编辑:好困
【新智元导读】这个模型不仅在ICLR 2022上杀出了一条血路,还挤下去了榜单上的一众大佬,稳坐首席近两个月。
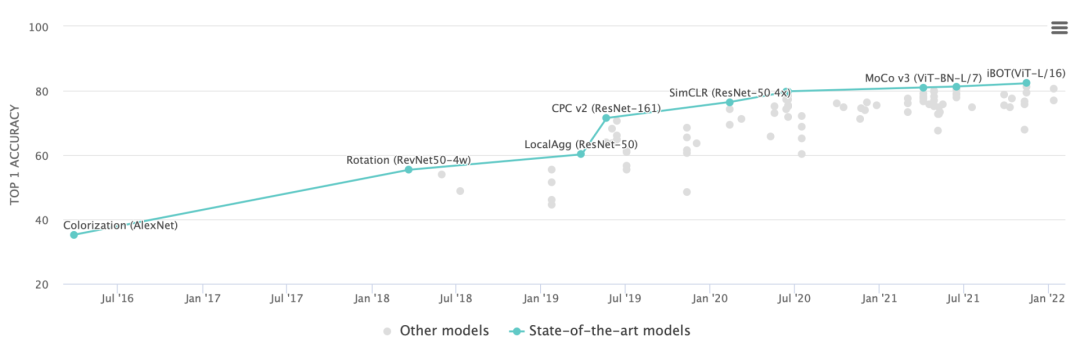
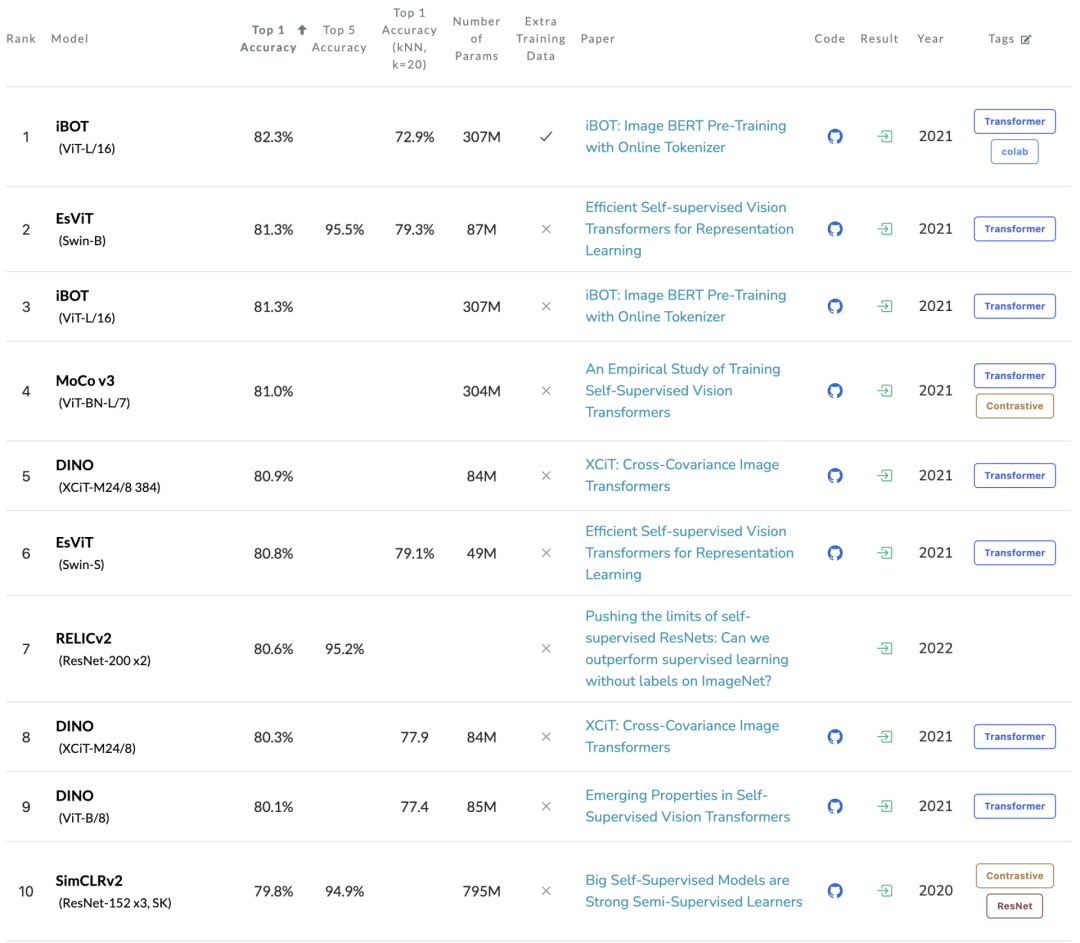
最近,一个由中国团队提出的iBOT开源模型在无监督分类、线性分类、微调分类这三大自监督主流评估方式上,「霸榜」了近两个月的时间。
这个榜单由Paper With Code发布,其中记录了各大领域在不同任务设置下最新的SOTA算法。
能跻身于前10的工作,基本都是来自知名大厂:Microsoft、Meta、DeepMind、Google等,而iBOT则同时在这些榜单上取得了SOTA的结果。
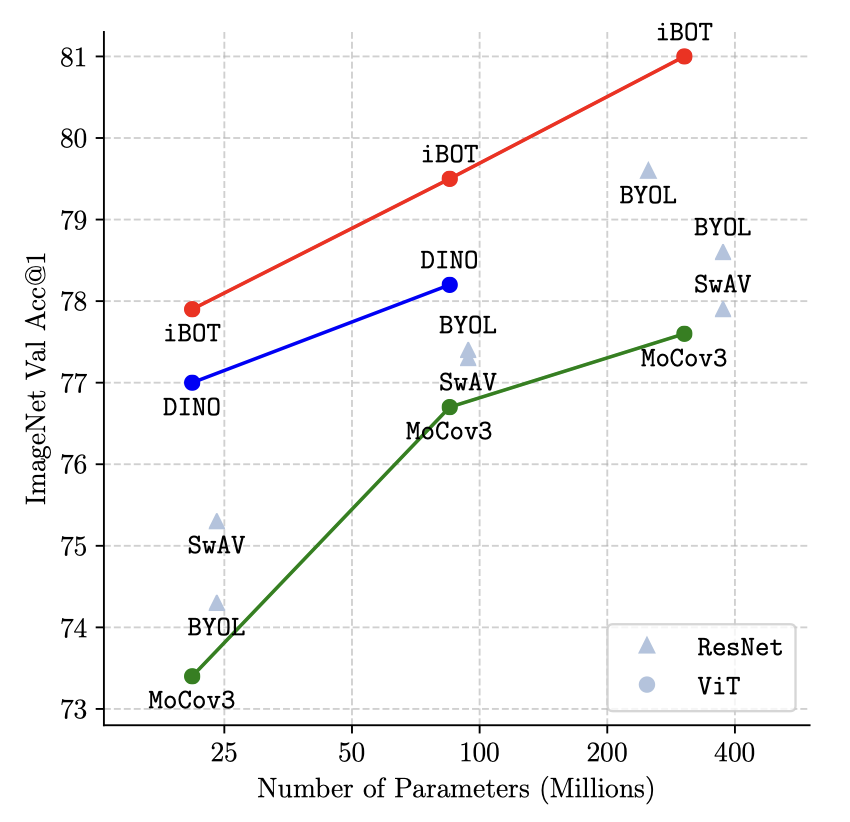
尤其在线性分类评估方式下,iBOT更是比第二名来自Microsoft的EsViT在Top1 Acc指标上直接高了一个点(81.3 v.s. 82.3),这个结果是非常惊人的。
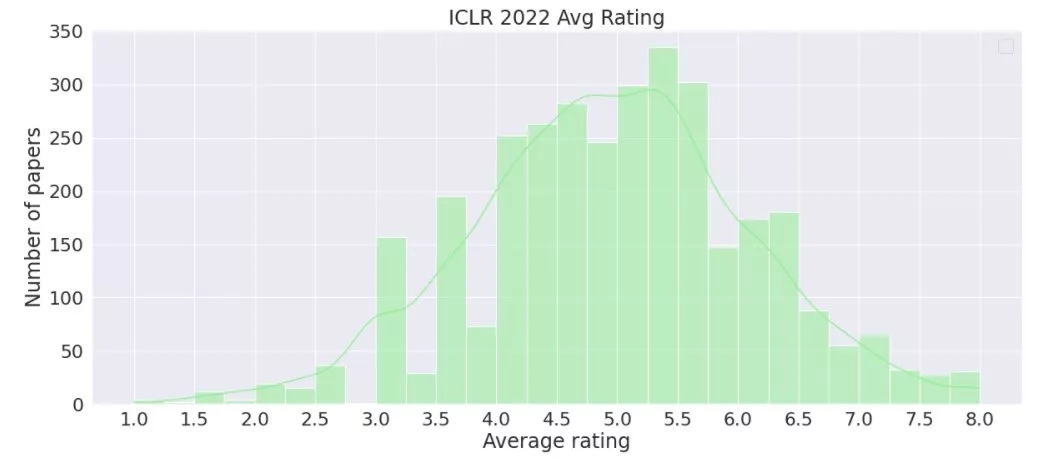
不仅如此,在刚刚结束的机器学习顶会ICLR 2022上,iBOT也杀出一条血路,获得了审稿人的一致认可及[8, 6, 6]的终评分数。
其中,本届大议共收到了3325篇有效投稿,投稿的平均分为4.93(+- 1.15) ,作为对比,ICLR 2021 rebuttal后的平均分为5.37( +- 0.96)。
2021年11月,字节跳动、霍普金斯大学等机构组成的联合团队提出了基于自监督的预训练框架iBOT。
论文链接:https://arxiv.org/abs/2111.07832
此前,大名鼎鼎的GPT和BERT已经将大型NLP模型的性能提升到了一个新的高度。经过海量数据的学习和训练,AI模型生成的自然文本几乎可以乱真。
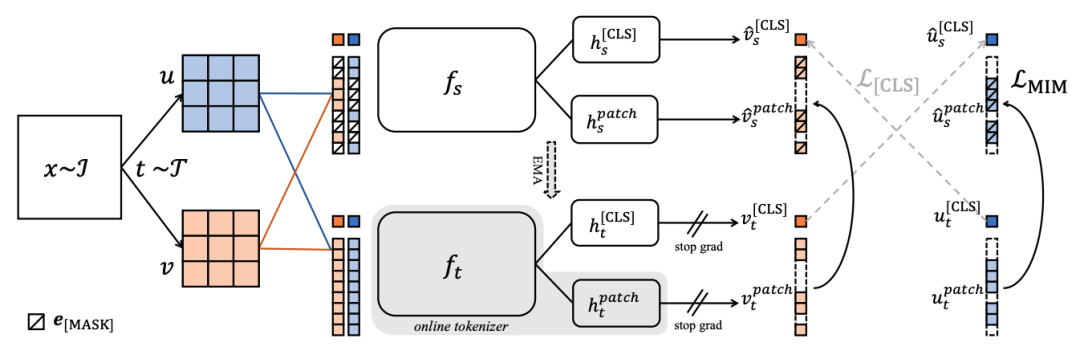
如今,iBOT以自蒸馏的方式进行掩膜图像建模,并通过对图像使用在线tokenizer进行BERT式预训练,让CV模型获得了通用广泛的特征表达能力,并在十几类任务和数据集上刷新了SOTA。
这里作者不仅给出了预训练的代码,还提供了非常完整的、不同设置下的评估代码以及分析模型的代码。
开源项目:https://github.com/bytedance/ibot
在NLP领域,以BERT为首的Masked Language Modeling(MLM)训练方式非常成功。
模型通过学习得到的特征不管是在数据规模,还是模型规模拓展上都非常有效。
在CV领域,基本上就是Transformer的天下了,比如ViT、Swin-T等等。
但几乎所有的成功预训练方法都是通过对比学习来实现的。至少,在目前还不能证明,这种方式具备类似BERT那样在大数据和大模型上的泛化能力。
那么,能不能像自然语言处理中的MLM那样,把Masked Image Modeling(MIM)引入到计算机视觉领域呢?
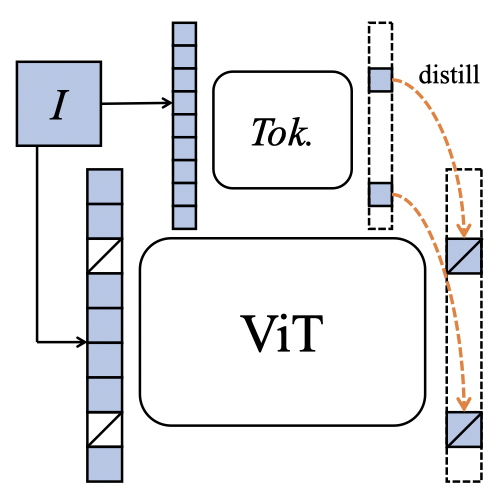
想要做到这一点,首先面对的便是一个核心问题:tokenizer的设计。
文本中的tokenizer可以通过统计的方式直接具备语义特性。
但是对于图片来说却截然不同,如果直接对这些构成的像素进行重建的话,就会捕捉到非常高频的噪声。
而合格的tokenizer则应该具备捕捉高层语义的特性,恰好,这一特性可以利用在线更新来学习。
于是,iBOT把MLM/MIM建模为知识蒸馏(Knowledge Distillation)并以此来建模并实现在线tokenizer。
于是,通过掩码预测和自蒸馏的结合,iBOT除了在主流无监督指标的出色表现之外,也在多个任务公平对比下大幅领先同期工作。
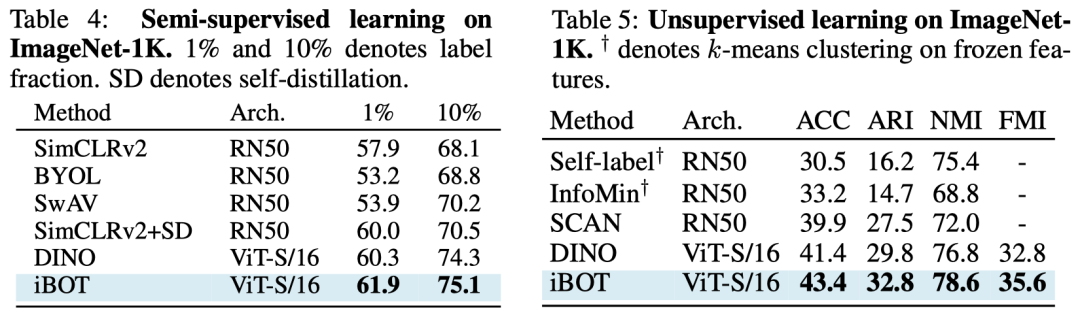
对于无监督分类,iBOT仅使用21M参数量的ViT-S模型可达到32.8的调整兰德指数(ARI)。
在K-NN、线性分类和微调分类下,iBOT使用ViT-B将ImageNet-1K的准确率分别提高到77.1%、79.5%、84.0%,比之前的最佳结果高出1.0%、1.3%和0.4%。
当用ImageNet-22K进行预训练时,使用307M参数量的ViT-L可以实现82.3%的线性分类准确率和87.8%的微调分类准确率,比之前的最佳结果高1.0%和1.8%。
在半监督分类的任务中,论文也一致性地在多个设置下(如线性分类、回归、最近邻匹配、微调等)超越了先前表现出色的DINO。
iBOT使用ViT-S模型在半监督、无监督分类的表现
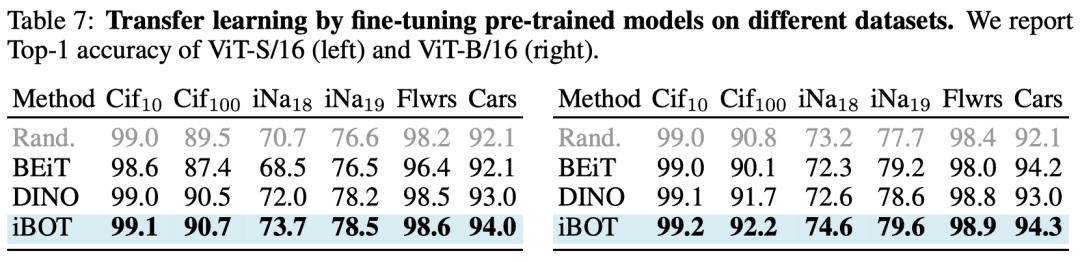
在迁移学习的任务中,论文在多个小数据集(如CIFAR、iNaturelist等)取得了一致的性能提升。
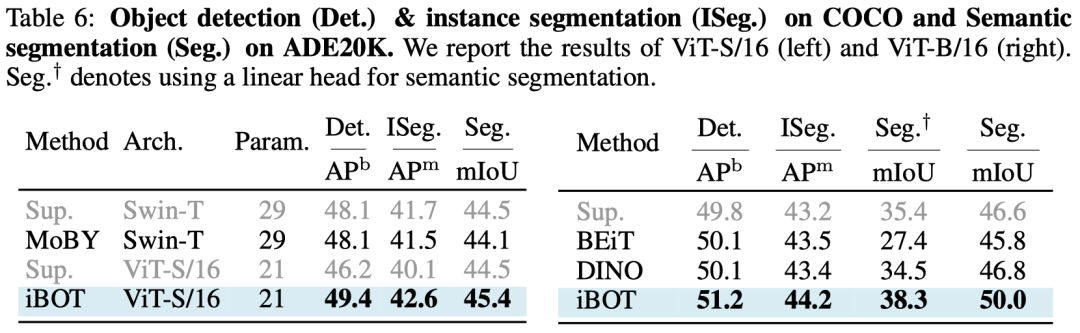
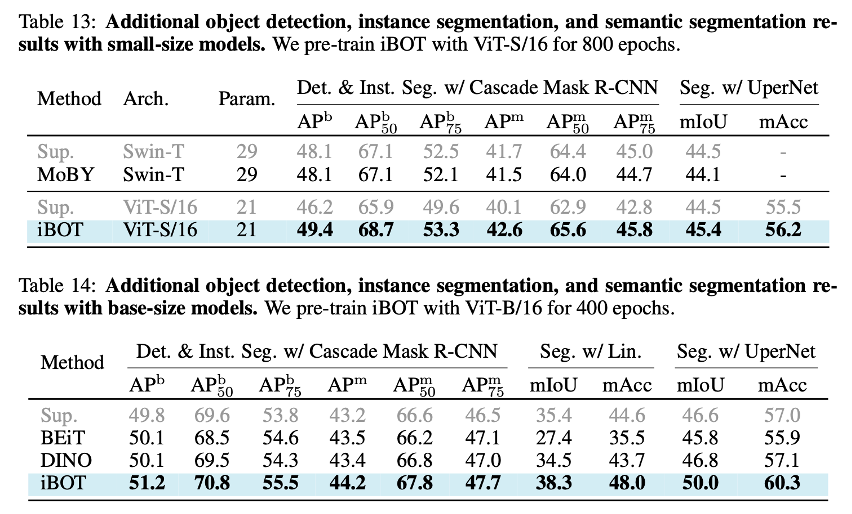
除此之外,作者还集中评测在模型在目标检测、实力分割、语义分割等密集下游任务的表现,而iBOT也领先同期的BEiT、DINO等工作。
使用iBOT初始化的ViT甚至打过了在密集下游任务具有天然优势的Swin Transformer。
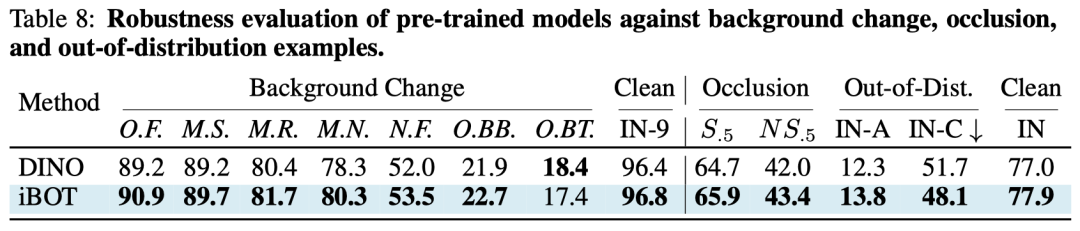
最后,在模型的鲁棒性方面,iBOT也展现出了由掩码预测带来的性能优势。
在CV领域,iBOT可以在海量的图像数据中自动学习结构和知识信息,帮助计算机更好地理解现实世界。
除了iBOT,字节跳动也有在机器翻译领域摘得了ACL 2021唯一一篇最佳论文的「Vocabulary Learning via Optimal Transport for Machine Translation」。
当然了,这些论文和模型可不只是用来刷刷SOTA的,所有的这些算法都会逐步应用于字节跳动各个视频业务、机器翻译、智能硬件、AR/VR等技术领域。
不用猜其实就能想到,抖音里各种特效和配音等等肯定是少不了强大的AI技术来支撑的。而现在,字节跳动在AI领域的积累已经通过旗下的企业级技术服务平台对外提供服务了。
比如最近趁着冬奥的热乎劲儿,人民日报新媒体推出了一个名为「我是冰雪高手」的小程序,就是由火山引擎提供的技术支持。
![]()
操作也很简单,只需上传一张自拍,氛围感就拉满了。在这里,你可以「化身」各路高手,驰骋冰场、雪场。
刚才的这个「帅气的小姐姐」,其实就是小编我本人。![]()
![]()
火山引擎AI以「激发无限创意,提升业务增长」为目标,提供了音视频、直播、AR及特效等多种内容形态下的创作能力。
其中,包含AI底层引擎、AI场景产品和AI行业解决方案的多层次的产品方案,以及API、SDK、PaaS和SaaS等多形式的交付模式,将音视频智能创作灵活和高效地赋能到企业的内部工具或用户产品中,持续为用户体验和业务增长注入创新势能。
随着技术团队的不断突破,相信火山引擎AI的未来也是值得期待的。
参考资料:
https://arxiv.org/abs/2111.07832
https://github.com/bytedance/ibot
https://paperswithcode.com/sota/self-supervised-image-classification-on
https://www.zhihu.com/question/499284656/answer/2227616606
![]()