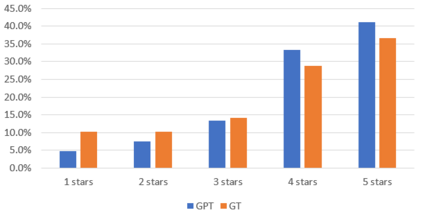
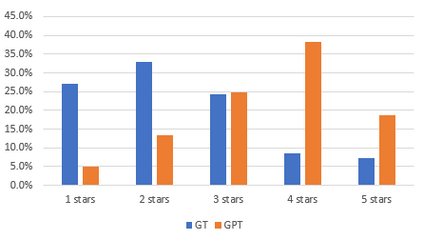
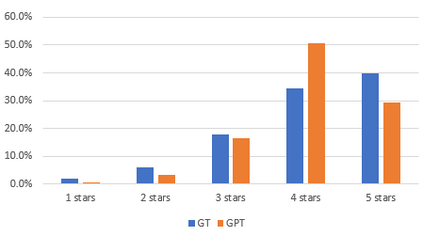
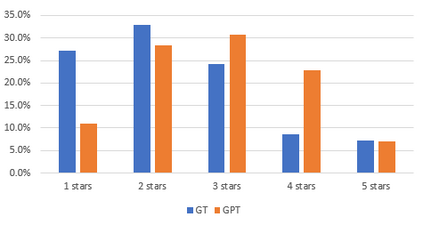
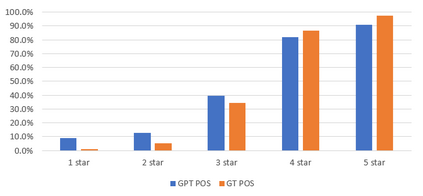
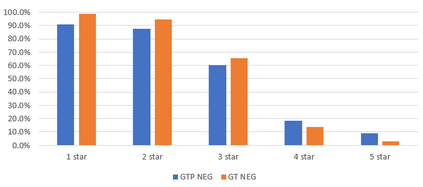
Text analysis of social media for sentiment, topic analysis, and other analysis depends initially on the selection of keywords and phrases that will be used to create the research corpora. However, keywords that researchers choose may occur infrequently, leading to errors that arise from using small samples. In this paper, we use the capacity for memorization, interpolation, and extrapolation of Transformer Language Models such as the GPT series to learn the linguistic behaviors of a subgroup within larger corpora of Yelp reviews. We then use prompt-based queries to generate synthetic text that can be analyzed to produce insights into specific opinions held by the populations that the models were trained on. Once learned, more specific sentiment queries can be made of the model with high levels of accuracy when compared to traditional keyword searches. We show that even in cases where a specific keyphrase is limited or not present at all in the training corpora, the GPT is able to accurately generate large volumes of text that have the correct sentiment.
翻译:用于情感、专题分析和其他分析的社交媒体文本分析,最初取决于选择关键词和短语,这些关键词和短语将用来创建研究公司。然而,研究人员选择的关键词可能会不经常发生,导致使用小样本产生的错误。在本文中,我们利用诸如GPT系列等变异语言模型的记忆、内插和外推能力来学习Yelp审查大公司内部一个分组的语言行为。然后我们利用基于即时的查询来生成合成文本,可以分析合成文本,以深入了解这些模型所培训的群体持有的具体意见。一旦学习到,就可以对与传统关键词搜索相比具有高度准确性的模式进行更具体的情绪查询。我们表明,即使具体关键词短语在培训公司中受到限制或根本没有出现,但GPT能够准确生成大量具有正确感知力的文本。