
今天跟大家聊一聊ICLR 2022微软亚研院的一篇工作BEIT: BERT Pre-Training of Image Transformers(ICLR 2022)。BEIT是一种图像无监督预训练,属于最近非常火的Vision Transformer这类工作的研究方向(Vision Transformer前沿工作详细汇总可以参考历史文章从ViT到Swin,10篇顶会论文看Transformer在CV领域的发展历程)。首先简单介绍一下这篇文章的整体思路:利用BERT中MLM(Masked Language Modeling)的思路,把一个图像转换成token序列,对图像token进行mask,然后预测被mask掉的图像token,实现图像领域的无监督预训练。
这个想法听起来跟BERT没有太大区别,但是想把这个思路成功应用到图像领域,并且取得效果,就不是那么容易了。接下来我们走进BEIT,看看这篇工作是如何实现将MLM预训练应用到图像领域的。我们首先介绍BEIT的原理,再对比BEIT和历史的Vision Transformer工作,如iGPT、ViT等,看看BEIT有哪些优越之处。
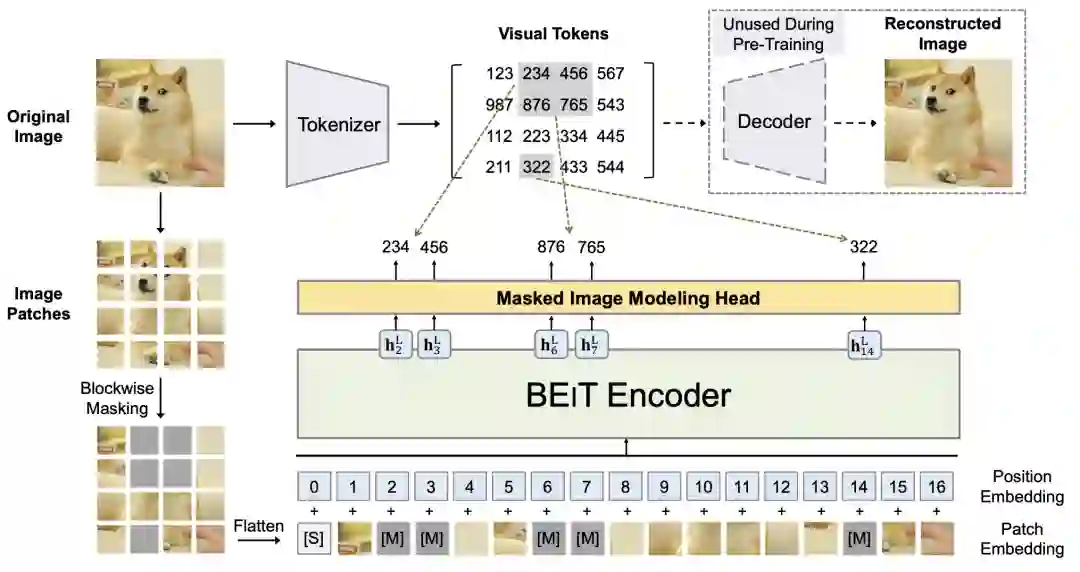
BEIT主要分为dVAE和基于Vision Transformer的MIM(Masked Image Modeling)两个部分。其中,dVAE用来实现将图像转换为图像token,Vision Transformer部分使用ViT作为backbone对图像进行编码,并对mask掉的图像token。BEIT整体的模型结构如下图所示。下面我们对模型结构进行详细介绍。
成为VIP会员查看完整内容
相关内容

相关主题


相关VIP内容
相关资讯
相关论文