由浅及深,细致解读图像问答 VQA 2018 Challenge 冠军模型 Pythia
来源:极市平台
Pythia,她是古希腊的阿波罗神女祭司,以传达阿波罗神的神谕而闻名,被认为能预知未来。她的名字,被 Facebook AI Research 将赋给了在 VQA 2018 Challenge 上的冠军模型。 Pythia 以 VQA 2017 Challenge 的冠军模型 Up-Down 为基本方法,辅助以了诸多工程细节上的调整,这使得 Pythia 较往年增加了约 2% 的性能提升(70.34% → 72.25%)。在这里,我们将尝试去解读这个模型。

论文:https://arxiv.org/abs/1807.09956
代码:
https://github.com/facebookresearch/pythia/
(虽然在提交结果时为 72.25%,但公开的代码中达到的效果为 72.27%)
首先我们将会对 2017 VQA Challenge 的冠军模型 Up-Down 进行解读,而后再引入 Pythia 为其的改进,最后从代码中去查看值得注意的实现部分。一起来看吧!
2017 VQA Challenge 冠军,Up-Down 模型解读
Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering(CVPR'18,澳大利亚国立大学 & 京东 AI 研究院 & Microsoft Research & 阿德莱德大学 & 麦考瑞大学)
http://openaccess.thecvf.com/content_cvpr_2018/CameraReady/1163.pdf
Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challenge(CVPR'18,阿德莱德大学 & 澳大利亚国立大学 & Microsoft Research)
http://openaccess.thecvf.com/content_cvpr_2018/papers/Teney_Tips_and_Tricks_CVPR_2018_paper.pdf
VQA 2017 Challenge 的冠军模型体现在这两篇文章中,我们放在一起介绍。CVPR'18 这一篇是方法论,Tips and Tricks 算是工程实现方面的报告。在方法论中,主打的就是 top-down 和 bottom-up 和两种 attention 机制:前者是指的人会被视觉中的显著突出物体给吸引,是由图像这种底层信息到上层语义的;而后者指的是人在进行某项任务的时候,紧密关注和该任务相关的部分,是由上游任务去关注到图像的。一般的注意力机制就像下图中的左侧显示的那样,是自上而下(top-down)的,表现在依据任务为这些 grid cell 去分配不同的权重,而右侧的注意力机制是自下而上的,从物体层面(object-level)去注意到显著性区域:

那我们首先来看 bottom-up attention 如何实现。作者采用了基于 ResNet-101 的 Faster R-CNN,添加了 attributes 分支在 VisualGenome 上进行了训练,也正因为如此,Faster R-CNN 能进行更为细致的检测 (图2.2)。在得到图像的预测区域后,再取到这个区域对应的特征(7×7×2048 做一个 mean pooling)。也就是说,在 VQA 模型中是没有用到预测出的标签的,而仅仅使用了该区域的特征。
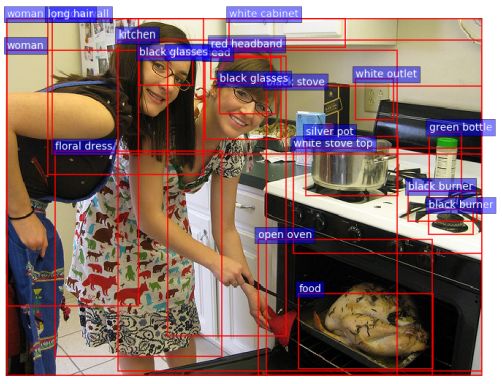

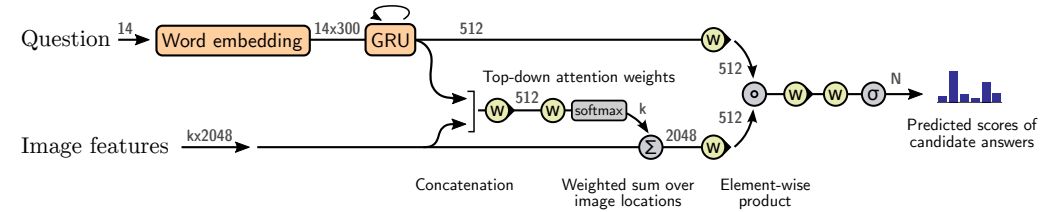
两者结合后的模型称为 Up-Down,以下提供了在 VQA v2.0 上的评测结果,为提交时最高:
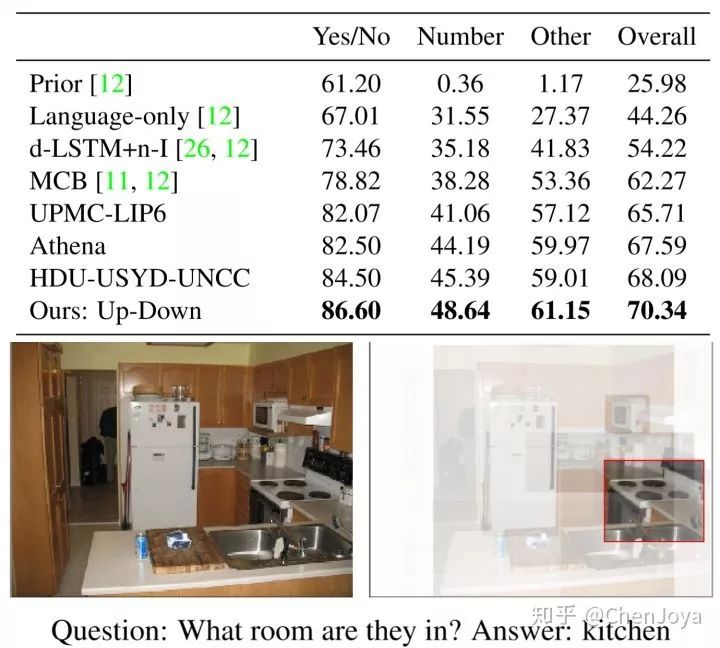
从评测时集成了 30 个模型就可以看出,文章中一定有诸多的实现细节。下面就是 Tips and Tricks 一文中提及的细节:
(1) sigmoid outputs: 允许多个正确答案存在,利用多个二分类器来替代 softmax;
(2) soft training targets: 这里一开始理解成了知识蒸馏中的 soft target,但是实质上在这里训练时的标签没有任何不同,只是 allow uncertain answers;
(3) image features from bottom-up attention: 这也就是核心方法 Up-Down;

(6) large mini-batches: 256 和 384 最佳;
(7) smart shuffling of training data: 保持在同一个 batch 中的问题都有同样的一对,但是其对应的是不同的图像和答案。
涨点情况以及细致分析可以移步原论文。这里也有分享的 slides:
https://cs.adelaide.edu.au/~Damien/Research/VQA-Challenge-Slides-TeneyAnderson.pdf
将本可以秘而不宣的 tricks 做详细的 ablation study 是一件非常令人感动的事情。
代码:http://www.panderson.me/up-down-attention/
Pythia: 极致的工程能力
Pythia v0.1 the Winning Entry to the VQA Challenge 2018(arxiv'18,Facebook AI Research)
做出这个模型的,是 Facebook AI Research (FAIR)’s A-STAR team. A-STAR 的意思,如果将其拆解开来则是 Agents that See, Talk, Act, and Reason。这些人类才特有的动作,似乎都是 VQA 这个任务里所不可少的一部分。Pythia 的重点调整在于模型结构,超参数,数据增强,以及最后的模型集成。我们分条列举:
模型结构:65.32% → 66.91%
(1)还记得 Up-Down 里面那个长相奇怪的门控激活函数吗?Pythia 使用了 RELU+Weight Normalization 来取代它,这样可以降低计算量,但是效果上有无提升文中没有给出实验。
(2)在进行 top-down 的 attention 权重计算时,将特征整合的方式由原本 concat 转换为 element-wise multiplication,这也是可以降低计算量的表现。
(3)在第二个 LSTM 做文本和图像的联合预测时,hidden size 为 5000 最佳。
超参数:66.91% → 68.05%
这里主要是学习率的调整。作者发现在 Up-Down 模型中适当减小 batch 可以带来一些提升,这意味着在同样的 batch 下提升学习率可能带来性能的提升。为了防止学习率过大不收敛,他们采用了广泛使用的 warm-up 策略,并使用了适当的 lr step。这使得 Pythia 的性能提升约一个点。
Faster R-CNN 增强:68.05% → 68.49%
将 Faster R-CNN 的 backbone 由 ResNet-101 换为 ResNext-101-FPN,并且不再使用 ROI Pooling 后的 7×7×2048 + mean pooling 表征 object -level 特征,而采用 fc7 出来的 2048 维向量以减少计算量。
数据增强:68.49% → 69.24%
采用了图像水平翻转的增强方法,这样的方式在纯视觉任务中广泛出现。在这里还需要做变换的是,将问题和答案中的“左”和“右”对调。
Bottom-up 增强:69.24% → 70.01%
光是使用 Faster R-CNN 在 head network 上的 fc7 特征不足以表示图像整体的特征。于是作者们融合了 ResNet-152 提取的整图特征,并且增加了在每一张图提取 object-level feature 的个数。它们分别带来了可见的提升。
模型集成:70.96% → 72.18%
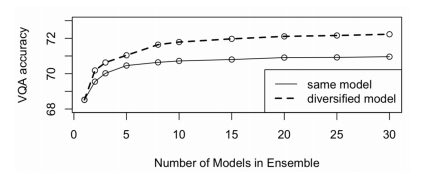
注:72.18% 是 VQA v2.0 test-dev 上的结果,而提交在 test-std 上的结果为 72.27%。test-std 才是最终的榜单排名依据。
总结
Up-Down 是一个十分优秀的,面向于真实图像场景的 VQA 模型,Pythia 是对它的强化实现(不愧是 FAIR,代码写的真是好)。以 Up-Down 为基础的方法已经连续斩获 2017 和 2018 的 VQA 冠军。现在 VQA 2019 Challenge 已经拉开帷幕,winner 将在 VQA and Dialog Workshop, CVPR 2019 (https://visualqa.org/workshop.html) 进行公布。还会是 Up-Down 吗?
☞ OpenPV平台发布在线的ParallelEye视觉任务挑战赛
☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【学界】Ian Goodfellow等人提出对抗重编程,让神经网络执行其他任务
☞【学界】六种GAN评估指标的综合评估实验,迈向定量评估GAN的重要一步
☞【资源】T2T:利用StackGAN和ProGAN从文本生成人脸
☞【学界】 CVPR 2018最佳论文作者亲笔解读:研究视觉任务关联性的Taskonomy
☞【业界】英特尔OpenVINO™工具包为创新智能视觉提供更多可能
☞【学界】ECCV 2018: 对抗深度学习: 鱼 (模型准确性) 与熊掌 (模型鲁棒性) 能否兼得




