近些年来,深度学习领域出现了一大批能力、容量均不断增长的架构。在不断升级的硬件的支持下,今天的模型已经能够轻松地消化数百万张图像,而且开始向数以亿计的标记图像进发。
在自然语言处理中,这种数据需求已经成功地通过自监督预训练来解决。基于 GPT 自回归语言建模和 BERT 掩蔽自编码的解决方案在概念上非常简单:它们删除一部分数据,并学习预测删除的内容。这些方法可以用来训练包含数千亿参数的可泛化 NLP 模型。
掩蔽自编码器是一种更通用的去噪自编码器,也适用于计算机视觉。其实,与视觉密切相关的研究早于 BERT。在 BERT 成功之后,人们对这一想法也产生了极大的兴趣。但尽管如此,视觉自编码方法的发展还是落后于 NLP。何恺明等研究者想知道:是什么造成了这种差异?
他们尝试从以下几个角度来回答这一问题:
1、架构差异。在计算机视觉领域,卷积网络是过去十年的主流架构。不过,随着 Vision Transformers(ViT)的推出,这种架构上的差异已经逐渐缩小,应该不会再成为障碍。
2、信息密度差异。语言是人类产生的高度语义化信号,信息非常密集。当训练一个模型来预测每个句子中缺失的寥寥数词时,这项任务似乎能诱发复杂的语言理解。但视觉任务就不同了:图像是自然信号,拥有大量的空间冗余。例如,一个缺失的 patch 可以根据相邻的 patch 恢复,而不需要对其他部分、对象和场景有很多的高级理解。
为了克服这种差异并鼓励学习有用的特征,研究者展示了:一个简单的策略在计算机视觉中也能非常有效:掩蔽很大一部分随机 patch。这种策略在很大程度上减少了冗余,并创造了一个具有挑战性的自监督任务,该任务需要超越低级图像统计的整体理解。下图 2 - 图 4 展示了这一重建任务的定性结果。
3、自编码器的解码器(将潜在表征映射回输入)在文本和图像重建任务中起着不同的作用。在计算机视觉任务中,解码器重建的是像素,因此其输出的语义水平低于一般的识别任务。这与语言相反,语言任务中的解码器预测的是包含丰富语义信息的缺失单词。虽然在 BERT 中,解码器可能是微不足道的(一个 MLP),但何恺明等研究者发现,对于图像,解码器的设计对于学到的潜在表示的语义水平起着关键作用。
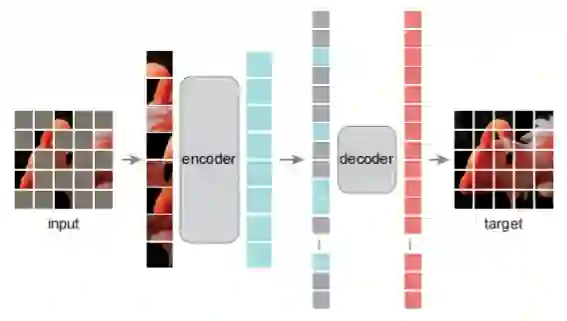
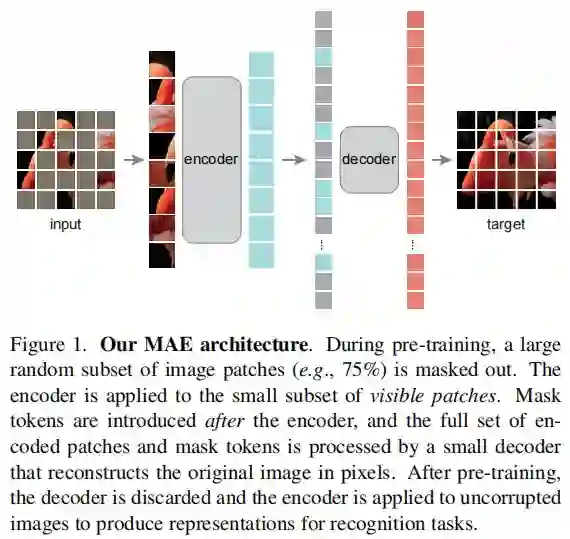
基于以上分析,研究者提出了一种简单、有效且可扩展的掩蔽自编码器(MAE)用于视觉表征学习。该 MAE 从输入图像中掩蔽了随机 patch 并重建像素空间中缺失的 patch。它具有非对称的编码器 - 解码器设计。其中,编码器仅对 patch 的可见子集(没有掩码 token)进行操作,解码器则是轻量级的,可以从潜在表征和掩码 token 中重建输入(图 1)。
在这个非对称编码器 - 解码器中,将掩码 token 转移到小型解码器会导致计算量大幅减少。在这种设计下,非常高的掩蔽率(例如 75%)可以实现双赢:它优化了准确性,同时允许编码器仅处理一小部分(例如 25%)的 patch。这可以将整体预训练时间减少至原来的 1/3 或更低,同时减少内存消耗,使我们能够轻松地将 MAE 扩展到大型模型。
MAE 可以学习非常大容量的模型,而且泛化性能良好。通过 MAE 预训练,研究者可以在 ImageNet-1K 上训练 ViT-Large/-Huge 等需要大量数据的模型,提高泛化性能。例如,在 ImageNet-1K 数据集上,原始 ViT-Huge 模型经过微调后可以实现 87.8% 的准确率。这比以前所有仅使用 ImageNet-1K 数据的模型效果都要好。