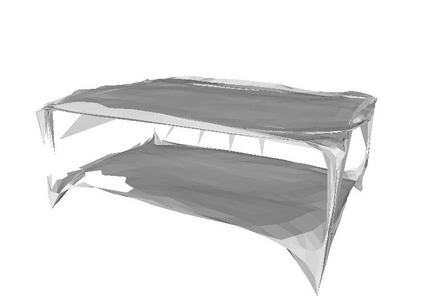
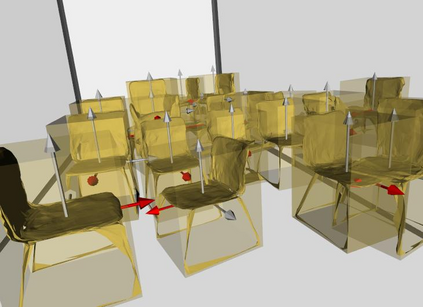
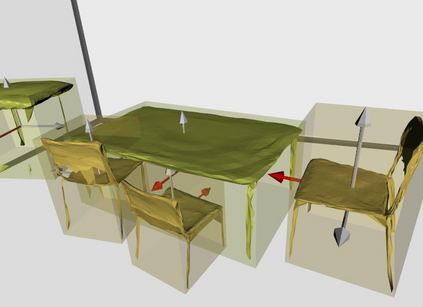
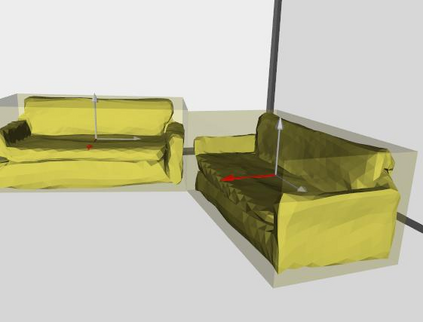
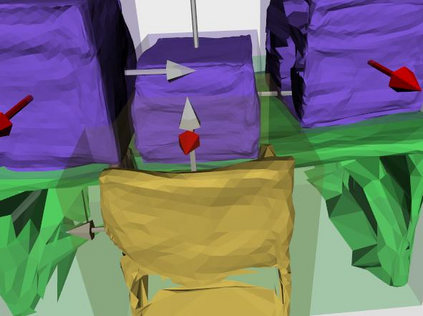
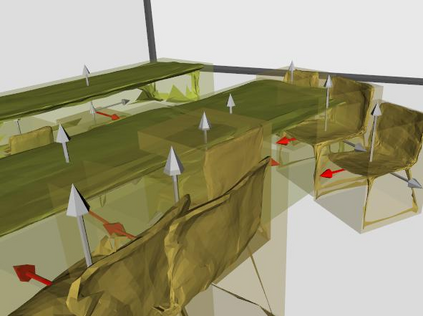
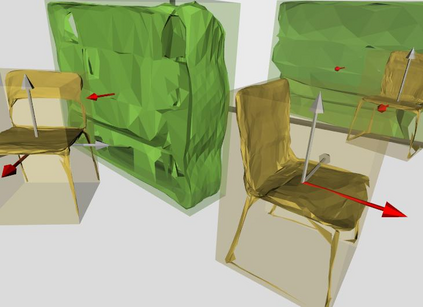
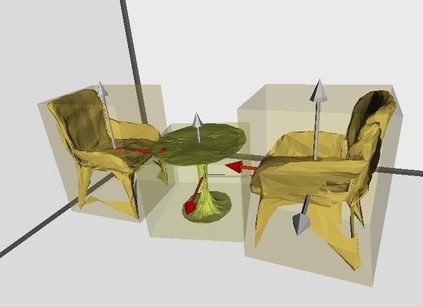
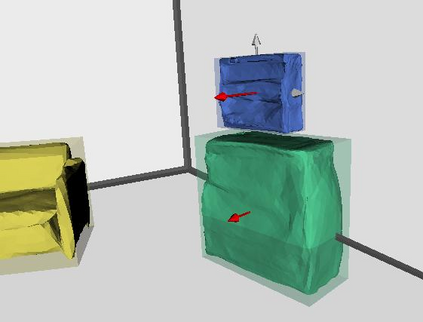
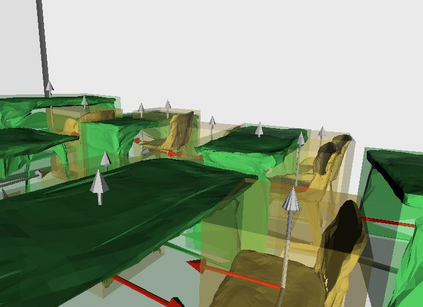
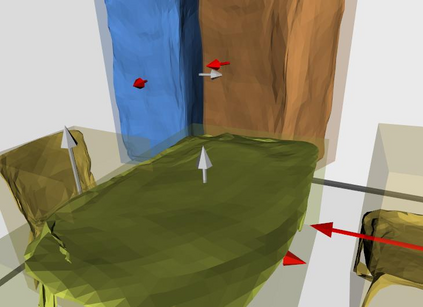
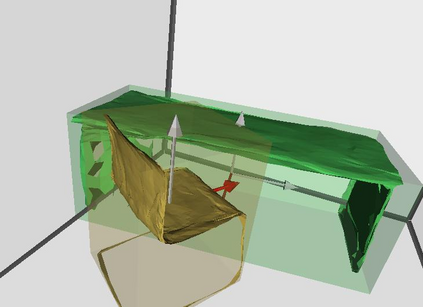
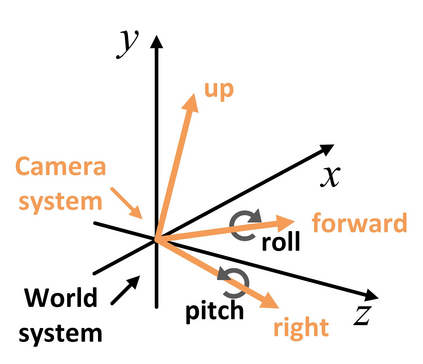
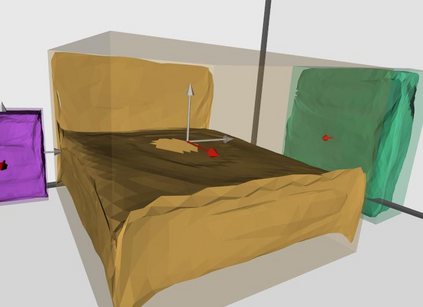
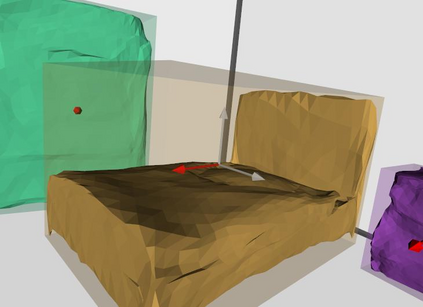
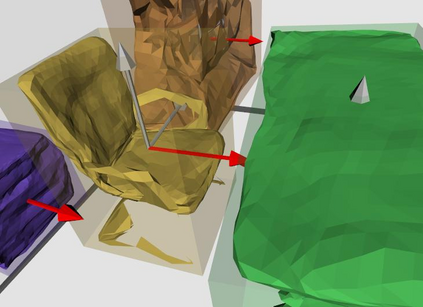
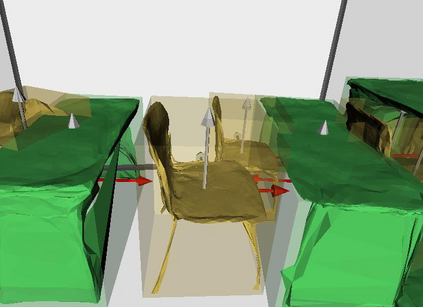
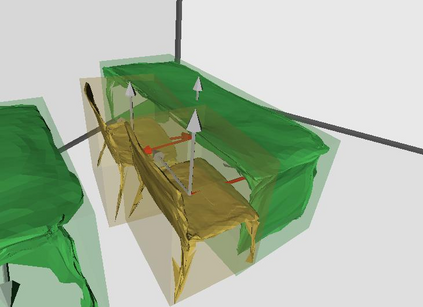
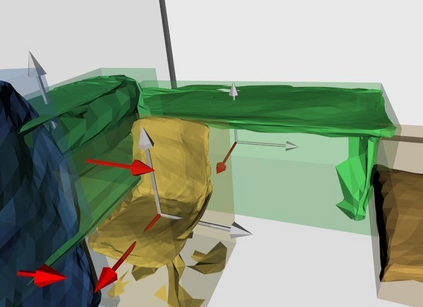
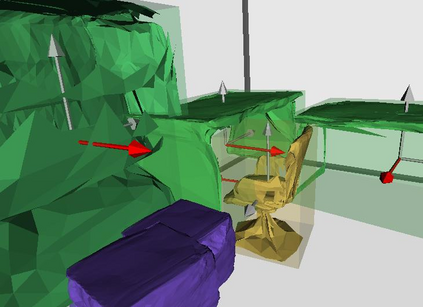
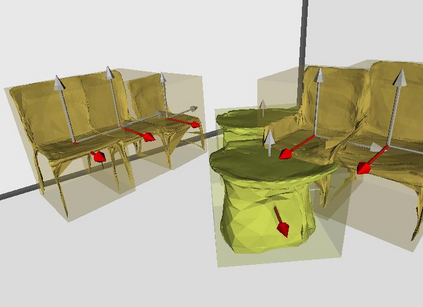
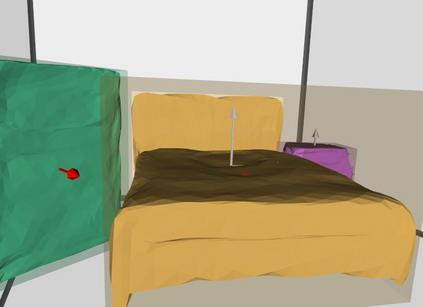
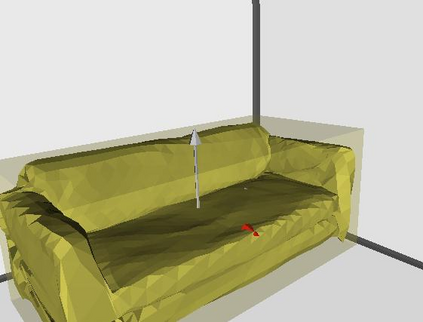
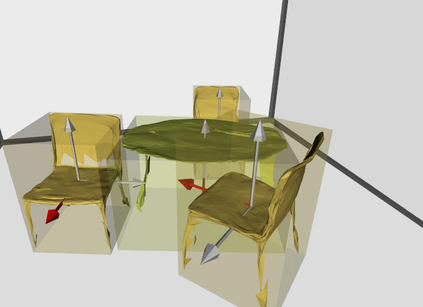
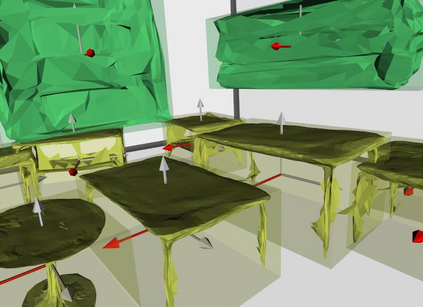
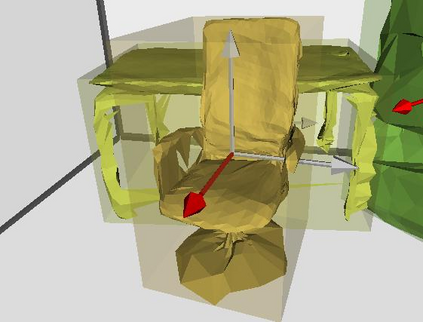
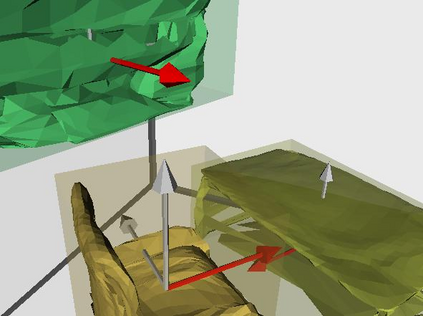
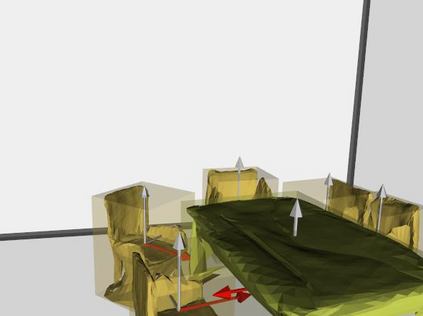
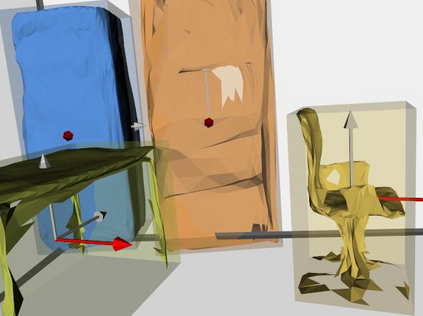
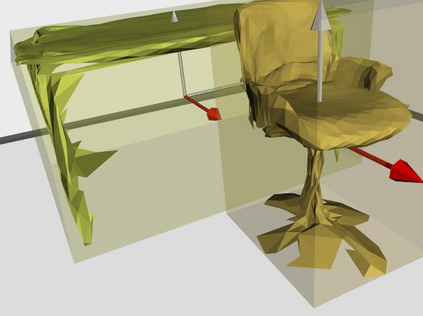
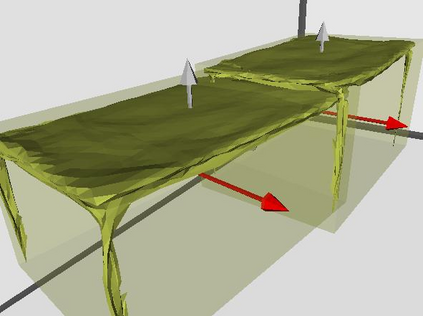
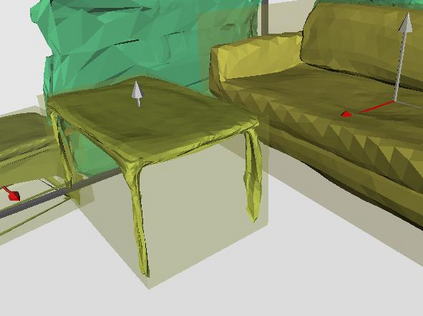
Semantic reconstruction of indoor scenes refers to both scene understanding and object reconstruction. Existing works either address one part of this problem or focus on independent objects. In this paper, we bridge the gap between understanding and reconstruction, and propose an end-to-end solution to jointly reconstruct room layout, object bounding boxes and meshes from a single image. Instead of separately resolving scene understanding and object reconstruction, our method builds upon a holistic scene context and proposes a coarse-to-fine hierarchy with three components: 1. room layout with camera pose; 2. 3D object bounding boxes; 3. object meshes. We argue that understanding the context of each component can assist the task of parsing the others, which enables joint understanding and reconstruction. The experiments on the SUN RGB-D and Pix3D datasets demonstrate that our method consistently outperforms existing methods in indoor layout estimation, 3D object detection and mesh reconstruction.
翻译:室内场景的语义重建既指对场景的理解,也指对物体的重建。现有的工程要么针对这一问题的一个部分,要么侧重于独立物体。在本文中,我们弥合了理解和重建之间的差距,并提出了一个从单一图像中联合重建房间布局、物体捆绑框和网目的端到端解决方案。我们的方法不是单独解决对场景的理解和物体重建,而是建立在整体的场景背景之上,并提出了一个粗略到端的层次,包括三个组成部分:1. 装有照相机的房间布局;2. 3D物体捆绑框;3. 物体模件。我们说,了解每个组成部分的背景可以帮助区分其他组成部分,从而能够共同理解和重建。 SUN RGB-D 和 Pix3D 数据集的实验表明,我们的方法始终超越了室内布局估计、3D物体探测和网目重建的现有方法。