摘要:
本文提出了一个简单而通用的目标检测框架Pix2Seq。不像现有的方法,明确地集成关于任务的先验知识,我们简单地将目标检测作为一个语言建模任务,条件是观察像素输入。目标描述(如包围盒和类标签)被表示为离散符号序列,我们训练神经网络来感知图像并生成所需的序列。我们的方法主要基于直觉,即如果神经网络知道目标在哪里和是什么,我们只需要教它如何读出它们。除了使用特定于任务的数据增强外,我们的方法对任务进行了最小的假设,但与高度专业化和良好优化的检测算法相比,它在具有挑战性的COCO数据集上取得了具有非常好的结果。
引言
视觉目标检测系统的目标是识别和定位图像中所有预定义类别的目标。检测到的对象通常由一组包围框和相关的类标签描述。考虑到任务的难度,大多数现有的方法,如(Girshick, 2015; Ren et al., 2015; He et al., 2017; Lin et al., 2017b; Carion et al., 2020),经过精心设计和高度定制,在结构和损失功能的选择方面具有大量的先验知识。例如,许多架构都使用了边界框(例如,区域方案(Girshick, 2015;Ren et al., 2015)和RoI池化(Girshick et al., 2014; He et al., 2017))。损失函数也经常被裁剪为使用边界盒,如盒回归(Szegedy et al., 2013;Lin et al., 2017b),集匹配(Erhan et al., 2014;Carion et al., 2020),或合并特定的性能指标,如边界框上的交叉-联合(Rezatofighi et al., 2019)。尽管现有系统在无数领域都有应用,从自动驾驶汽车(Sun et al., 2020),到医学图像分析(Jaeger et al., 2020),再到农业(Sa et al., 2016),但其专业化和复杂性使其难以整合到一个更大的系统中。或者泛化到与通用智能相关的更广泛的任务。
本文提出一种新的方法,如果神经网络知道目标在哪里和什么,我们只需要教它把它们读出来。通过学习“描述”对象目标,模型可以学习以像素观察为基础的“语言”,从而得到有用的目标表示。这是通过我们的Pix2Seq框架实现的。给定一个图像,我们的模型产生一个离散的标记序列,对应于目标描述,让人想起图像字幕系统(Vinyals et al., 2015b; Karpathy & Fei-Fei, 2015; Xu et al., 2015)。本质上,我们将目标检测视为一个以像素输入为条件的语言建模任务,其模型结构和损失函数是通用的、相对简单的,没有针对检测任务进行专门设计。因此,可以很容易地将框架扩展到不同的领域或应用,或将其合并到支持一般智能的感知系统中,为广泛的视觉任务提供语言接口。
为了处理Pix2Seq的检测任务,我们首先提出了一个量化和序列化方案,将包围盒和类标签转换成一个离散令牌序列。然后我们利用编码器-解码器体系结构来感知像素输入并生成目标序列。目标函数是基于像素输入和之前的标记的最大可能性。虽然体系结构和损失函数都是任务无关的(无需假设关于目标检测的先验知识,例如包围框),但我们仍然可以将特定于任务的先验知识与序列增强技术结合起来,该技术在训练过程中改变输入和目标序列,如下所示。通过广泛的实验,与高度定制的、建立良好的方法相比,包括Faster R-CNN (Ren et al., 2015)和DETR (Carion et al., 2020)。,我们证明了这个简单的Pix2Seq框架可以在COCO数据集上取得有竞争力的结果。
PIX2SEQ框架
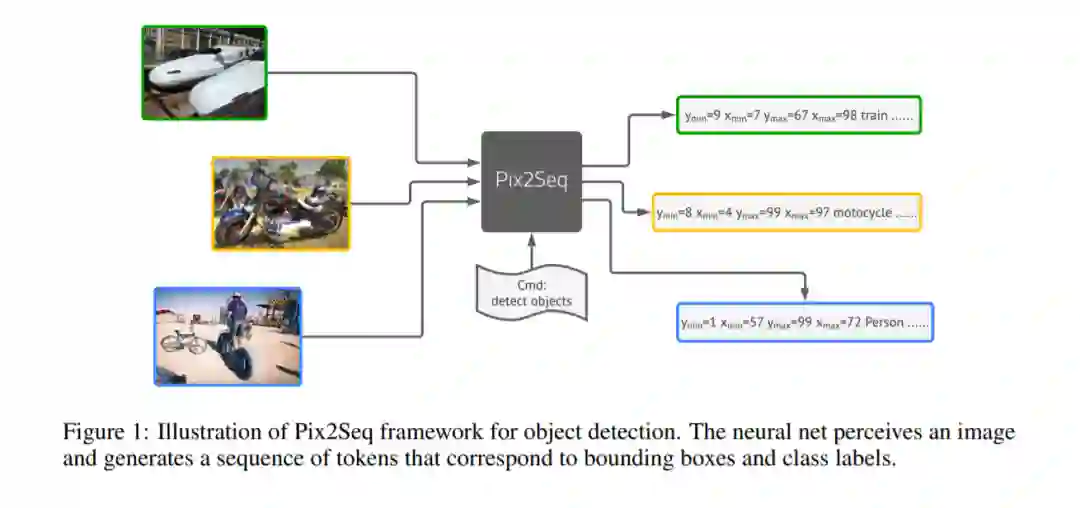
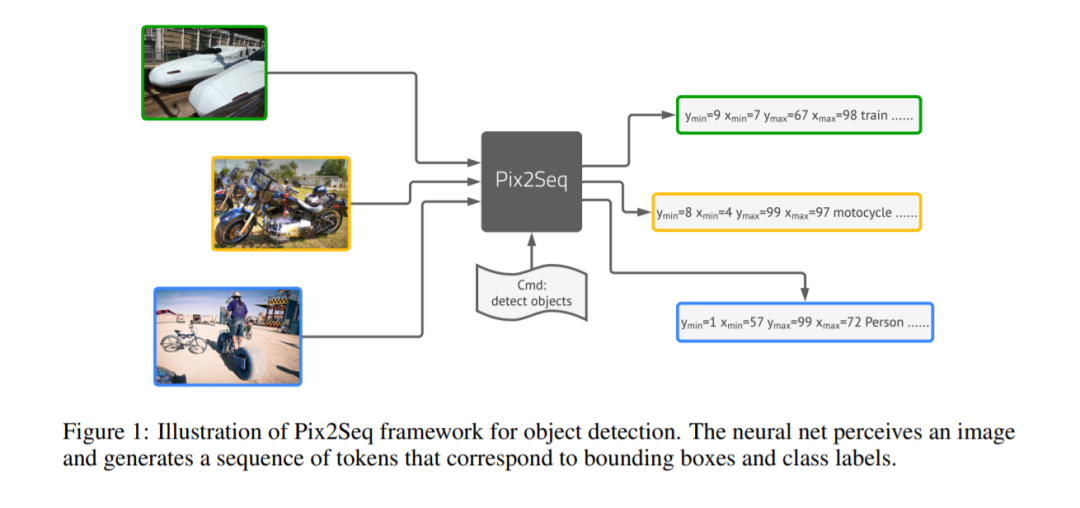
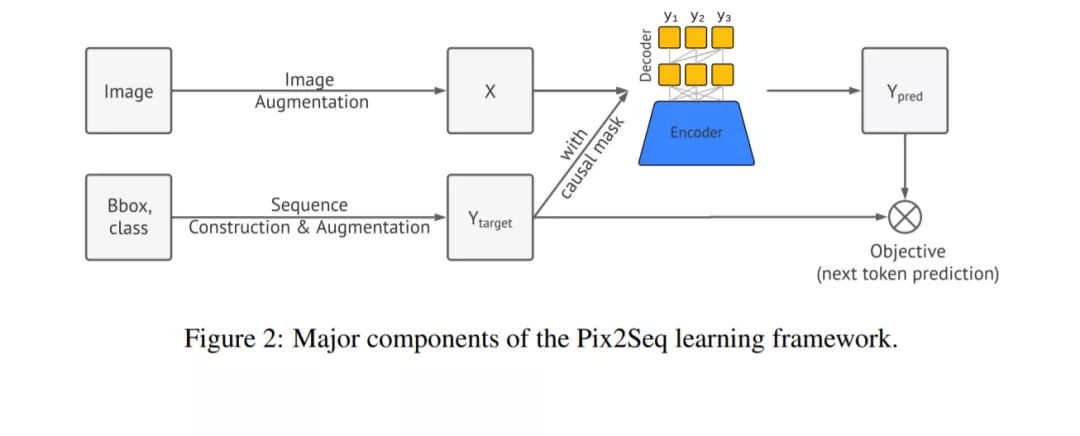
在提出的Pix2Seq框架中,我们将目标检测视为一项语言建模任务,条件是像素输入。如图1所示,Pix2Seq的架构和学习过程有四个主要组件(图2):
图像增强:在训练计算机视觉模型中很常见,我们使用图像增强来丰富一组固定的训练样例
序列构造和增强:由于图像的目标标注通常表示为一组包围盒和类标签,我们将它们转换为一组离散标记。
架构:我们使用编码器-解码器模型,编码器感知像素输入,解码器生成目标序列(每次一个标记)。
目标/损失函数:对模型进行训练,使以图像和之前的令牌为条件的令牌的对数可能性最大化(具有softmax交叉熵损失)。
实验结果
我们在MS-COCO 2017检测数据集(Lin et al., 2014)上评估了提出的方法,该数据集包含118k训练图像和5k验证图像。为了与DETR和Faster R-CNN进行比较,我们报告了平均精度(AP)。
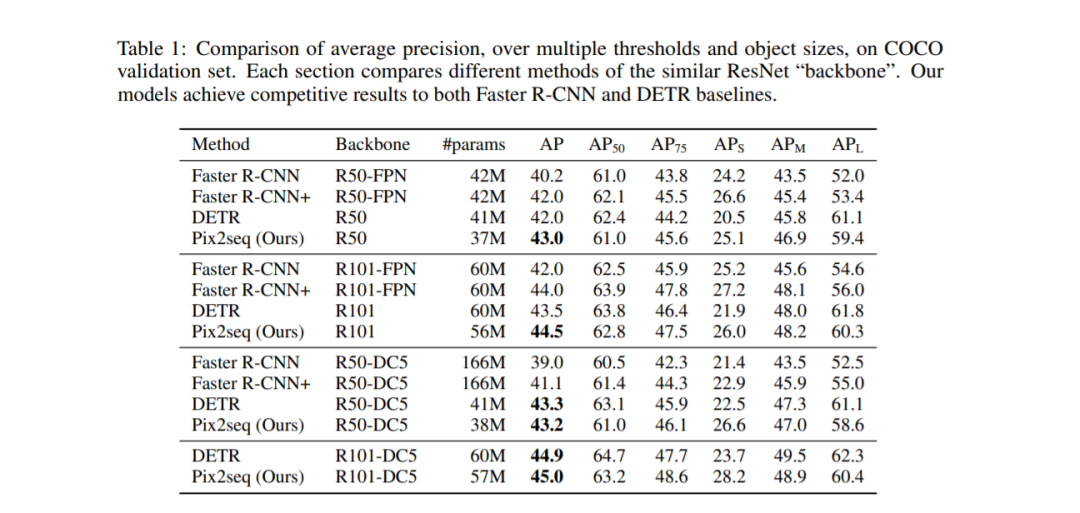
结果如表1所示,其中每一节比较相同ResNet“骨干网”的不同方法。总体而言,Pix2Seq在这两个Baseline上都取得了有相匹配的结果。我们的模型在小型和中型目标对象上的表现与Faster R-CNN相当,但在大型目标对象上表现更好。与DETR相比,我们的模型在大型和中型目标对象上的性能相当或略差,但在小型目标上性能明显更好。
结论
本文介绍了一个简单而通用的目标检测框架Pix2Seq。通过将目标检测转换为语言建模任务,我们的方法在很大程度上简化了检测pipeline,消除了现代检测算法中的大部分专业化。虽然在具有挑战性的COCO数据集上,它与建立良好的基线相比取得了有竞争力的结果,但架构和训练过程仍然可以进行优化,以提高其性能。我们认为,所提出的Pix2Seq框架不仅适用于目标检测,还可以应用于其他产生低带宽输出的视觉任务,其中输出可以表示为一个相对简洁的离散token序列(如关键点检测、图像字幕、视觉问答)。为此,我们希望将Pix2Seq扩展为一个通用和统一的接口,以解决各种各样的视觉任务。此外,目前训练Pix2Seq的方法完全是基于人类注释的,我们希望减少这种依赖,让模型也能从更多的未标记数据中受益。