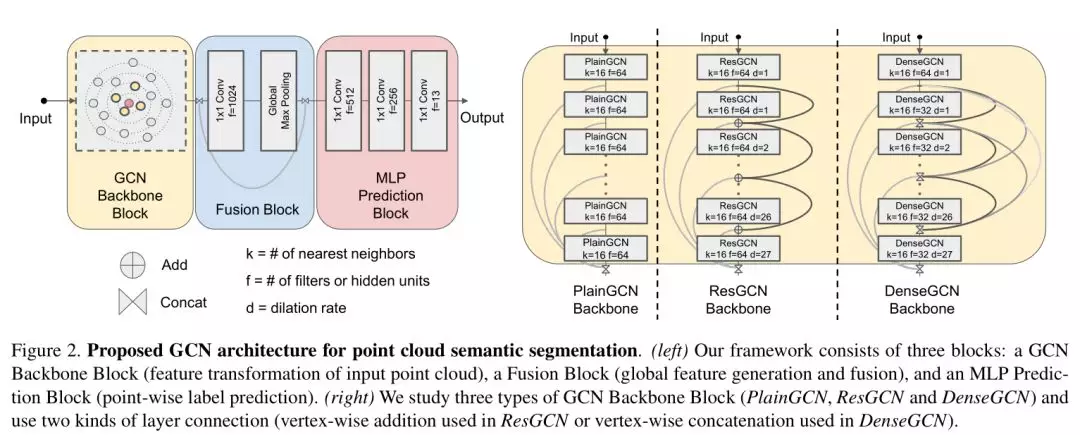
1、DeepGCNs:Can GCNs Go as Deep as CNNs
作者:Guohao Li , Matthias Müller , Ali Thabet Bernard Ghanem;
摘要:卷积神经网络(CNNs)在广泛的领域中取得了令人印象深刻的性能。他们的成功得益于一个巨大的推动,当非常深入的CNN模型能够可靠的训练。尽管CNNs有其优点,但它不能很好地解决非欧几里德数据的问题。为了克服这一挑战,图形卷积网络(GCNS)构建图形来表示非欧几里德数据,借用CNNs的概念,并将它们应用于训练。GCNs显示出有希望的结果,但由于消失梯度问题,它们通常仅限于非常浅的模型(见图1)。因此,最先进的GCN模型不超过3层或4层。在这项工作中,我们提出了新的方法来成功地训练非常深的GCNs。我们通过借鉴CNNs的概念来做到这一点,特别是剩余/密集连接和扩展卷积,并将它们应用到GCN架构中。大量的实验证明了这些深度GCN框架的积极作用。最后,我们使用这些新的概念来构建一个非常深的56层GCN,并展示了它如何在点云语义分割任务中显著提升性能(+ 3.7% Miou-Unice状态)。我们相信公众可以从这项工作中受益,因为它为推进基于GCN的研究提供了许多机会。
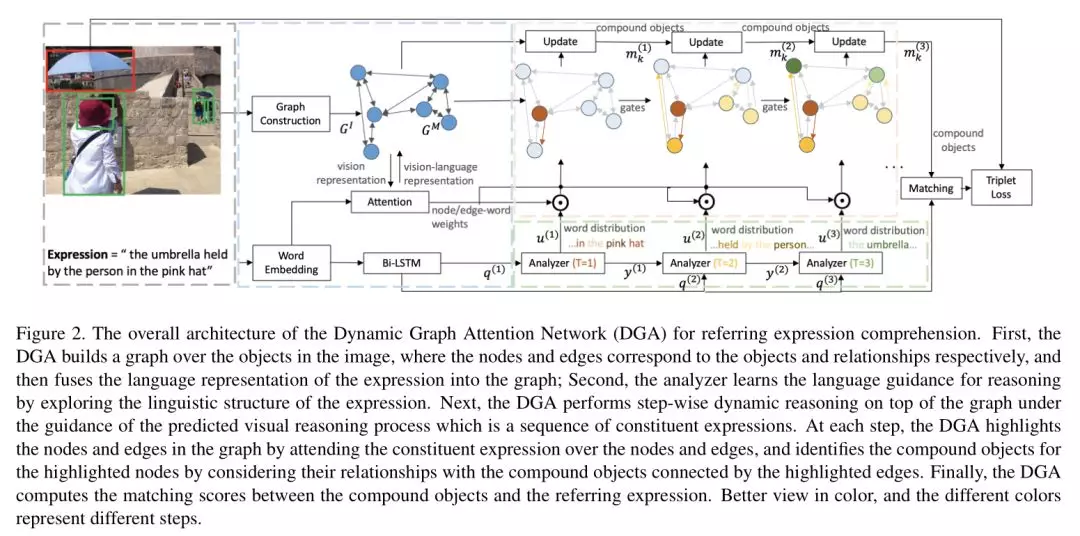
2、Dynamic Graph Attention for Referring Expression Comprehension
作者:Sibei Yang, Guanbin Li, Yizhou Yu;
摘要:引用表达式理解的目的是在图像中定位由自然语言描述的对象实例。这项任务是合成的,本质上需要在图像中对象之间关系的基础上进行视觉推理。同时,视觉推理过程是由指称表达式的语言结构来指导的。然而,现有的方法孤立地对待对象,或者只探索对象之间的一阶关系,而不与表达式的潜在复杂性对齐。因此,他们很难适应复杂的参考表达的基础。本文从语言驱动的视觉推理的角度,探讨了表达理解的问题,并提出了一种动态图形注意力网络,通过对图像中的对象之间的关系和表达的语言结构进行建模来进行多步推理。特别地,我们构造了具有对应于对象和它们的关系的节点和边缘的图像,提出了一种差分分析器来预测语言制导的视觉推理过程,并在图的顶部执行逐步推理,以更新每个节点上的复合对象表示。实验结果表明,所提出的方法在三个共同的基准数据集不仅可以显著超越所有现有的最先进的算法,而且还能产生可解释的视觉证据,以逐步定位复杂的语言描述的对象。
3、Understanding Human Gaze Communication by Spatio-Temporal Graph Reasoning
作者:Lifeng Fan, Wenguan Wang, Siyuan Huang, Xinyu Tang, Song-Chun Zhu;
摘要:本文从原子层次和事件层次两个方面探讨了社会视频中人的注释交流这一新问题,对研究人类的社会互动具有重要意义。为了解决这一新颖而具有挑战性的问题,我们贡献了一个大规模的视频数据集,VACATION,涵盖不同的日常社会场景和注释交流行为,并在原子级和事件级对物体和人脸、人类注意力、交流结构和标签进行了完整的注释。结合VACATION,我们提出了一个时空图神经网络,明确地表示社会场景中不同的注释交互,并通过消息传递来推断原子级的注视交流。在此基础上,进一步提出了一种基于编码-解码器结构的事件网络来预测事件级注视通信。我们的实验表明,该模型在预测原子级和事件级注释通信时显著地改进了各种基线。
网址:https://www.zhuanzhi.ai/paper/2f4739c0d443734235de98bf900fb936
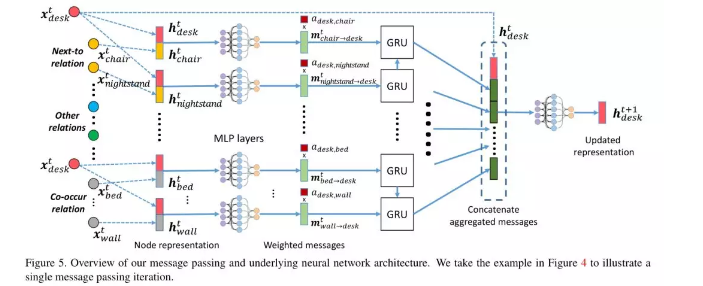
4、SceneGraphNet Neural Message Passing for 3D Indoor Scene Augmentation
作者:Yang Zhou, Zachary While, Evangelos Kalogerakis;
摘要:在本文中,我们提出了一种神经消息传递方法,以增加输入三维室内场景中与周围环境匹配的新对象。给定一个输入,可能是不完整的,三维场景和一个查询位置(图1),我们的方法预测在该位置上适合的对象类型上的概率分布。我们的分布是通过在稠密图中传递学习信息来预测的,其节点表示输入场景中的对象,并且边缘表示空间和结构关系。通过一个注意力机制对消息进行加权,我们的方法学会将注意力集中在最相关的周围场景上下文,从而预测新的场景对象。基于我们在SUNCG数据集中的实验,我们发现我们的方法在正确预测场景中丢失的对象方面明显优于最先进的方法。我们还演示了我们的方法的其他应用,包括基于上下文的3D对象识别和迭代场景生成。
网址:https://www.zhuanzhi.ai/paper/269b2ab31a49b5d29166ed480bf38d58
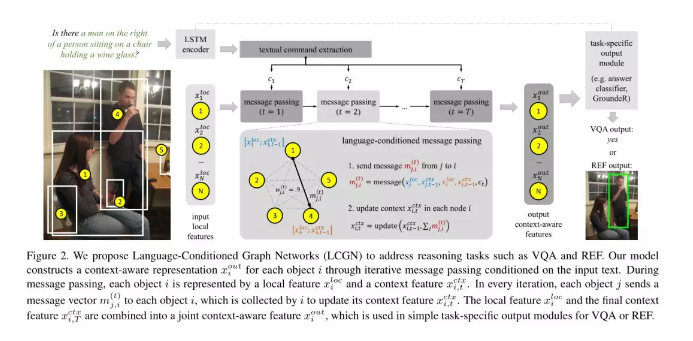
5、Language-Conditioned Graph Networks for Relational Reasoning
作者:Ronghang Hu, Anna Rohrbach, Trevor Darrell, Kate Saenko ;
摘要:解决基于语言任务通常需要对给定任务上下文中对象之间的关系进行推理。例如,要回答盘子上的杯子是什么颜色??我们必须检查特定杯子的颜色,以满足盘子上的关系。最近的工作提出了各种复杂关系推理的方法。然而,它们的能力大多在推理结构上,而场景则用简单的局部外观特征来表示。在本文中,我们采取另一种方法,建立一个视觉场景中的对象的上下文化表示,以支持关系推理。我们提出了一个通用的语言条件图网络(LCGN)框架,其中每个节点代表一个对象,并通过文本输入的迭代消息传递来描述相关对象的感知表示。例如,调节与plate的on关系,对象mug收集来自对象plate的消息,以将其表示更新为mug on the plate,这可以很容易地被简单分类器用于答案预测。我们的实验表明,我们的LCGN方法有效地支持关系推理,并在多个任务和数据集上提高了性能。我们的代码可以在http://ronghanghu.com/lcgn上获得。
网址: https://www.zhuanzhi.ai/paper/5a8a5edf8c004b9f42814ae915220943