
Transformer 的跨界之旅还在继续,那么未来有哪些可能的研究思路呢?
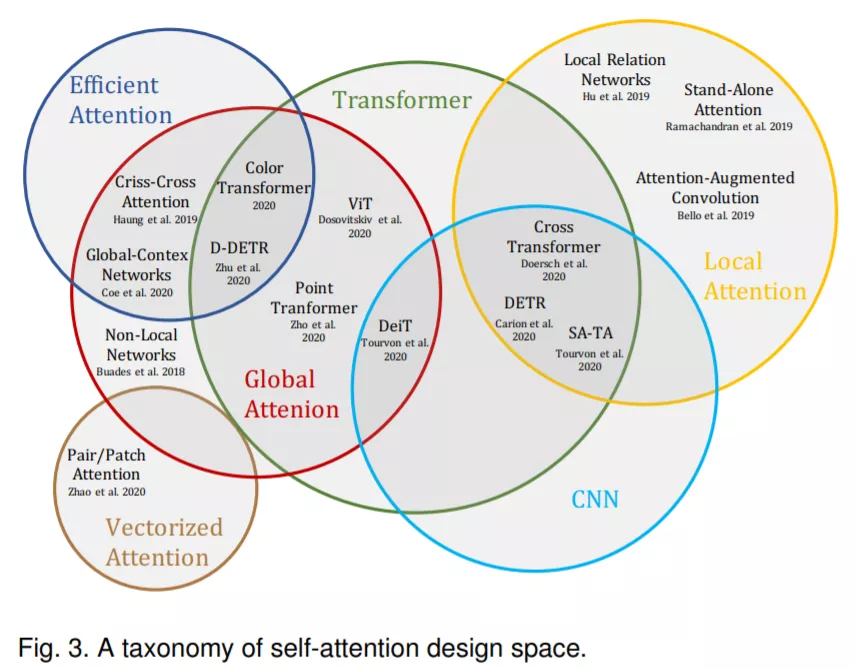
去年 12 月,来自华为诺亚方舟实验室、北京大学、悉尼大学的研究者整理了一份综述,详细归纳了多个视觉方向的 Transformer 模型。
论文链接:https://arxiv.org/pdf/2012.12556.pdf
此外,他们还在论文中初步思考并给出了三个未来的研究方向:
现有的 Visual Transformer 都还是将 NLP 中 Transformer 的结构套到视觉任务做了一些初步探索,未来针对 CV 的特性设计更适配视觉特性的 Transformer 将会带来更好的性能提升。
现有的 Visual Transformer 一般是一个模型做单个任务,近来有一些模型可以单模型做多任务,比如 IPT,未来是否可以有一个世界模型,处理所有任务?
现有的 Visual Transformer 参数量和计算量多大,比如 ViT 需要 18B FLOPs 在 ImageNet 达到 78% 左右 Top1,但是 CNN 模型如 GhostNet 只需 600M FLOPs 可以达到 79% 以上 Top1,所以高效 Transformer for CV 亟需开发以媲美 CNN。(引自 @kai.han)
类似的综述研究还有来自穆罕默德 · 本 · 扎耶德人工智能大学等机构的《Transformers in Vision: A Survey》。
成为VIP会员查看完整内容
相关内容
相关主题

相关VIP内容
相关资讯
相关论文